在工作中,前端代码打包之后的生成的静态资源就要发布到静态服务器上,这时候就要做对这些静态资源做一些运维配置,其中,gzip和设置缓存是必不可少的。这两项是最直接影响到网站性能和用户体验的。
缓存的优点:
- 减少了不必要的数据传输,节省带宽
- 减少服务器的负担,提升网站性能
- 加快了客户端加载网页的速度
- 用户体验友好
缺点:
- 资源如果有更改但是客户端不及时更新会造成用户获取信息滞后,如果老版本有bug的话,情况会更加糟糕。
所以,为了避免设置缓存错误,掌握缓存的原理对于我们工作中去更加合理的配置缓存是非常重要的。
一、强缓存
到底什么是强缓存?强在哪?其实强是强制的意思。当浏览器去请求某个文件的时候,服务端就在respone header里面对该文件做了缓存配置。缓存的时间、缓存类型都由服务端控制,具体表现为:
respone header 的cache-control,常见的设置是max-age public private no-cache no-store等
如下图,
设置了cache-control:max-age=31536000,public,immutable
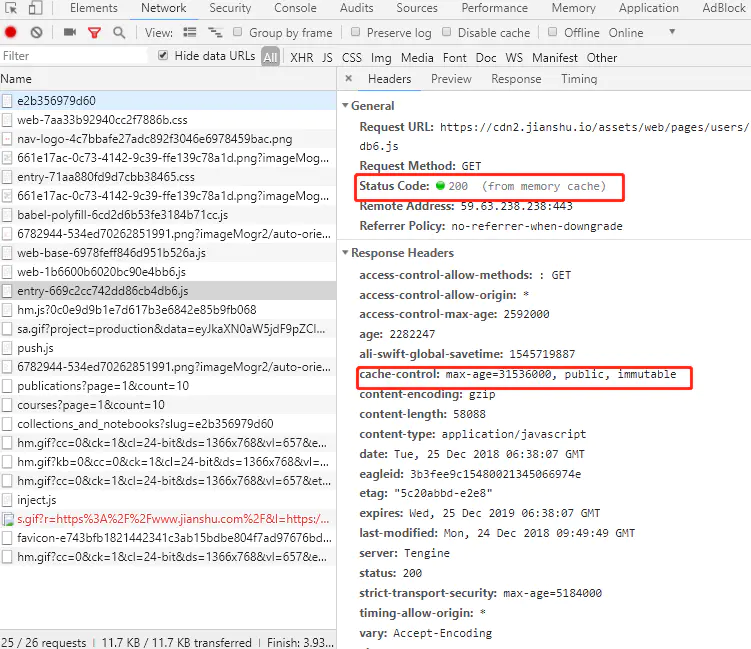
max-age表示缓存的时间是31536000秒(1年),public表示可以被浏览器和代理服务器缓存,代理服务器一般可用nginx来做。immutable表示该资源永远不变,但是实际上该资源并不是永远不变,它这么设置的意思是为了让用户在刷新页面的时候不要去请求服务器!啥意思?就是说,如果你只设置了cahe-control:max-age=31536000,public 这属于强缓存,每次用户正常打开这个页面,浏览器会判断缓存是否过期,没有过期就从缓存中读取数据;但是有一些 "聪明" 的用户会点击浏览器左上角的刷新按钮去刷新页面,这时候就算资源没有过期(1年没这么快过),浏览器也会直接去请求服务器,这就是额外的请求消耗了,这时候就相当于是走协商缓存的流程了(下面会讲到)。如果cahe-control:max-age=315360000,public再加个immutable的话,就算用户刷新页面,浏览器也不会发起请求去服务,浏览器会直接从本地磁盘或者内存中读取缓存并返回200状态,看上图的红色框(from memory cache)。这是2015年facebook团队向制定 HTTP 标准的 IETF 工作组提到的建议:他们希望 HTTP 协议能给 Cache-Control 响应头增加一个属性字段表明该资源永不过期,浏览器就没必要再为这些资源发送条件请求了。
强缓存总结
-
cache-control: max-age=xxxx,public
客户端和代理服务器都可以缓存该资源;
客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,如果用户做了刷新操作,就向服务器发起http请求 -
cache-control: max-age=xxxx,private
只让客户端可以缓存该资源;代理服务器不缓存
客户端在xxx秒内直接读取缓存,statu code:200 -
cache-control: max-age=xxxx,immutable
客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,即使用户做了刷新操作,也不向服务器发起http请求 -
cache-control: no-cache
跳过设置强缓存,但是不妨碍设置协商缓存;一般如果你做了强缓存,只有在强缓存失效了才走协商缓存的,设置了no-cache就不会走强缓存了,每次请求都回询问服务端。 -
cache-control: no-store
不缓存,这个会让客户端、服务器都不缓存,也就没有所谓的强缓存、协商缓存了。
二、协商缓存
上面说到的强缓存就是给资源设置个过期时间,客户端每次请求资源时都会看是否过期;只有在过期才会去询问服务器。所以,强缓存就是为了给客户端自给自足用的。而当某天,客户端请求该资源时发现其过期了,这是就会去请求服务器了,而这时候去请求服务器的这过程就可以设置协商缓存。这时候,协商缓存就是需要客户端和服务器两端进行交互的。
怎么设置协商缓存?
response header里面的设置
etag: '5c20abbd-e2e8' last-modified: Mon, 24 Dec 2018 09:49:49 GMT
etag:每个文件有一个,改动文件了就变了,就是个文件hash,每个文件唯一,就像用webpack打包的时候,每个资源都会有这个东西,如: app.js打包后变为 app.c20abbde.js,加个唯一hash,也是为了解决缓存问题。
last-modified:文件的修改时间,精确到秒
也就是说,每次请求返回来 response header 中的 etag和 last-modified,在下次请求时在 request header 就把这两个带上,服务端把你带过来的标识进行对比,然后判断资源是否更改了,如果更改就直接返回新的资源,和更新对应的response header的标识etag、last-modified。如果资源没有变,那就不变etag、last-modified,这时候对客户端来说,每次请求都是要进行协商缓存了,即:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否真的过期-->没过期-->返回304状态码-->客户端用缓存的老资源。
这就是一条完整的协商缓存的过程。
当然,当服务端发现资源真的过期的时候,会走如下流程:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否真的过期-->过期-->返回200状态码-->客户端如第一次接收该资源一样,记下它的cache-control中的max-age、etag、last-modified等。
所以协商缓存步骤总结:
请求资源时,把用户本地该资源的 etag 同时带到服务端,服务端和最新资源做对比。
如果资源没更改,返回304,浏览器读取本地缓存。
如果资源有更改,返回200,返回最新的资源。
补充一点,response header中的etag、last-modified在客户端重新向服务端发起请求时,会在request header中换个key名:
// response header etag: '5c20abbd-e2e8' last-modified: Mon, 24 Dec 2018 09:49:49 GMT // request header 变为 if-none-matched: '5c20abbd-e2e8' if-modified-since: Mon, 24 Dec 2018 09:49:49 GMT
为什么要有etag?
你可能会觉得使用last-modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要etag呢?HTTP1.1中etag的出现(也就是说,etag是新增的,为了解决之前只有If-Modified的缺点)主要是为了解决几个last-modified比较难解决的问题:
-
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新get;
-
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),if-modified-since能检查到的粒度是秒级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
- 某些服务器不能精确的得到文件的最后修改时间。
怎么设置强缓存与协商缓存
- 后端服务器如nodejs:
res.setHeader('max-age': '3600 public')
res.setHeader(etag: '5c20abbd-e2e8')
res.setHeader('last-modified': Mon, 24 Dec 2018 09:49:49 GMT) -
nginx配置

偶尔自己折腾一番非前端的东西时,若心中有数,自然不会手忙脚乱。
怎么去用?
举个例子,像目前用vue-cli打包后生成的单页文件是有一个html,与及一堆js css img资源,怎么去设置这些文件呢,核心需求是
- 要有缓存,毋庸置疑
-
当发新包的时候,要避免加载老的缓存资源
 打包好的静态文件
打包好的静态文件
我的做法是:
index.html文件采用协商缓存,理由就是要用户每次请求index.html不拿浏览器缓存,直接请求服务器,这样就保证资源更新了,用户能马上访问到新资源,如果服务端返回304,这时候再拿浏览器的缓存的index.html,切记不要设置强缓存!!!
其他资源采用强缓存 + 协商缓存,理由就不多说了。
作者:_小_七_
链接:https://www.jianshu.com/p/9c95db596df5
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。