HDFS文件的系统中,是将文件分为多个block进行存储的,并将存储的block赋值多个副本,存储在不同的主机上,那么HDFS是怎么来维护这些数据的呢,
文件是存储在哪里?
首先,hafs文件系统中,文件是存储在哪里。很多人会说,当然存储在磁盘上,如果真的只是存储存在磁盘上,那么从hdfs中读取文件,将变得非常的缓慢,而hadoop是处理大量的数据,这就会使存储与读取的速度更加的缓慢,hadoop中有很多超时机制,一旦超过一定时间,将会抛出异常,重新连接,这样使整体的性能变得非常差,那么将数据存在内存中,这样一来,速度是变得非常快,但是不能保证数据的安全性,一旦出现故障,例如断电,那么数据都将会消失。
Hadoop的hdfs文件系统是将上面的两种方式同时运用起来。具体的原理如图:
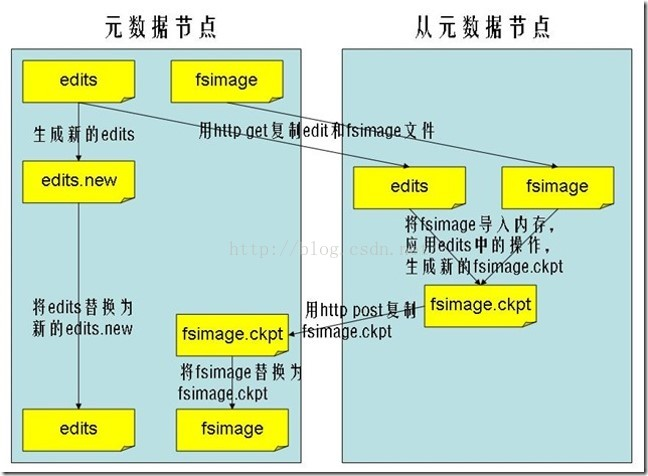
其中:NameNodel是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
① fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
② edits:操作日志文件。
③ fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
Namenode 始终在内存中保存 metedata ,用于处理“读请求”,当有“写请求”到来时, namenode 会首先写 editlog 到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回 Hadoop 会维护一个 fsimage 文件,也就是 namenode 中 metedata 的镜像,但是 fsimage 不会随时与 namenode 内存中的 metedata 保持一致,而是每隔一段时间通过合并 edit s文件来更新内容。 Secondary namenode 就是用来合并 fsimage 和edits文件来更新NameNode的 metedata 的,由于这种合并是花费CPU时间与内存,因此SecondaryNameNode一般会在一个单独的物理计算机上运行。
NameNode维护的两个文件,一个fsimage,一个是edits,当客户端对datanode的数据进行增删改时,会将这些修改的日志信息存放在edits中,由于NameNode只是在启动的时候才会将fsimage与edits中的内容,合并,这样会导致edits将变的越来越大,而editors变的越来越大也将会时NameNode的下一次启动花费很长的时间。所以Hadoop中引入了SecondaryNameNode。SecondaryNameNode是定期的合并fsimage与editors内容,一边editors不会过大。
(2)client对数据进行操作时,eidtors会将这些操作记录下来,
(3)当触发了checkpoint时,secondarynamenode就会通知namenode重新启用一个editors.new记录操作日志,而原来的editors与fsimage将会下载到secondarynamenode中并进行合并。
(4)secondarynamenode将合并的fsimage返回到给namenode
(5)namenode用新的fsimage替代旧的fsimage
1 为什么需要SecondaryNameNode
SecondaryNameNode 一般是起着辅助作用,上面NameNode维护的文件元数据,这些元数据是被持久化到两个文件中,一个是fsimage,一个是editorlog,当NameNode启动后,会合并fsimage与eiditslog的信息,并加载到内存中,在Namenode启动后所有对目录结构的增加,删除,修改等操作都会记录到edits文件中,并不会同步的记录在fsimage中。而当Namenode结点关闭的时候,也不会将fsimage与edits文件进行合并,这个合并的过程实际上是发生在Namenode启动的过程中。但是,在NameNode应该时刻保持着最新的元数据信息,这样才能保证客户端能够正确的操作的数据。那么hdfs是怎么时刻的更新namenode的元数据的?NameNode维护的两个文件,一个fsimage,一个是edits,当客户端对datanode的数据进行增删改时,会将这些修改的日志信息存放在edits中,由于NameNode只是在启动的时候才会将fsimage与edits中的内容,合并,这样会导致edits将变的越来越大,而editors变的越来越大也将会时NameNode的下一次启动花费很长的时间。所以Hadoop中引入了SecondaryNameNode。SecondaryNameNode是定期的合并fsimage与editors内容,一边editors不会过大。
2 什么是checkpoint?
CheckPoint就是一个检查点,上面提到SecondaryNameNode会将fsimage与editors合并,那么什么时候合并呢,这就是checkpoint的作用。checkpoint的触发机制有两种:(1)以时间为标准进行checkpoint,fs.checkpoint.period 指定两次 checkpoint 的最大时间间隔,默认 3600 秒。
(2)以eidtors的容量是否满为标准。 fs.checkpoint.size 规定 edits 文件的最大值,一旦超过这个值则强制 checkpoint ,不管是否到达最大时间间隔。默认大小是 64M 。
注意:上面两种方式,在一个checkpiont只有一个触发。3 HDFS维护数据的机制
(1)NameNode启动的时候,会将fsimage与editors合并,并加载到namenode中,并且此时,各个datanode会想namenode上传block块位置等信息(2)client对数据进行操作时,eidtors会将这些操作记录下来,
(3)当触发了checkpoint时,secondarynamenode就会通知namenode重新启用一个editors.new记录操作日志,而原来的editors与fsimage将会下载到secondarynamenode中并进行合并。
(4)secondarynamenode将合并的fsimage返回到给namenode
(5)namenode用新的fsimage替代旧的fsimage
转载于:https://blog.csdn.net/yrlailh/article/details/50992226?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_v2~rank_aggregation-6-50992226.pc_agg_rank_aggregation&utm_term=hadoop%E6%80%8E%E4%B9%88%E5%AD%98%E5%82%A8%E6%95%B0%E6%8D%AE&spm=1000.2123.3001.4430