Hello,各位小伙伴大家好,我是小栈君,今天给大家带来的分享是关于关于二叉树相关的知识点,并用go语言实现一个二叉树和对二叉树进行遍历。
我们主要针对二叉树的概念,go实战实现二叉树的前序遍历、中序遍历、后序遍历。
二叉树概念
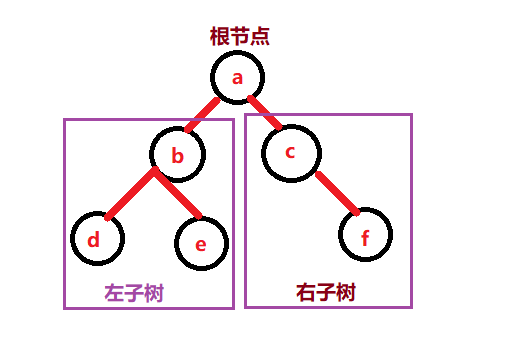
在计算机科学领域内,二叉树代表的是具有两个节点的树形结构,通常子树被称作为“左子树”,右边的被称作为“右子树”。二叉树通常的应用于实现二叉查找树和二叉堆。
例如上述图片中,我们就制定了一个二叉树,其中d、e、f称作a树的叶子节点。
[叶子结点是离散数学中的概念。一棵树当中没有子结点(即度为0)的结点称为叶子结点,简称“叶子”。 叶子是指出度为0的结点,又称为终端结点]
b和c 作为树a的孩子结点,b和a因为作为一个根a的孩子,所以他们的称呼为兄弟结点。其实总结一点就是关于二叉树各个结点的称呼其实和我们在家庭中,对于各个亲戚长辈的称呼类似。
在百度百科中也归纳除了关于二叉树的分类
一棵深度为k,且有2^k-1个结点的二叉树,称为满二叉树。这种树的特点是每一层上的结点数都是最大结点数。而在一棵二叉树中,除最后一层外,若其余层都是满的,并且或者最后一层是满的,或者是在右边缺少连续若干结点,则此二叉树为完全二叉树。
具有n个结点的完全二叉树的深度为floor(log2n)+1。深度为k的完全二叉树,至少有2k-1个叶子结点,至多有2k-1个结点。
所以通过我们上面的理论基础,我们结合代码来实现一下我们的二叉树结构。

如图所示 ,我们定义了一个树treeNode的结构体,关于结构体的分享,小栈君会在下一期对大家进行分享。对于go语言专题分享已经过了差不多三分之一,接下来我们会开启新的分享之旅,还请各位持续关注“IT干货栈”。
闲话不多说,我们在结构体中定义了三个参数,一个是树的名称,一个是树的左节点和右节点。请各位小伙伴注意哦,这里的用的是指针,因为在go语言中如果说不用引用传递,在后续添加节点后是没有任何效果的,下面我会给大家进行演示一下。
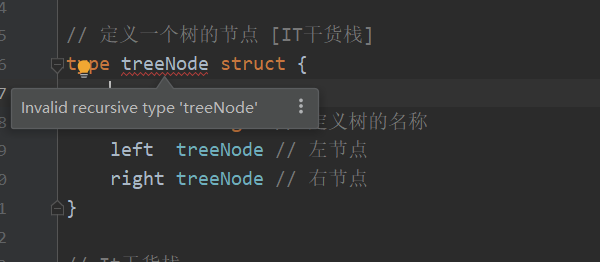
当我们将节点定义为不是引用类型的时候,直接编译器都通不过,报了一个无效的递归类型的错误。
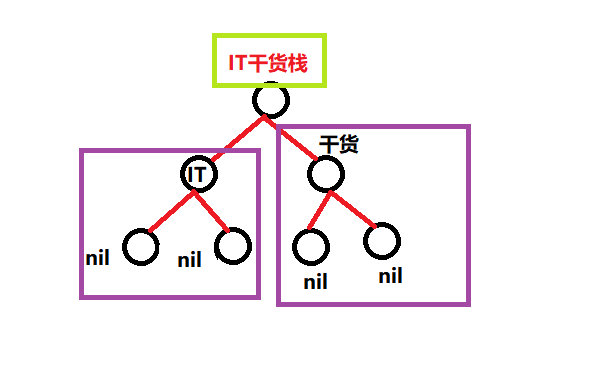
所以我们先初始化一个根节点名称为“It干货栈”的节点,然后左节点名称为It ,右节点为干货。两个子节点就都没有左右节点。为了后续二叉树的遍历提供更多的数据,我们将增加方法进行追加树的节点。
// 定义一个树的节点 [IT干货栈]
type treeNode struct {
name string // 定义树的名称
left *treeNode // 左节点
right *treeNode // 右节点
}
// It干货栈
func main() {
var node = treeNode{name: "It干货栈", left: &treeNode{name: "It", left: nil}, right: &treeNode{name: "干货"}}
addLeftNode(&node, 2)
addLeftNode(node.left, 3)
addLeftNode(node.left.left, 4)
addLeftNode(node.left.left.left, 5)
node.addRightNode(2)
node.right.addRightNode(3)
node.right.right.addRightNode(4)
node.right.right.right.addRightNode(5)
fmt.Println(node)
}
// 增加二叉树左节点
func addLeftNode(node *treeNode, value int) {
children := treeNode{name: fmt.Sprintf("子节点%s%d", "It干货栈", value)}
node.left = &children
}
// 增加二叉树右节点
func (node *treeNode) addRightNode(value int) {
children := treeNode{
name: fmt.Sprint("关注公众号", value),
left: nil,
right: nil,
}
node.right = &children
}
以上代码我们我们定义了一个树节点,并且增加了相关的增加的节点的方法,细心的小伙伴可能已经看出来了,我们增加左节点和增加右节点的方法并不相同,那是因为在go语言中我们不仅可以写通用方法,比如增加二叉树左节点addLeftNode 方法。
我们还可以指定仅为treeNode专属方法addRightNode。
我们在添加了很多节点后,如果是采用传统的print打印出来的结果,如下图所示
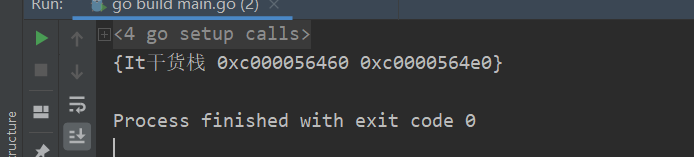
所以接下来小栈君将为大家分享关于二叉树的前序、中序、后序遍历。
二叉树遍历
遍历是对树的一种最基本的运算,所谓遍历二叉树,就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。由于二叉树是非线性结构,因此,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。
前序遍历
二叉树的前序遍历,又称为先序遍历。在二叉树的前序的顺序,首先访问根,再先序遍历左(右)子树,最后先序遍历右(左)子树。
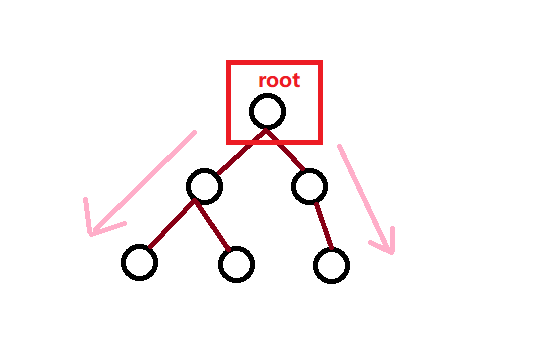
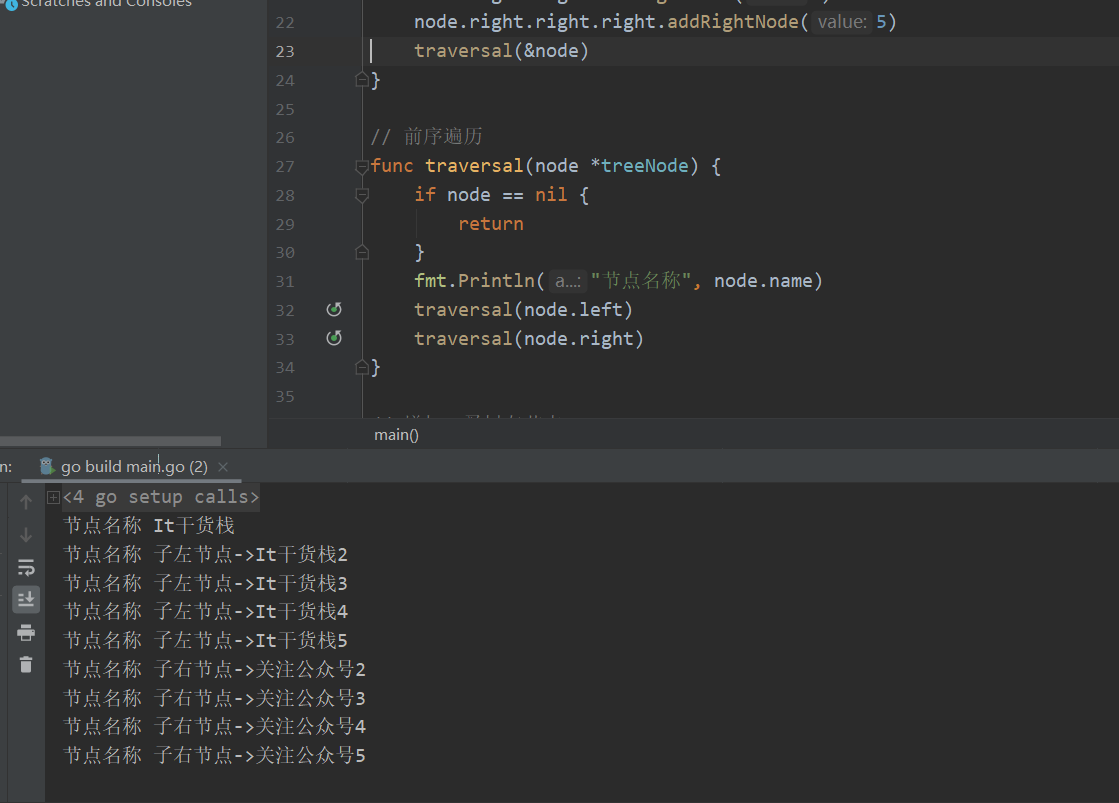
是不是很简单的代码就完成了我们关于二叉树的前序遍历。先访问根节点,然后依次遍历右节点和左节点,当然我们也可以交换顺序进行先遍历左节点在继续遍历右节点。
中序遍历
关于go语言中序遍历的顺序,首先中序遍历左(右)子树,再访问根,最后中序遍历右(左)子树。
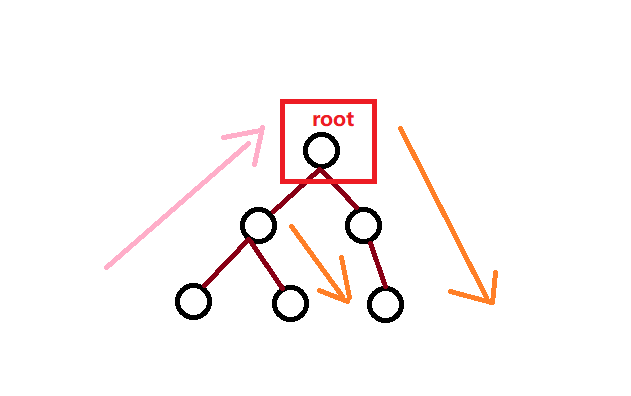
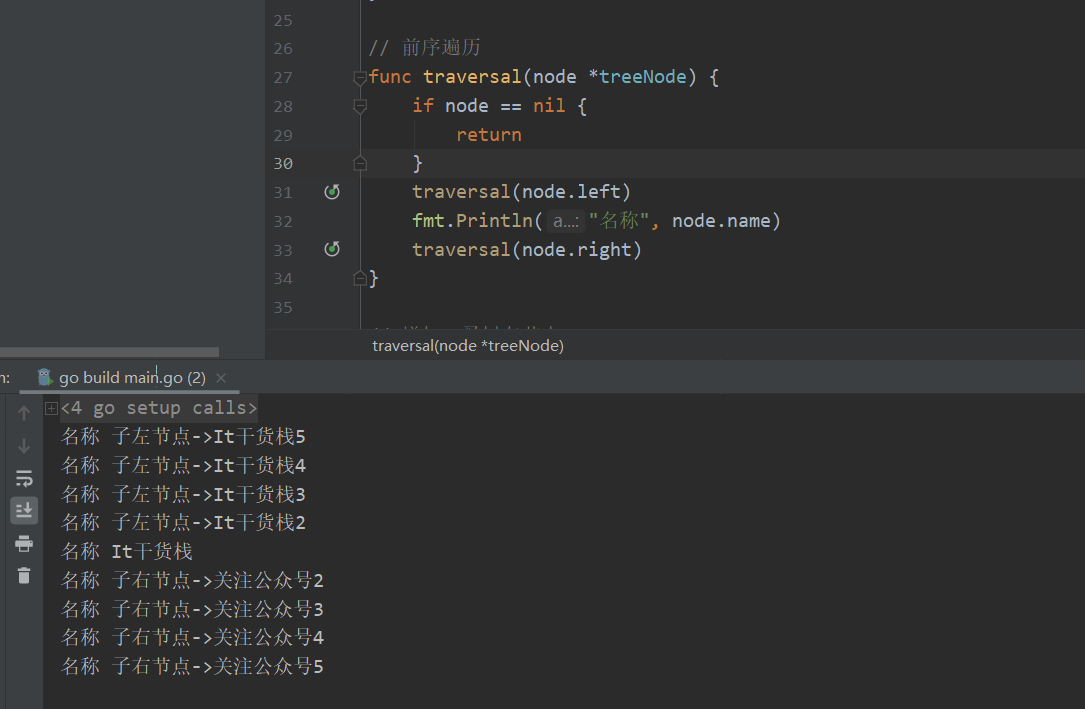
后序遍历
go语言的后序遍历顺序是首先后序遍历左(右)子树,再后序遍历右(左)子树,最后访问根。那么他的顺序就应该如图所示:
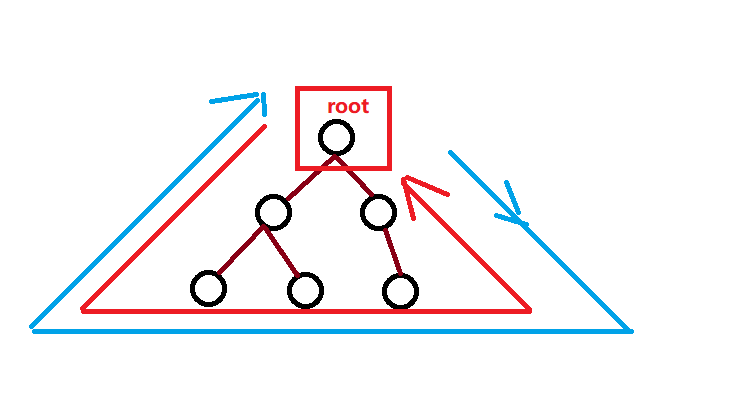
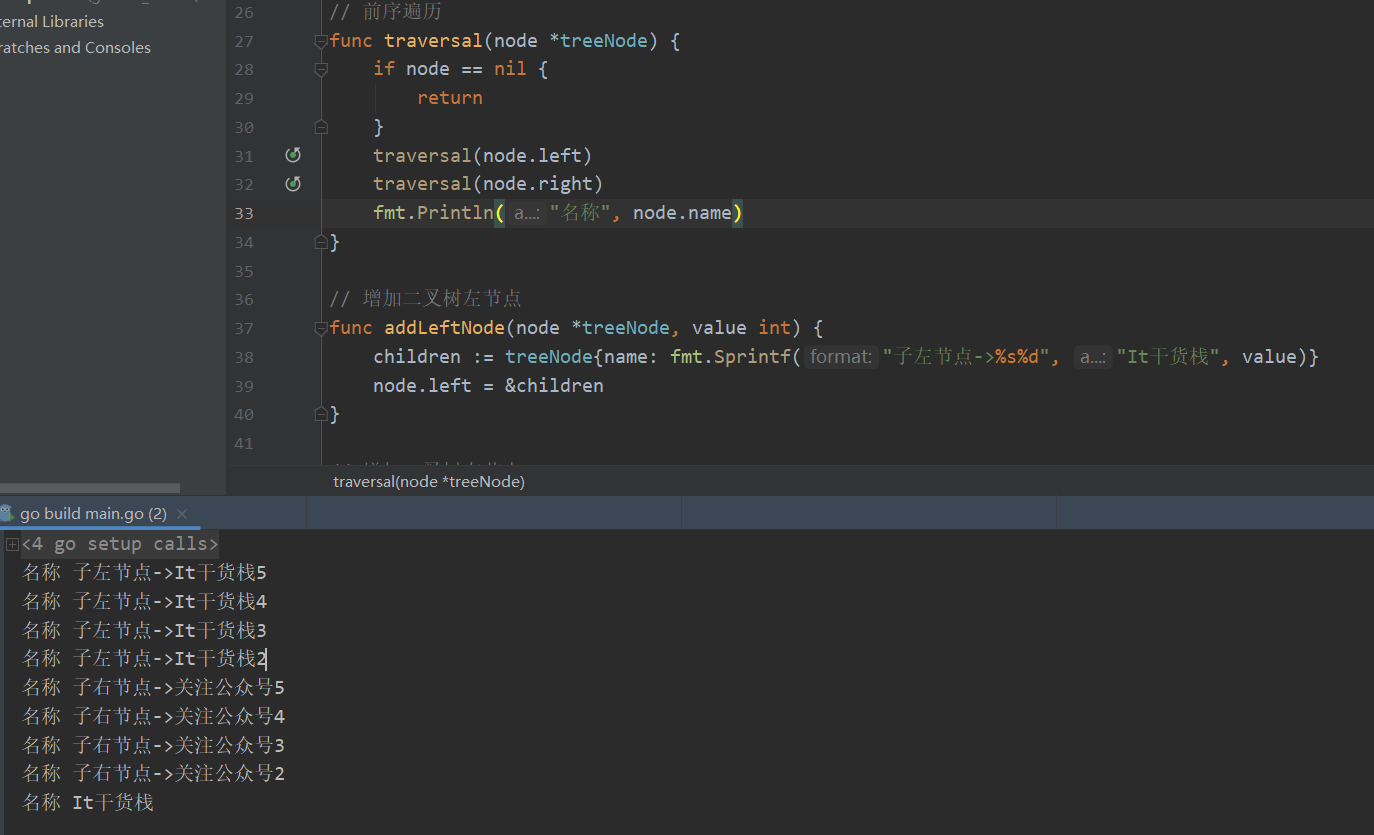
以上就是关于二叉树的遍历的分享,关于二叉树的讲解我们就到这里,对于先序遍历,中序遍历,后续遍历,其实其实也就是遍历的顺序不同而已,接下来就附上当前测试用例的代码。
// 定义一个树的节点 [IT干货栈]
type treeNode struct {
name string // 定义树的名称
left *treeNode // 左节点
right *treeNode // 右节点l
}
// It干货栈
func main() {
var node = treeNode{name: "It干货栈", left: &treeNode{name: "It", left: nil}, right: &treeNode{name: "干货"}}
addLeftNode(&node, 2)
addLeftNode(node.left, 3)
addLeftNode(node.left.left, 4)
addLeftNode(node.left.left.left, 5)
node.addRightNode(2)
node.right.addRightNode(3)
node.right.right.addRightNode(4)
node.right.right.right.addRightNode(5)
traversal(&node)
}
// 遍历
func traversal(node *treeNode) {
if node == nil {
return
}
traversal(node.left)
traversal(node.right)
fmt.Println("名称", node.name)
}
// 增加二叉树左节点
func addLeftNode(node *treeNode, value int) {
children := treeNode{name: fmt.Sprintf("子左节点->%s%d", "It干货栈", value)}
node.left = &children
}
// 增加二叉树右节点
func (node *treeNode) addRightNode(value int) {
children := treeNode{
name: fmt.Sprint("子右节点->关注公众号", value),
left: nil,
right: nil,
}
node.right = &children
}
以上就是今天的分享了,如果你喜欢我的分享麻烦分享、转发或点击好看,我们下期再见,我是小栈君,拜了个拜~