1.. 简介
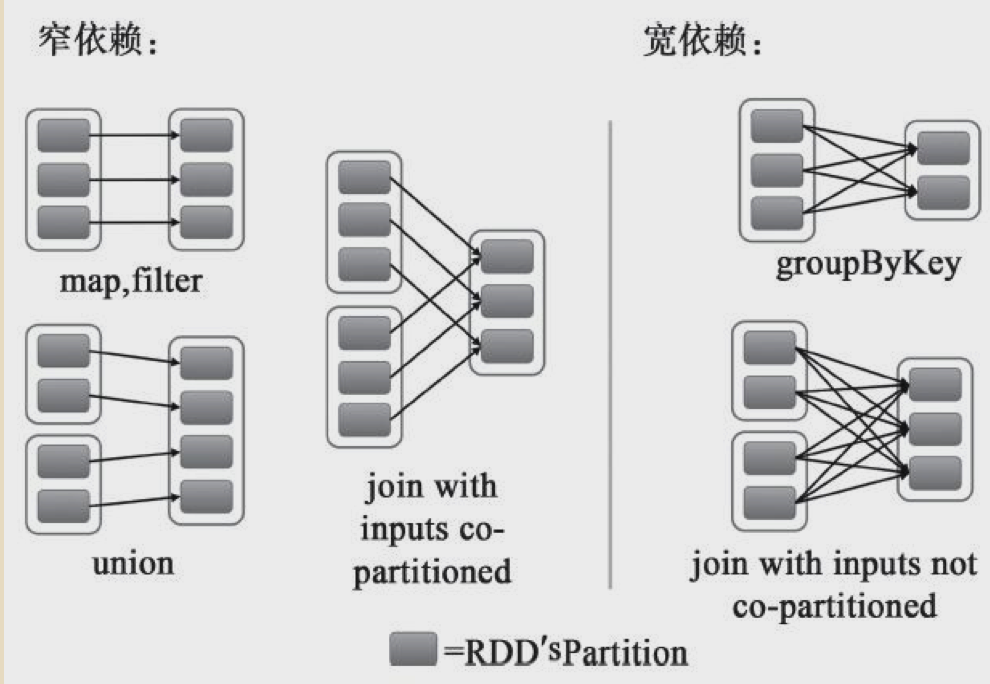
spark从RDD依赖上来说分为窄依赖和宽依赖。
其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依赖。
宽依赖会触发shuffe,宽依赖也是一个job钟不同stage的分界线。
本篇文章主要讨论一下窄依赖的场景。
2.依赖关系的建立
字RDD内部维护着父RDD的依赖关系,下列是依赖的抽象类,其中属性rdd就是父RDD
/**
* :: DeveloperApi ::
* Base class for dependencies.
*/
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
3.窄依赖的三种形式:
窄依赖的抽象类如下:
/** * :: DeveloperApi :: * Base class for dependencies where each partition of the child RDD depends on a small number * of partitions of the parent RDD. Narrow dependencies allow for pipelined execution. */ @DeveloperApi abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] { /** * Get the parent partitions for a child partition. * @param partitionId a partition of the child RDD * @return the partitions of the parent RDD that the child partition depends upon */ def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd }
窄依赖形式一:MAP,Filter....
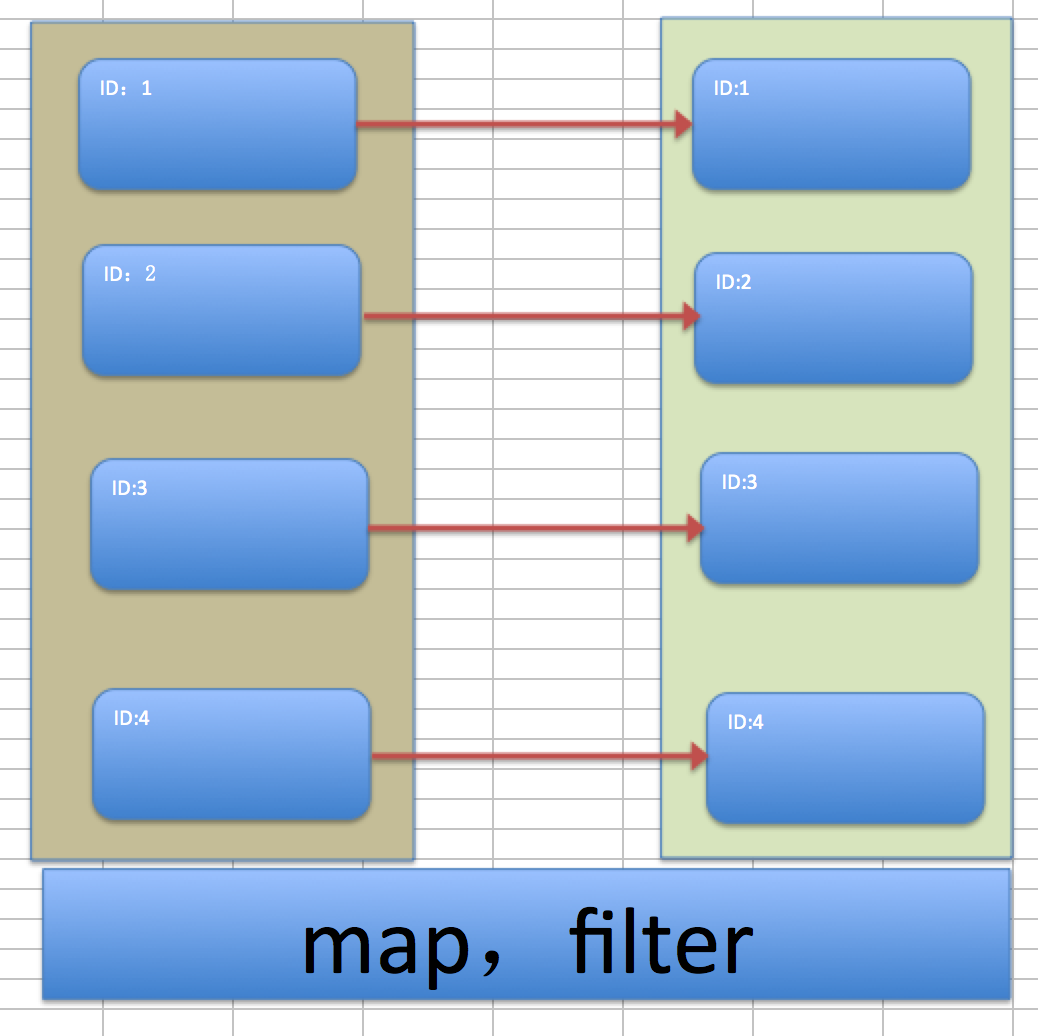
如上两个RDD的转换时通过MAP或者Filter等转换的,RDD的各个partition都是一一对应的,从执行时可以并行化的。
子RDD的分区依赖的父RDD的分区ID是一样不会有变化,这样的窄依赖实现类如下:
/** * :: DeveloperApi :: * Represents a one-to-one dependency between partitions of the parent and child RDDs. */ @DeveloperApi class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = List(partitionId) //子RDD的某个分区ID是和父RDD的分区ID是一致的 }
窄依赖方式二:UNION
先来看看其实现类:
/** * :: DeveloperApi :: * Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs. * @param rdd the parent RDD * @param inStart the start of the range in the parent RDD * @param outStart the start of the range in the child RDD * @param length the length of the range */ @DeveloperApi class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = { if (partitionId >= outStart && partitionId < outStart + length) { List(partitionId - outStart + inStart) } else { Nil } }
一开始并不好理解上述代码,可参考下图,下图中将各个参数的意义图形化展示:
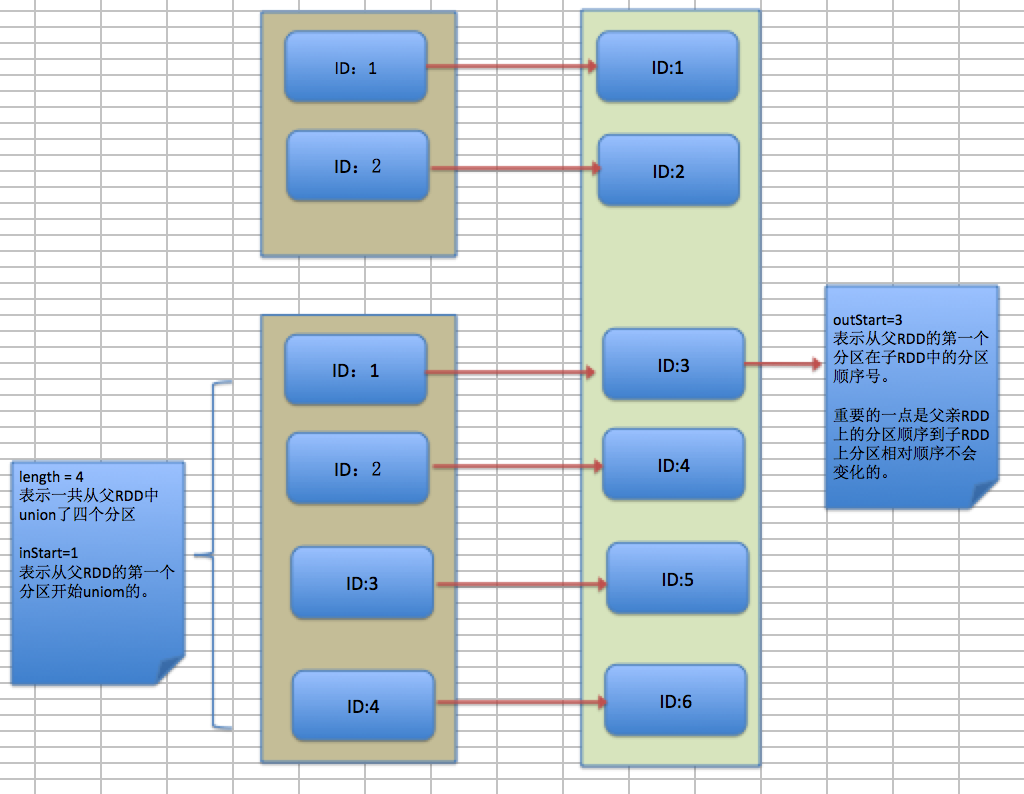
所以上述中子RDD分区中的位号(partitionid)和父RDD的位置号(partitionid)相对的差值 (outStart-inStart)
if (partitionId >= outStart && partitionId < outStart + length) 这段代码的意义:检查当前子RDD分区ID是否在当前父RDD下的范围内
partitionId - outStart + inStart 的意思是:当前子RDD分区id(位置号)与差值相减得出其在父RDD上的分区位置号(id)其实就是:partitionId - (outStart-inStart)
窄依赖方式三:join with inputs co-partitioned
此场景适用于窄依赖方式一。