##最常用来解决这个问题的是八叉树和KD树
但我们在讲这些之前要先了解二叉树,毕竟二叉树是这些的基础。
先讲以下两种方法
· K-NN
就是直接找三个最近的点,三个。
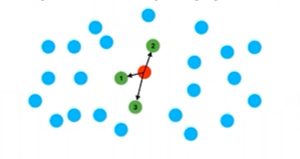
红色的点就是我们要查找的点,绿色和蓝色的点就是我们数据库里的点,而绿色的点是我们所找到的邻近点。
· Fixed Radius-NN
在中心点红点以某半径画一个圈,在圈内的点都算邻近点。
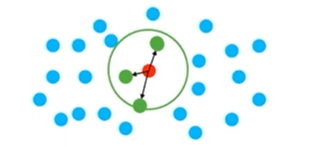
思考:为什么找邻域问题很重要?
因为我们常要用到,在之前讲到的法向量估计中也需要用到找邻域,上采样和降采样或者噪声去除我们都会用到NN方法。
既然重要,一定有很多开源的方法和包(PCL,flann等)。但是很遗憾,他们都不够快。如果自己写,大概率会比较快。
现在GPU都已经满大街了,但是在GPU上面的最邻近算法很少也很慢。
(GPU云服务器是基于异构计算提供的超强的浮点计算能力服务,适用于深度学习,智能视频分析,医疗影像分析,语音识别,高性能计算等应用场景。
用户可根据自身需求灵活搭配。让您即刻拥有非凡的计算能力。)
思考:为什么在点云上的邻域问题很困难呢?
第一个原因就是点云不规则
第二个原因是点云可以是三维的,三维比二维高一维,但是三维的数据点是指数上升的。用网格处理并不是很高效。
##二叉树
用于处理一维的数据
##八叉树
专门为了三维数据设计的
##KD树
可以任意维度,但是常用于二维来做例子
以上三点都有一个共同的核心思想:空间分割
空间分割:
分割完以后有一些小的空间不需要去查找,那此时如何跳过这些小区域呢?
如何更快地结束搜索?
二叉树
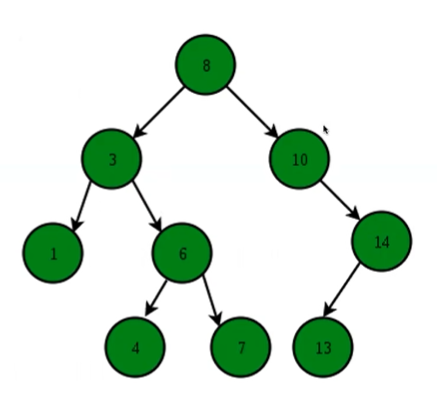
要满足左边的数字都比核心主干的数字小(在图中的核心主干数字是8)
右边要比中间的大
左边和右边又是一个小的二叉树
在计算机科学的开端就发明了(1960)
那么如何用代码实现二叉树呢?

结合上上图,每一个圈就是一个节点,每一个节点都有一个key,用来表达key的特征
左边的节点和右边的节点有还是无
value是别的因素,例如节点的颜色和编号
首先搞定一个问题,首先给定我们一堆的数字,也就是一维数组
怎么构建二叉树来表达我们的信息?
现在假设我们有一个一维数组【100, 20, 500, 10, 30, 40】
首先放100
总结起来,怎么把一个数据放到二叉树里面呢?如果被占据就跟被占据的那个数比较
转换成代码就是如下:

##给定一个数据点,怎么去查找这个数据点是否存在于二叉树里面?
查找可以用递归或者循环
以下代码是用递归查找
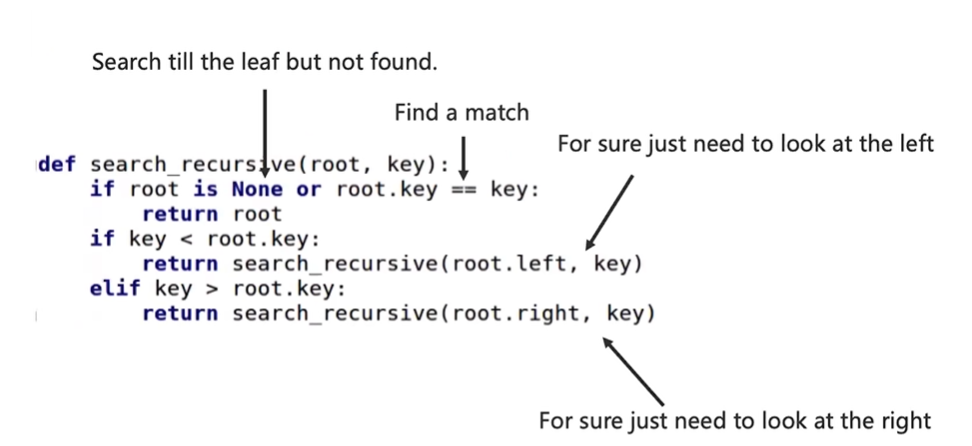
那么怎么用循环去实现呢?
首先要了解 堆栈 的概念,如果要避免递归问题,就要手动去实现一个栈。

递归的好处:实现起来更容易和更理解,不用手动维护查到哪里了
坏处:不停压栈,在内存的某些地方记录了,有多少层就要放多少层栈的信息
循环的话,用一个变量来代表我现在在什么地方。
它可以用在GPU上面。