背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了20多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来。

Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理。
Storm核心组件

Nimbus:负责资源分配和任务调度,Nimbus对任务的分配信息会落到zookeeper上面的目录下。
Supervisor:负责去zookeeper上的指定目录接受nimbus分配的任务,启动和停止属于自己管理的worker进程。(它是当前物理机器上的管理者)--通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
Storm一些概念
Topologies : 拓扑,也俗称一个任务。(可以理解为一个storm集群)
Spouts : 拓扑的消息源。
Bolts : 拓扑的处理逻辑单元。(一个Bolt类会在集群里面很多机器上并发执行)
(Spouts ,Bolts 可以理解为storm中的两个组件)
tuple:消息元组(是在Spouts ,Bolts中传递数据的一种封装的格式)
Streams : 流
Stream groupings :流的分组策略
Tasks : 任务处理单元
Executor :工作线程
Workers :工作进程
Configuration : topology的配置
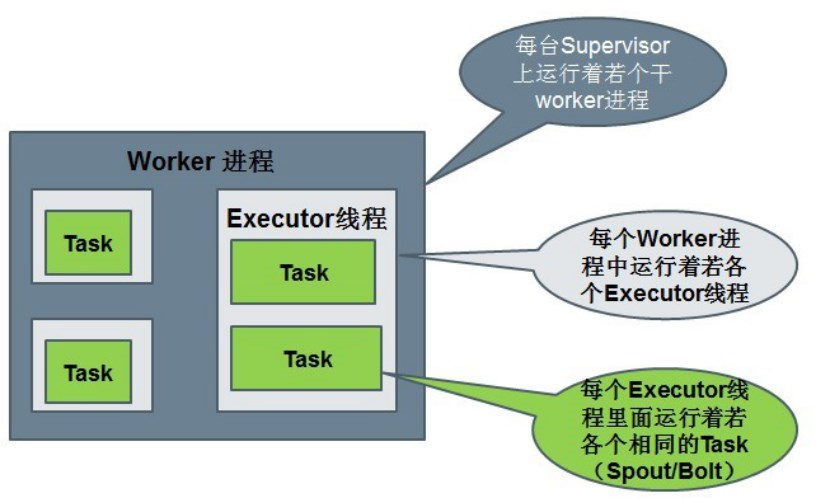
Storm中的Workers
一个topology可能会在一个或者多个worker(工作进程)里面执行;一个进程里面会启动多个Executor :工作线程。
每个worker是一个物理JVM并且执行整个topology的一部分;在一个物理节点上可以运行一个或多个独立的JVM 进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology。比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks;
Storm会尽量均匀的工作分配给所有的worker;一个Executor:工作线程里面可以运行多个相同的task实例。
Storm中的Tasks
每一个spout和bolt会被当作很多task在整个集群里执行;每一个executor对应到一个线程,在这个线程上运行多个task;stream grouping则是定义怎么从一堆task发射tuple到另外一堆task;可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)
Executors (threads)
在一个worker JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。(开发中也不建议一个executor里面执行多个task.)一个worker可以包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集, 同时一个executor只能对应于一个component。
Storm中的Stream
消息流stream是storm里的关键抽象;一个消息流是一个没有边界的tuple序列, 而这些tuple序列会以一种分布式的方式并行地创建和处理;通过对stream中tuple序列中每个字段命名来定义stream。
在默认的情况下,tuple的字段类型可以是:integer,long,short, byte,string,double,float,boolean和byte array;可以自定义类型(只要实现相应的序列化器)。
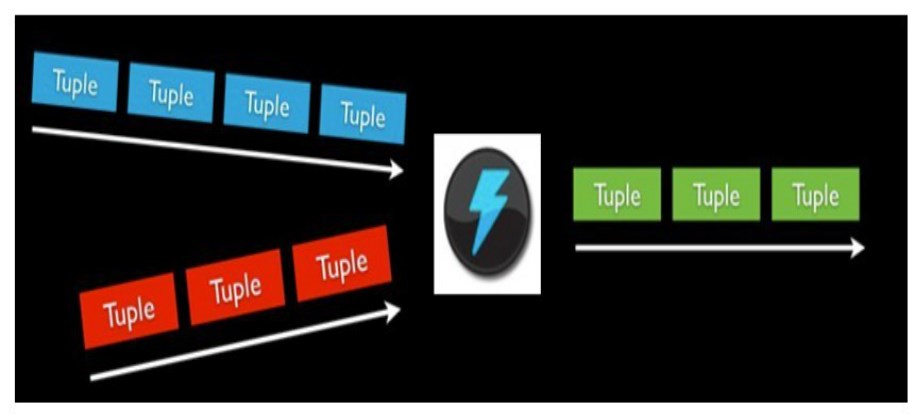
数据从一个节点传到另一个节点,数据是要被序列化的,但在storm中,数据序列化之前,消息必须按照一定的格式传递,这个格式就是一个一个的消息元组。消息元组是源源不断的发送的,这个元组就类似一个list,里面有若干个字段。
Storm编程模型
有向无环图

public class RandomSentenceSpout extends BaseRichSpout { public void nextTuple() { collector.emit(new Values("+ - * % /")); Utils.sleep(50000); } ...... } public class SplitSentenceBolt extends BaseBasicBolt { public void execute(Tuple input, BasicOutputCollector collector) { String sentence = (String)input.getValueByField("intsmaze"); System.out.println(Thread.currentThread().getId()+" "+sentence); } ...... } public class TwoBolt extends BaseBasicBolt { public void execute(Tuple input, BasicOutputCollector collector) { String sentence = (String)input.getValueByField("intsmaze"); System.out.println(Thread.currentThread().getId()+" "+sentence); } ...... } public class WordCountTopologyMain { public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout1", new RandomSentenceSpout(),1); builder.setBolt("two", new TwoBolt(),1).shuffleGrouping("spout1"); builder.setBolt("split1", new SplitSentenceBolt(),2).shuffleGrouping("spout1"); Config conf = new Config(); conf.setDebug(false); conf.setMaxTaskParallelism(3); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("word-count", conf, builder.createTopology()); } } }
可以发现spout每隔一段时间间隔发一份数据,这份数据会被两个bolt同时接收,而不是说这次A bolt接收下次B bolt接收。 同一个bolt业务逻辑如果设置了并行度,他们才会根据分组策略依次接收上游发来的消息。
----------------84 + - * % / 这个是tow bolt接收 ----------------78 + - * % / 这个是split1 bolt 中78线程接收的 ----------------80 + - * % / 这个是split1 bolt中线程80接收的。 ----------------84 + - * % / ----------------78 + - * % / ----------------84 + - * % /
Storm7种stream grouping
Shuffle Grouping: 随机分组,随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
conf.setNumWorkers(4) 表示设置了4个worker来执行整个topology的所有组件 builder.setBolt("boltA-intsmaze",new BoltA(), 4) ---->指明 boltA组件的线程数excutors总共有4个 builder.setBolt("boltB-intsmaze",new BoltB(), 4) ---->指明 boltB组件的线程数excutors总共有4个 builder.setSpout("randomSpout-intsmaze",new RandomSpout(), 2) ---->指明randomSpout组件的线程数excutors总共有2个 -----意味着整个topology中执行所有组件的总线程数为4+4+2=10个 ----worker数量是4个,有可能会出现这样的负载情况,worker-1有2个线程,worker-2有2个线程,worker-3有3个线程,worker-4有3个线程 如果指定某个组件的具体task并发实例数 builder.setSpout("randomspout-intsmaze", new RandomWordSpout(), 4).setNumTasks(8); ----意味着对于这个组件的执行线程excutor来说,一个excutor将执行8/4=2个task,默认情况一个线程执行一个task.