事情是这样的,之前我封装了一个ModbusTCP通信的库(见Github,BUG已修复)。但是最近其他同事在用这个库做开发的时候,发生了OOM的问题:
16:15:17.972 ERROR 26403 --- [pool-6-thread-1] c.lanxincn.wcs.hxb.detector.PLCDetector : 没有到主机的路由: /192.168.2.97:502------------------------------
Exception in thread "http-nio-9090-exec-3" Exception in thread "nioEventLoopGroup-1214-2" java.lang.OutOfMemoryError: GC overhead limit exceeded
java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-exec-2" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-exec-4" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-exec-5" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-exec-7" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-exec-6" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-exec-17" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-9090-Acceptor-0" java.lang.OutOfMemoryError: Java heap space
简单介绍下这个程序的作用,PLCDetector会向PLC建立连接并通过ModbusTCP的协议与PLC通信,达到读取和修改PLC寄存器值的目的。而PLCDetector底层依赖的正是我封装的MessageSender库。
单从这个日志上分析,得到初步的结论确实是堆内存不够了,而且JVM在GC的时候每次回收的空间都十分有限。看来是有什么对象一直存活无法被JVM回收。而且看日志应该就是和通信的过程有关。而且从开始的日志分析,此时与PLC的连接是失败的。和测试人员对接了下,确实在程序启动的时候没有打开PLC的从站。
有了初步的判断后,就开始了问题的排查。既然大概是通信造成的问题,为了尽早让OOM的情况发生,特意将之前每秒通信一次的频率改为了500毫秒通信一次,并且依旧保持无PLC连接的状态。
以下代码是我根据主要流程写的一段测试代码,并不涉及主要业务代码:
public class MessageSenderTest {
private static Map<String, MessageSender> pool = new HashMap<>();
public static void main(String[] args){
String url = "modbusTCP://127.0.0.1:502";
ScheduledExecutorService es = Executors.newScheduledThreadPool(1);
es.scheduleAtFixedRate(()->{
try {
MessageSender sender = getMessageSenderFromPool(url);
Future<MSGResponse> future = sender.sendCommandAsync(ModbusTCPBuilder.buildWriteCommand((byte)0x06, 02, ByteUtils.intTo2Bytes(1)));
MSGResponse response = future.get();
System.out.println(DatatypeConverter.printHexBinary(response.serialize()));
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (Exception e){
e.printStackTrace();
}
}, 1000,500, TimeUnit.MILLISECONDS);
}
protected static MessageSender getMessageSenderFromPool(String url){
MessageSender ms = pool.get(url);
if(ms == null){
MessageSenderFactory factory = new ModbusTCPMessageSenderFactory();
ms = factory.createMessageSender(url, 1000);
pool.put(url, ms);
}
return ms;
}
首先是Main()方法,模拟了我们通信的主要过程,一个定时任务不断的向某个地址发送消息,然后我们通过一个Map将这个连接缓存起来(因为通常PLC会做连接限制,仅允许一个连接建立)。
当我们需要发送时,会先从链接池中获取,如果连接池中没有,才会创建一个连接并保存在连接池中。
运行测试程序(为了能够快速定位BUG,这里将堆适当调小,实际问题发生时堆并非这么小),在开启JvisualVM进行监测:
可以看到每次在Young GC后,被使用的Survivor区依旧维持在高位。
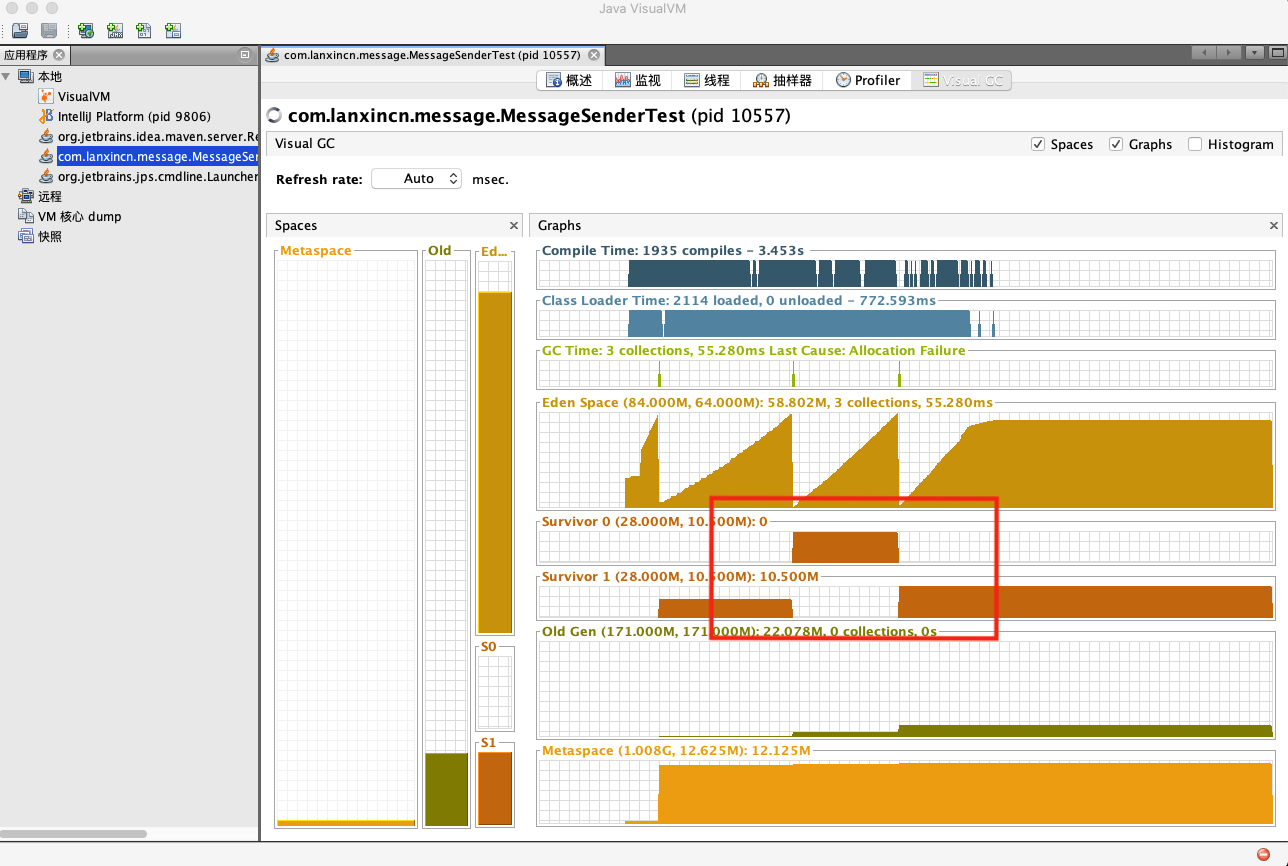
说明很多对象依旧是存活的,直接进入了Old区。
再在visualVM中线程的Tab页下看到很多的线程存活着。
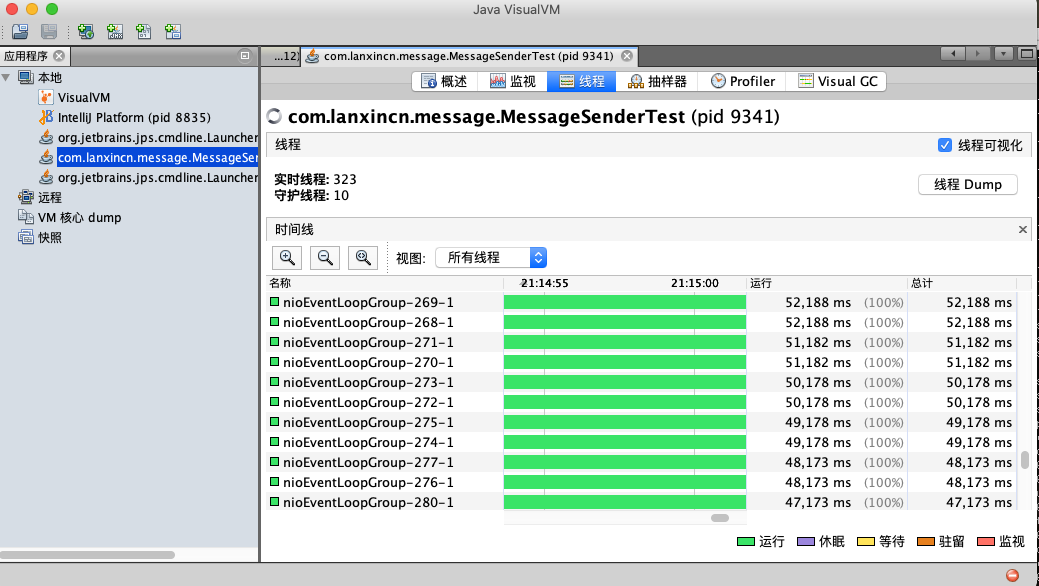
虽然基本可以确定是程序一直在使用Netty创建通信客户端组件,而这一过程伴随着创建NioEventLoop。但是,为了再次确认,还是打开了MAT对Dump的堆快照做一个分析。
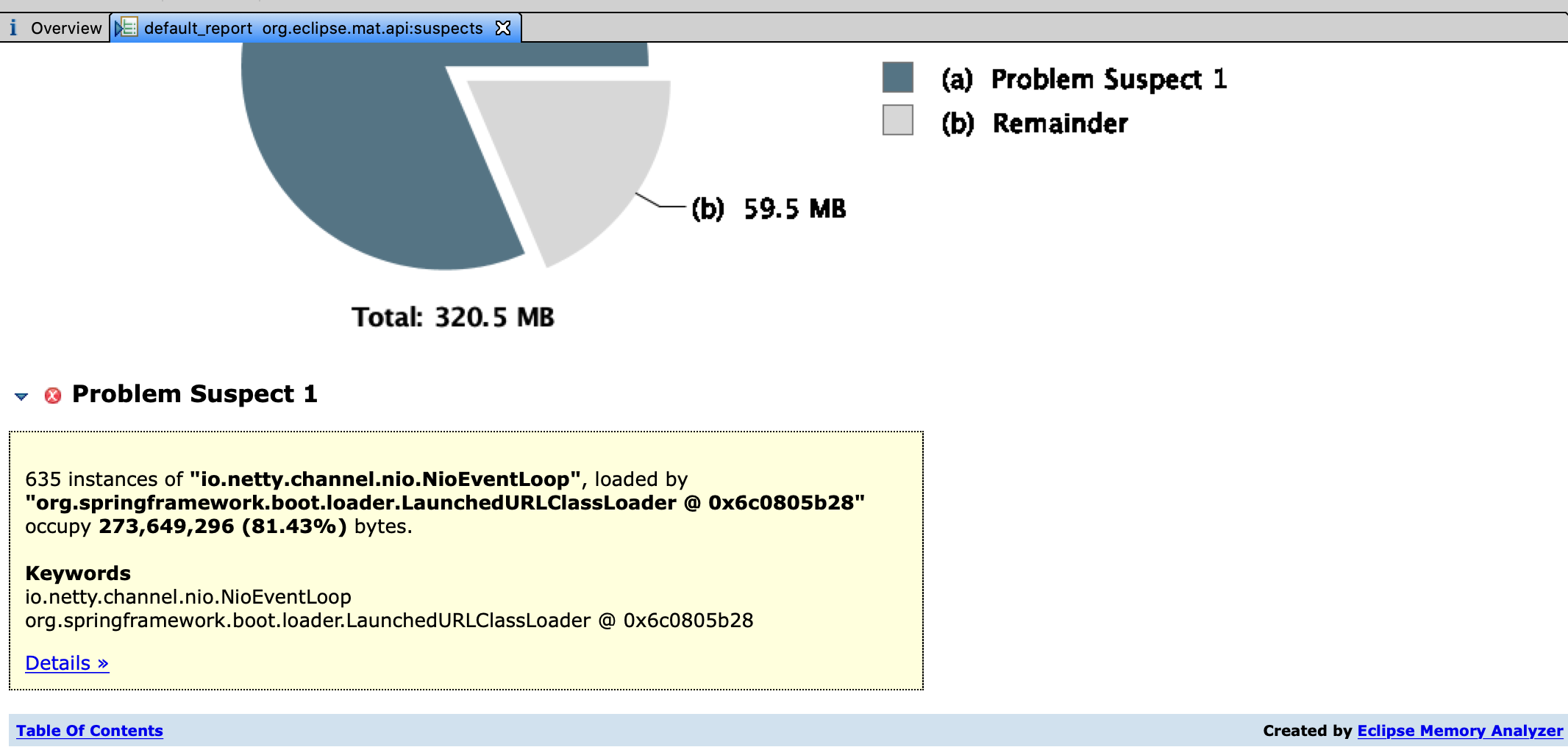
这下基本上是实锤了。
但是回到代码中,明明在创建客户端时做了缓存希望复用,哪为什么还会重复创建客户端呢。
原来问题出在我写的创建代码中:
public ModbusTCPMessageSender(String ip, int port, long timeout){
this.ip = ip;
this.port = port;
NioEventLoopGroup group = new NioEventLoopGroup();
bootstrap = new Bootstrap();
bootstrap.group(group)
.option(ChannelOption.SO_REUSEADDR, false)
.channel(NioSocketChannel.class)
.handler(new ModbusTCPDecodeHandler())
.handler(new ModbusTCPInboundHandler());
//问题所在点
channel = getChannel();
this.timeout = timeout;
}
private Channel getChannel(){
if(channel == null || !channel.isActive()){
try {
channel = bootstrap.connect(ip, port).sync().channel();
} catch (InterruptedException e) {
logger.warn("Connect Channel failed", e);
e.printStackTrace();
}
}
return channel;
}
看上述代码注释的问题所在点。我直接在构造函数中创建channel,并尝试连接,而一旦此时连接失败,它是会抛出异常的,并且这个异常并不是我catch的InterruptedException异常。也就是说这个创建MessageSender执行异常了,因此也就没有被put进缓存中。而此时NioEventLoopGroup()已经创建了。这个对象就像是一个线程池,内部的NioEventLoop就是个工作线程。当调用connect()时,因为有事件被提交到了线程池,所以线程池内部的工作线程NioEvnetLoop就被创建了。而NioEventLoop是负责处理事件循环的,也就是说它将会一直在一个while()循环中工作,是不会轻易被GC的。
就是因为这个原因,造成了我们内存泄漏的问题,然后引发了OOM。
OOM的问题是找到了,但在我自己电脑上测试的时候,还引发了一个更刺激的问题:
Caused by: java.io.IOException: Too many open files in system
at sun.nio.ch.IOUtil.makePipe(Native Method)
at sun.nio.ch.KQueueSelectorImpl.<init>(KQueueSelectorImpl.java:84)
at sun.nio.ch.KQueueSelectorProvider.openSelector(KQueueSelectorProvider.java:42)
at io.netty.channel.nio.NioEventLoop.openSelector(NioEventLoop.java:175)
系统打开的文件描述符过多了。而且因为这个问题还把我浏览器弄崩了。这...
赶紧用lsof -p查了下对应进程打开的文件描述符:
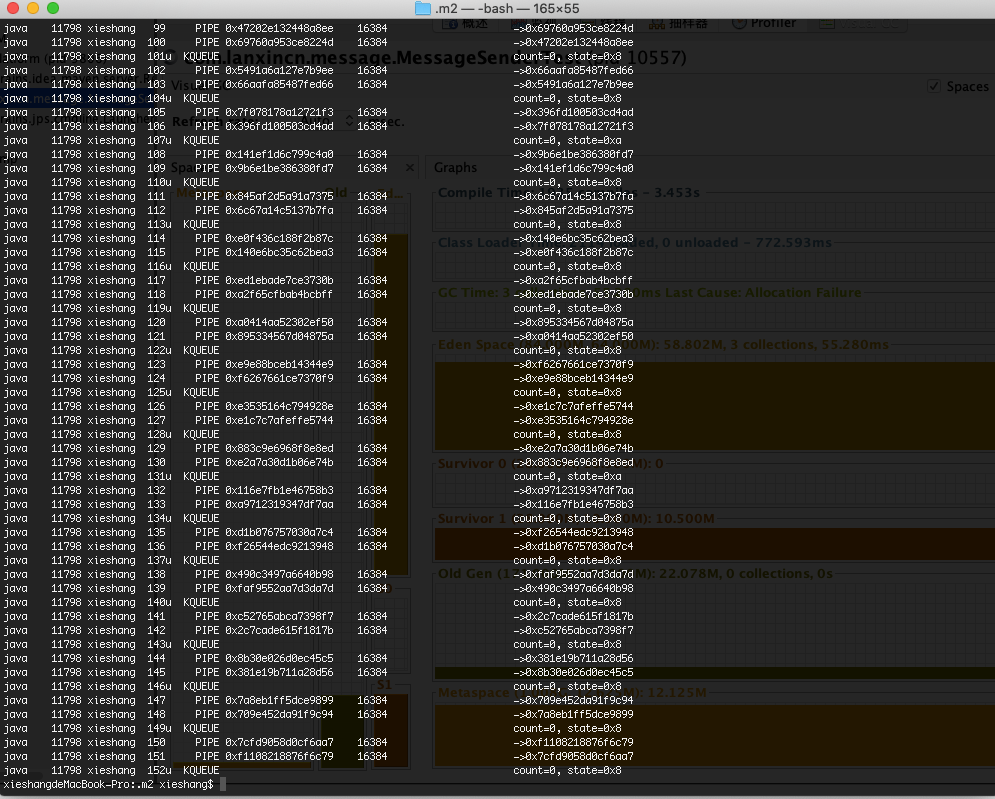
密密麻麻的一片,而且大部分类型都是向KQUEUE和PIPE。
KQUEUE是多路复用的一种底层实现,而Netty正式基于NIO编写的框架。看来又是Netty哪里除了问题。
最后查出来,问题出在Nio底层的多路复用选择器Selector上。
当我们创建一个Selector时,操作系统也是需要打开文件的。
怪不得我们创建Selector时,调用的方法叫Slector.open()呢。这个open用的完全没毛病。