1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @Time : 2019-08-16 12:40 4 # @Author : Anthony 5 # @Email : ianghont7@163.com 6 # @File : 爬取链家任意城市二手房数据.py 7 8 9 import requests 10 from lxml import etree 11 import time 12 import xlrd 13 import os 14 import xlwt 15 from xlutils.copy import copy 16 17 # 伪装请求 18 headers = { 19 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 BIDUBrowser/8.7 Safari/537.36' 20 } 21 22 xlsInfo = {} 23 24 def catchHouseDetail(url): 25 # 通过requests模块模拟get请求 26 page_text = requests.get(url, headers=headers, stream=True) 27 28 # 将互联网上获取的页面数据加载到etree对象中 29 tree = etree.HTML(page_text.text) 30 31 # 定位页面标签位置装入一个list中 32 li_list = tree.xpath('//div[@class="leftContent"]/ul/li') 33 all_house_list = [] 34 # 遍历列表中每一个字段 35 for li in li_list: 36 info = [] 37 # info = {} 38 # info["房屋标题"] = li.xpath('.//div[@class="info clear"]/div[@class="title"]/a/text()')[0] 39 # info["小区名称"] = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[1] 40 # info['建筑面积'] = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[2] 41 # info['房屋朝向'] = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[3] 42 # info['装修情况'] = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[4] 43 # info['所在楼层'] = li.xpath('.//div[@class="flood"]/div[@class="positionInfo"]/text()')[0].split(' ')[0] 44 # info['所在区域'] = li.xpath('.//div[@class="flood"]/div[@class="positionInfo"]/a/text()')[0] 45 # info['总价'] = li.xpath('.//div[@class="priceInfo"]/div[@class="totalPrice"]/span/text()')[0] + '万' 46 # info['每平米售价'] = li.xpath('.//div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()')[0] 47 # info['房屋关注人数'] = li.xpath('.//div[@class="followInfo"]/text()')[0].split('/')[0] 48 # info['房屋发布时间'] = li.xpath('.//div[@class="followInfo"]/text()')[0].split('/')[1] 49 50 #房屋标题 51 houseTitle = li.xpath('.//div[@class="info clear"]/div[@class="title"]/a/text()')[0] 52 #小区名称 53 houseName = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[1] 54 #建筑面积 55 houseArea = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[2] 56 #房屋朝向 57 houseTowards = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[3] 58 #装修情况 59 houseFinish = li.xpath('.//div[@class="address"]/div[@class="houseInfo"]/text()')[0].split('|')[4] 60 #所在楼层 61 houseFloor = li.xpath('.//div[@class="flood"]/div[@class="positionInfo"]/text()')[0].split(' ')[0] 62 #所在区域 63 houseSite = li.xpath('.//div[@class="flood"]/div[@class="positionInfo"]/a/text()')[0] 64 #总价 65 housePrices = li.xpath('.//div[@class="priceInfo"]/div[@class="totalPrice"]/span/text()')[0] + '万' 66 #每平米售价 67 houseSquarePrices = li.xpath('.//div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()')[0] 68 #房屋关注人数 69 houseFollowers = li.xpath('.//div[@class="followInfo"]/text()')[0].split('/')[0] 70 #房屋发布时间 71 houseTime = li.xpath('.//div[@class="followInfo"]/text()')[0].split('/')[1] 72 info.append(houseTitle) 73 info.append(houseName) 74 info.append(houseArea) 75 info.append(houseTowards) 76 info.append(houseFinish) 77 info.append(houseFloor) 78 info.append(houseSite) 79 info.append(housePrices) 80 info.append(houseSquarePrices) 81 info.append(houseFollowers) 82 info.append(houseTime) 83 all_house_list.append(info) 84 if if_xls_exits() == True: 85 write_excel_xls_append(xlsInfo["xlsName"],all_house_list) 86 87 88 #获取数据写入xls表格中 89 def write_excel_xls(path, sheet_name, value): 90 index = len(value) # 获取需要写入数据的行数 91 workbook = xlwt.Workbook() # 新建一个工作簿 92 sheet = workbook.add_sheet(sheet_name) # 在工作簿中新建一个表格 93 for i in range(0, index): 94 for j in range(0, len(value[i])): 95 sheet.write(i, j, value[i][j]) # 像表格中写入数据(对应的行和列) 96 workbook.save(path) # 保存工作簿 97 print("xls格式表格写入数据成功!") 98 99 100 101 def write_excel_xls_append(path, value): 102 index = len(value) # 获取需要写入数据的行数 103 workbook = xlrd.open_workbook(path) # 打开工作簿 104 sheets = workbook.sheet_names() # 获取工作簿中的所有表格 105 worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格 106 rows_old = worksheet.nrows # 获取表格中已存在的数据的行数 107 new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象 108 new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格 109 for i in range(0, index): 110 for j in range(0, len(value[i])): 111 new_worksheet.write(i + rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入 112 new_workbook.save(path) # 保存工作簿 113 print("xls格式表格【追加】写入数据成功!") 114 115 116 117 118 def if_xls_exits(): 119 while True: 120 book_name_xls = '天津链家二手房信息表.xls' 121 sheet_name_xls = '房屋信息' 122 value_title = [["房屋标题", "房屋户型", "建筑面积", "房屋朝向", "装修情况", "所在楼层", "所在区域", "总价", "每平米售价", "房屋关注人数", "房屋发布时间"], ] 123 if os.path.exists('./%s'%book_name_xls): 124 xlsInfo["xlsName"] = book_name_xls 125 return True 126 else: 127 write_excel_xls(book_name_xls, sheet_name_xls, value_title) 128 continue 129 130 131 132 def catch(): 133 pages = ['https://tj.lianjia.com/ershoufang/pg{}/'.format(x) for x in range(1, 1000)] 134 for page in pages: 135 try: 136 info = catchHouseDetail(page) 137 except: 138 pass 139 time.sleep(3) 140 141 142 if __name__ == '__main__': 143 catch()
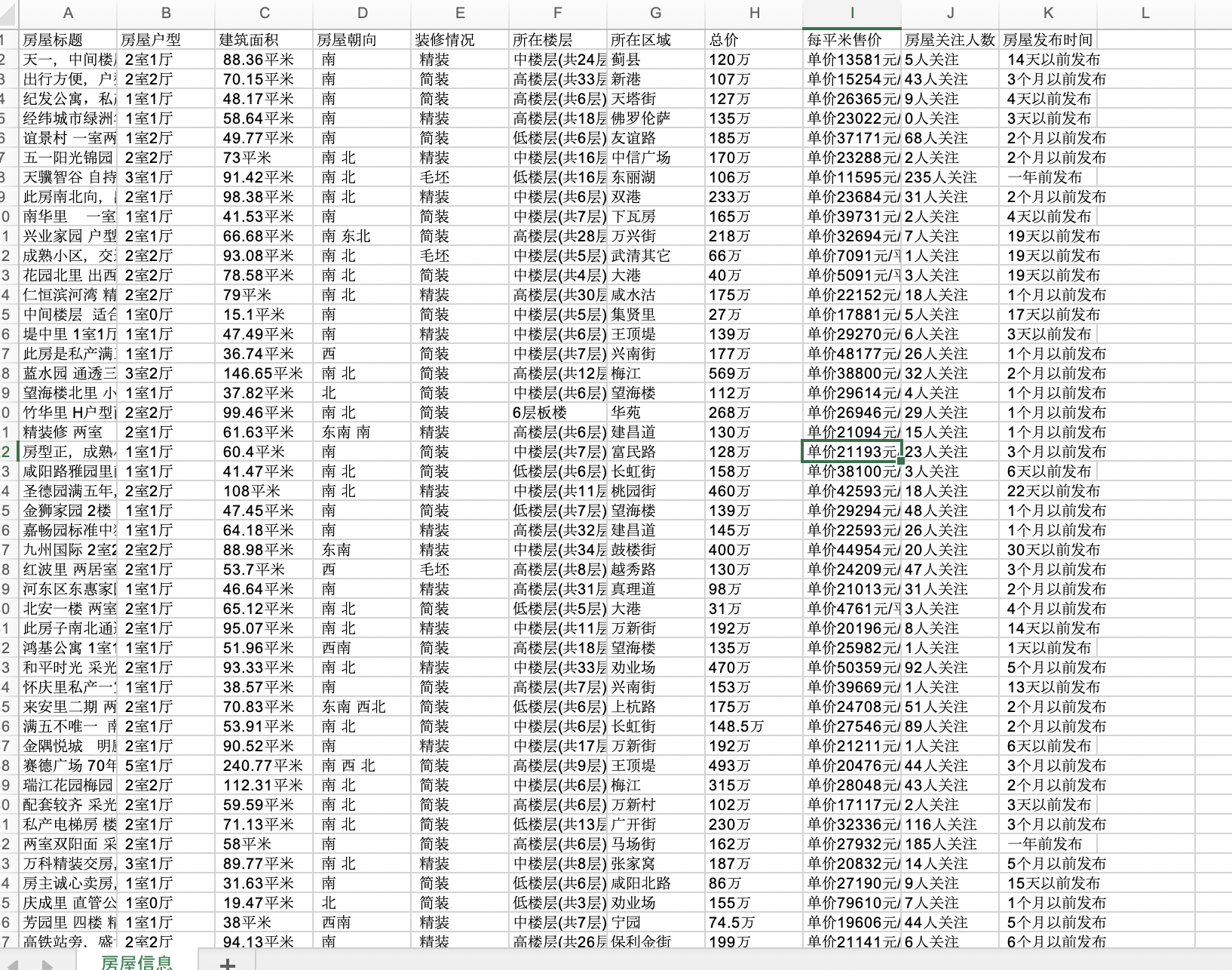
效果图: