1.简介
2.X版本后namenode支持了HA特性,使得整个文件系统的可用性更加增强。
2.安装前提
zookeeper集群,zookeeper的安装参考[hadoop][会装]zookeeper安装
3.资源规划
| xufeng-1 | xufeng-2 | xufeng-3 |
| zookeeper | zookeeper | zookeeper |
|
JournalNode |
JournalNode |
JournalNode |
|
NameNode DFSZKFailoverController |
NameNode DFSZKFailoverController |
|
| datanode | datanode | datenode |
| resourcemanager | resourcemanager | |
| nodemanager | nodemanager | nodemanager |
注意:
实际部署的时候JournalNode应该和namenode进程分开部署,这里由于资源有限暂未分开
4.开始部署
a.目录规划
hadoop安装目录使用软链接的方式,这样有利于后续升级后也不需要去修改其他环境变量等参数
配置文件也和安装包分离,有利于后续升级后配置不需要重新倒腾。
hadoop@xufeng-2 hadoop]$ ll 总用量 20 lrwxrwxrwx. 1 hadoop hadoop 52 7月 22 17:18 hadoop -> /opt/hadoop/hadooplib/cdh5.4.2/hadoop-2.6.0-cdh5.4.2 drwxrwxr-x. 2 hadoop hadoop 4096 7月 22 18:43 hadoop-config
b.环境变量设定(xufeng-1上修改后同步到其他机器)
#hadoop export HADOOP_HOME=/opt/hadoop/hadoop export HADOOP_CONF_DIR=/opt/hadoop/hadoop-config export HADOOP_LOG_DIR=/opt/hadoop/hadoop/logs
c.配置文件修改(xufeng-1上修改后同步到其他机器)
首先将软件包中的etc/hadoop下的所有文件拷贝到hadoop-config目录。
修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>--->这里并没有给出具体的那一台主机,因为是两个namenode所以可以将此名称看做为逻辑组合,这个组合后续配置文件中会给出更加详细的描述和定义
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-data/hadoop/temp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>xufeng-1:2181,xufeng-2:2181,xufeng-3:2181</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>------>这里就是core-site.xml中提到的逻辑概念,hdaoop中称之为服务,注意是复数形式,也就是我们如果愿意可以在一个集群中规划处多个服务来
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>-------->描述这个服务有哪些namenode作为管理节点
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>----->描述其中一个namenode的管理节点在哪里
<value>xufeng-1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>xufeng-1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>----->描述另外一个namenode的管理节点在哪里?
<value>xufeng-2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>xufeng-2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://xufeng-1:8485;xufeng-2:8485;xufeng-3:8485/ns1</value>----->指出qjournal地址,这个集群就好比NFS,里面存放的是edits.log,主备namenode都可以访问,做到数据共享,藉此是实现HA的关键
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://xufeng-1:8485;xufeng-2:8485;xufeng-3:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/hadoop-data/hadoop/journaldata</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>------------------>两台主备namenode在其本地存放数据(fsimage)的目录
<value>/opt/hadoop/hadoop-data/hadoop/hdfs/namenode</value>
<description>NameNode directory for namespace and transaction logs storage.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop-data/hadoop/hdfs/datanode</value>
<description>DataNode directory</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>----->指明是使用zkfc的方式去管理主备切换,既伴随namenode启动也会同时在同样的机器上启动zkfc,它的目的就是管理namenode在zookeeper上节点,藉此来实现主备切换实现。
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>------>所谓隔离机制,既是到备namenode升级为主的时候将会使用这一个机制发送命令去杀死另外一个namenode,通常为kill -9(补枪的重要性,万一假死呢)
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->------>使用上述隔离机制既是想对方发送一条shell指令,那么久必须是免密码登录的。
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>---
<value>~/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>------>与namenode的服务一样,这里只写出一个逻辑名称,后续配置会进一步说明
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>------>上述cluster-id逻辑名称下具体有几个实际的rm
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>----->每一个rm的主机位置
<value>xufeng-1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>xufeng-3</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>xufeng-1:2181,xufeng-2:2181,xufeng-3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves文件
这个文件是公用的计算节点配置文件,当启动hdfs模块的时候,此时里面写入的主机上会启动datanode进程。
当启动yarn模块时候,此时里面写入的主机会启动nodemanager进程。
xufeng-1 xufeng-2 xufeng-3
5. 启动hadoop方法和顺序(假设zookeeper已经启动完毕)
[首次启动场景]
1.启动journalnode(各个节点上都执行)
hadoop-daemon.sh start journalnode
2.启动namenode与zkfc
a.由于有两个namenode,所以在xufeng-1上执行:
hdfs namenode -format
b.再将其工作目录(hdfs-site.xml的dfs.namenode.name.dir指定的路径)拷贝到xufeng-2这台主机的对应目录上,以保证两个namenode初始化数据相同
scp -r /opt/hadoop/hadoop-data/hadoop/hdfs/namenode/* xufeng-2:/opt/hadoop/hadoop-data/hadoop/hdfs/namenode
c.格式化zkfc(xufeng-1上执行即可)
hdfs zkfc -formatZK
d.启动hdfs
start-dfs.sh
3.启动yarn
start-yarn.sh
以上将hadoop所有的进程都启动完毕。
6. 验证安装结果
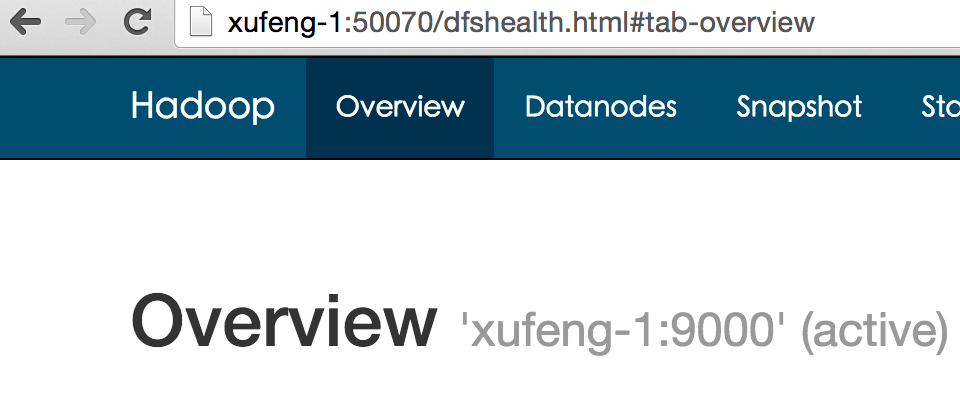
1.检查hdfs:
2.检查yarn

至此hadoop ha模式分布式安装完成。
以上。