pandas是Python数据分析必备工具,它有强大的数据清洗能力,往往能用非常少的代码实现较复杂的数据处理
今天,总结了pandas筛选数据的15个常用技巧,主要包括5个知识点:
“”
比较运算: ==、<、>、>=、<=、!=
范围运算: between(left,right)
字符筛选: str.contains (pattern或字符串,na=False)
逻辑运算: &(与)、|(或)、not(取反)
比较函数: eq, ne, le, lt, ge, gt (相当于 ==,=!,<=,<,>=,> )
apply 和 isin 函数
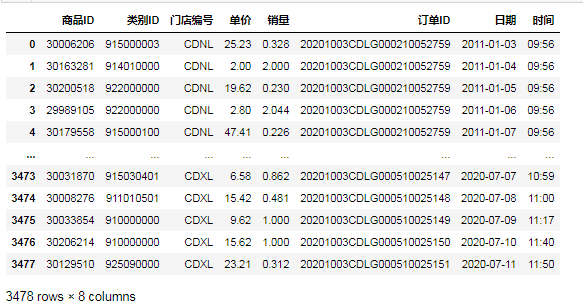
下面以超市运营数据为例,给大家逐个讲解首先读取数据:
import pandas as pd
data=pd.read_excel( '超市运营数据模板.xlsx')
data
先看一下各列的数据类型:
data.dtypes
商品ID int64
类别ID int64
门店编号 object
单价 float64
销量 float64
订单ID object
日期 datetime64[ns]
时间 object
dtype: object
下面以实际应用场景为例开始讲解:
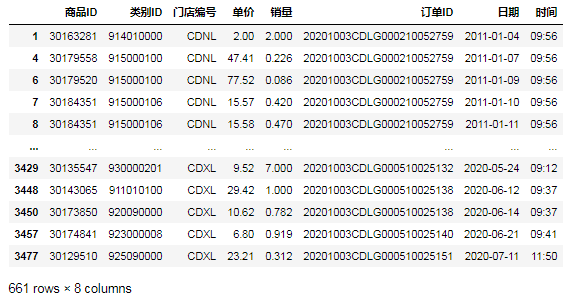
1.筛选门店编号为'CDXL'的运营数据①第一种方法,用比较运算符‘==’: data[data.门店编号== 'CDXL']
②第二种方法,用比较函数'eq': data[data[ '门店编号'].eq( 'CDXL')]

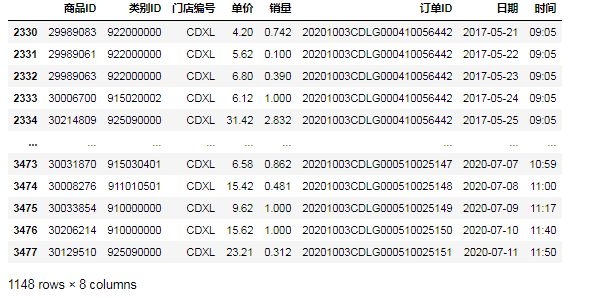
2.筛选单价小于等于10元的运营数据③第一种方法,用比较运算符‘<=’: data[data.单价<=10]
④第二种方法,用比较函数'le': data[data[ '单价'].le(10)]
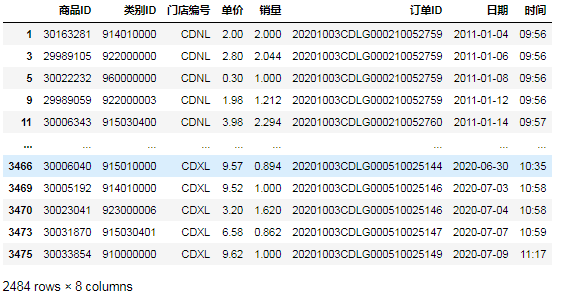
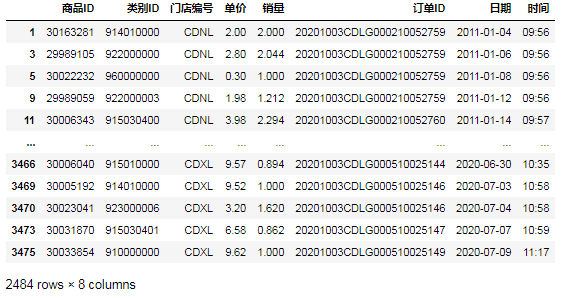
3.筛选销量大于2000的运营数据⑤第一种方法,用比较运算符‘>=’: data[data.销量>2]
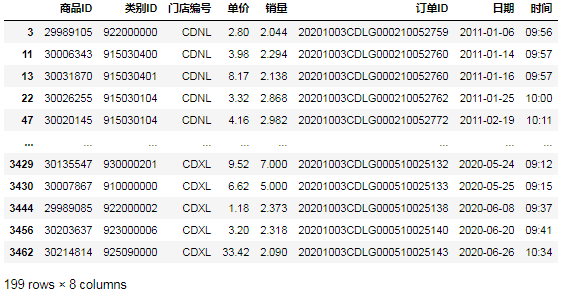
⑥第二种方法,用比较函数'ge': data[data[ '销量'].ge(2)]
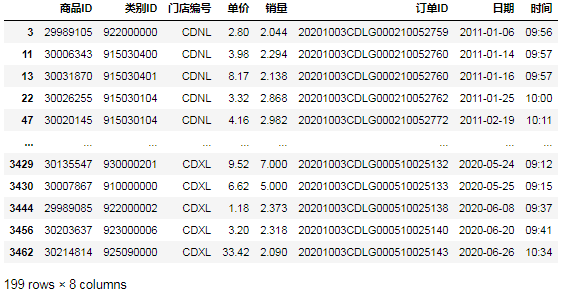
4.筛选除门店'CDXL'外的运营数据⑦第一种方法,用比较运算符‘!=’: data[data.门店编号!= 'CDXL']
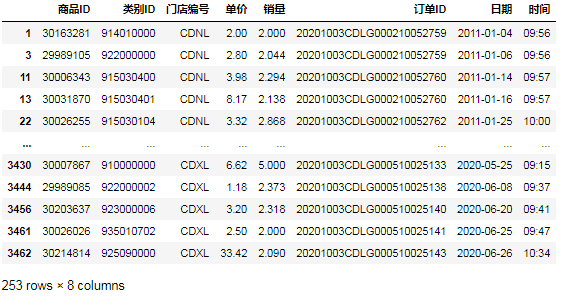
⑧第二种方法,用比较函数'ne': data[data[ '门店编号'].ne( 'CDXL')]
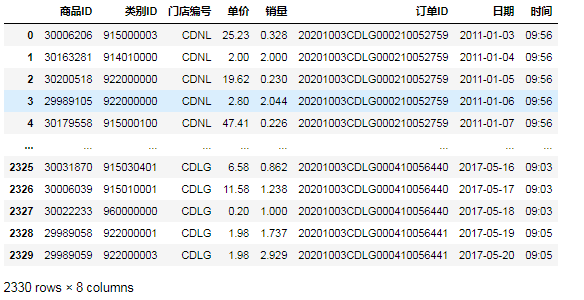
5.筛选2020年5月的运营数据
首先将日期格式化:
data[ '日期']=data[ "日期"].values.astype( 'datetime64') #如果已为日期格式则此步骤可省略
data[ '日期']
import datetime
s_date = datetime.datetime.strptime( '2020-04-30', '%Y-%m-%d').date #起始日期
e_date = datetime.datetime.strptime( '2020-06-01', '%Y-%m-%d').date #结束日期
⑨第一种方法,用逻辑运算符号'>' '<'和'&':
Pandasdatetime64[ns] 不能直接与 datetime.date 相比,需要用 pd.Timestamp 进行转化
data[(data.日期>pd.Timestamp(s_date))&(data.日期<pd.Timestamp(e_date))]
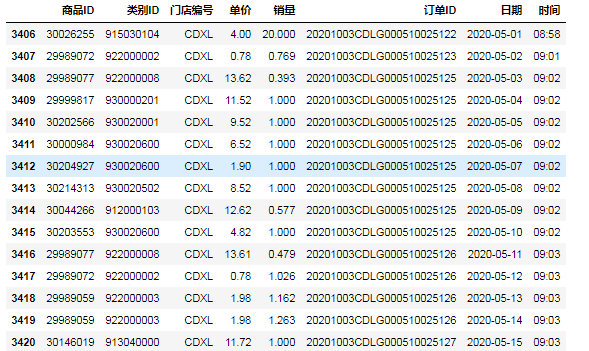
⑩第二种,用比较函数'gt''lt'和'&': data[(data[ '日期'].lt(pd.Timestamp(e_date)))&(data[ '日期'].gt(pd.Timestamp(s_date)))]
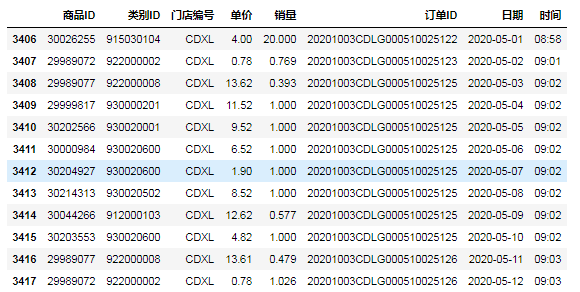
⑪第三种,用apply函数实现: id_a=data.日期.apply(lambda x: x.year ==2020 and x.month==5)
data[id_a]
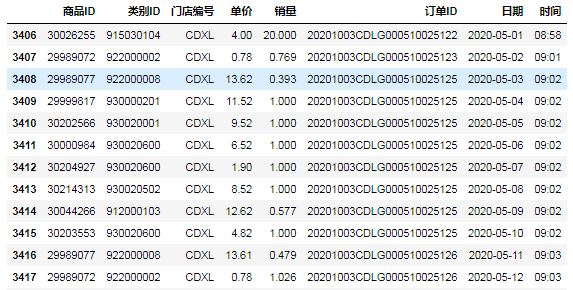
⑫第四种,用between函数实现: id_b=data.日期.between(pd.Timestamp(s_date),pd.Timestamp(e_date))
data[id_b]
6.筛选“类别ID”包含'000'的数据⑬第一种,用contains函数: data[ '类别ID']=data[ '类别ID'].values.astype( 'str') #将该列转换为字符数据类型
id_c=data.类别ID.str.contains( '000',na=False)
data[id_c]

⑭第二种,用isin函数: id_i=data.类别ID.isin([ '000']) #接受一个列表
data[id_i]
很遗憾,isin函数搞不定,因为它只能判断该列中元素是否在列表中
7.筛选商品ID以“301”开头的运营数据⑮需要用contains函数结合正则表达式使用: data[ '商品ID']=data[ '商品ID'].values.astype( 'str') #将该列转换为字符数据类型
id_c2=data.商品ID.str.contains( '301d{5}',na=False)
data[id_c2]