本篇已收录至redis in action 学习笔记系列
了解基本的搜索原理
通常如果想获取快速的搜索功能, 都需要对数据进行建立
索引. 在互联网上绝大多数的搜索引擎使用的底层结构是叫做一种反向索引结构.
反向索引
比如文章a的名字叫做
Java语言的最佳实践, 文章b的名字叫做Python语言的最佳实践. 那么系统在使用 redis 实现搜索功能时, 会以最佳实践为 key 创建一个 set, 并在集合中包含两篇文章的名字, 以此来表示两篇文章的名字中都包含最佳实践, 这样建立关联关系的方式就叫做反向索引.
为文章建立索引集合
从文章里面提取单词的过程通常被称为
语法分析和标记化, 这个过程可以产生出一系列用于标识文档的标记. 提取标记的方式很多种, 但是大多遵循一个原则就是要移除非用词, 指的是在文档中频繁出现但是不能够提供信息的词, 因为对这些词进行搜索会产生大量无用的结果. 所以移除非用词不仅可以提高搜索效率, 也可以减少索引占用的空间.

下面的代码展示了一段提取文档中的非用词后, 顺便对该文档在redis中建立反向索引的函数:
# <start id="tokenize-and-index"/>
STOP_WORDS = set('''able about across after all almost also am among
an and any are as at be because been but by can cannot could dear did
do does either else ever every for from get got had has have he her
hers him his how however if in into is it its just least let like
likely may me might most must my neither no nor not of off often on
only or other our own rather said say says she should since so some
than that the their them then there these they this tis to too twas us
wants was we were what when where which while who whom why will with
would yet you your'''.split()) #A
WORDS_RE = re.compile("[a-z']{2,}") #B
def tokenize(content):
words = set() #C
for match in WORDS_RE.finditer(content.lower()): #D
word = match.group().strip("'") #E
if len(word) >= 2: #F
words.add(word) #F
return words - STOP_WORDS #G
def index_document(conn, docid, content):
words = tokenize(content) #H
pipeline = conn.pipeline(True)
for word in words: #I
pipeline.sadd('idx:' + word, docid) #I
return len(pipeline.execute()) #J
思考一下, 当文档中的内容发生了变化, 怎么样设计一个功能, 可以使文档对应的反向索引跟随变化, 即增添新的反向索引或者删除无效的反向索引.
实现基本搜索
通过一个单词作为索引找到相关的文档是很容易的, 但是通常实际情况是, 用户输入的单词可能是多个, 那么就需要从多个单词的索引对应的集合中找出同时出现的文档. 我们第一时间想到的可能就是对这些集合取交集运算. 比如 redis 的
sinter和sinterstore命令.
使用交集操作的好处可能不在于找到多少个文档, 或者多快的找出文档, 而是能够彻底的忽略无关的信息. 因为使用文本编辑器的方式进行搜索内容的时候, 很多无关的数据都被仔细的检查了.
实际上搜索的基础实现就是对多个 set 集合根据需要进行交际, 并集以及差集运算得到一个有时效的结果集返回.
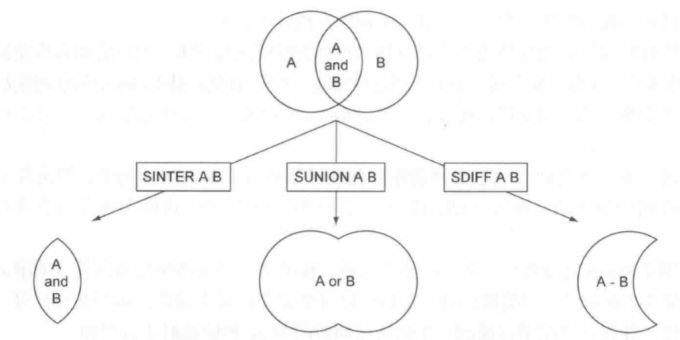
除了将集合进行运算的common 方法以外, 还有关键的一个方法是将用户的搜索语句转义函数
parse_search函数
对搜索出的结果进行排序
这个排序过程有个专用名词叫做
关联度计算判断, 判断一个文章是否比另一个文章更加关联搜索条件.
所以可以将文章 id 为 key, 以及 文章的属性作为 value, 放入散列 hash 中, 用于 sort.
