Jmeter参数化常用的两种方法:
1、使用函数助手
2、CSV Data Set Config
本章主要讲解CSV Data Set Config设置

1、Filename:文件名,指保存信息的文件目录,可以相对或者绝对路径
2、File encoding:csv文件编码,可以不填,一般为UTF-8
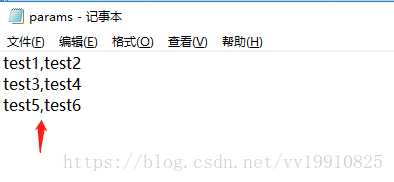
3、Variable Names(comma-delimited):变量名称,用逗号分隔,test1代表参数化文档中的第一列,test2代表参数化文档中的第二列,变量使用格式 ${name}
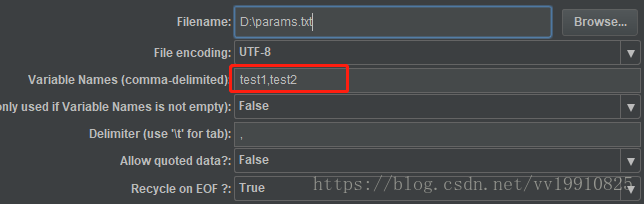

5、Delimiter(use ' for tab'):定义分隔符为',',若参数化文档中有多列,则每列间用逗号分隔

6、Allow quoted data:是否允许引用数据(没用过)
7、Recycle on EOF:到了文件尾处,是否循环读取参数。因为CSV Data Set Config一次读入一行,分割后存入若干变量交给一个线程,如果线程数超过文本的记录行数,那么可以选择从头再次读入
8、Stop thread on EOF:到了文件尾处,是否停止线程,和Recycle on EOF会有矛盾:
a. 当Recycle on EOF 选择true时,Stop thread on EOF选择true和false无任何意义,通俗的讲,在前面控制了不停的循环读取,后面再来让stop或run没有任何意义
b. 当Recycle on EOF 选择flase时,Stop thread on EOF选择true,线程4个,参数3个,那么只会请求3次
c. 当Recycle on EOF 选择flase时,Stop thread on EOF选择flase,线程4个,参数3个,那么会请求4次,但第4次没有参数可取,不让循环,所以第4次请求错误
9、Sharing mode:共享模式,All threads –所有线程,Current thread group—当前线程组,Current thread—当前线程。经试验得出来的结果是(不考虑线程组迭代):
a. 如果测试计划中有线程组A、线程组B,A组内有线程A1到线程An,线程组B内有线程B1到线程Bn,CSV Data Set Config放在线程组A的下级组织树,不管怎么设置Sharing mode,都只针对线程组A且取之情况一样:线程A1取第一行,线程A2取第二行。
b. CSV Data Set Config放在测试计划下级组织树(与线程组并列),情况如下 :
All threads:测试计划中所有线程,线程组A、线程组B共用一个CSV文件,所取数据与线程实际执行顺序有关(先执行先取)。补充一点:线程组之间是并行执行,各线程实际执行时间根据Ramp-UP Period而来,如下图,若线程A、线程B均设置Ramp-Up Period:2,取之情况是:线程A1取第1行,线程B1取第2行,线程A2取第3行,线程B2取第4行。
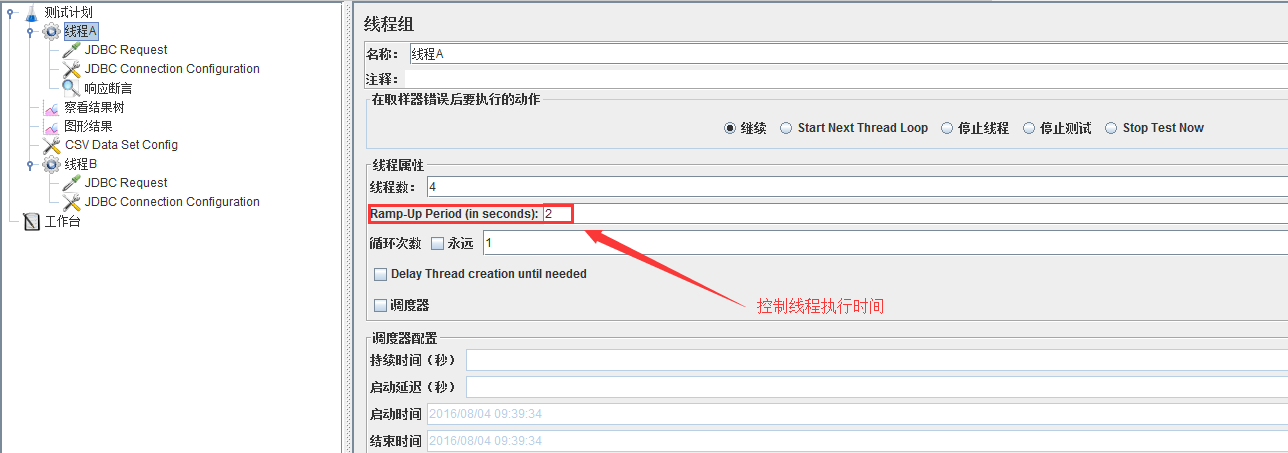
Current thread group:取之情况是:线程A1取第1行,线程A2取第2行,线程B1取第1行,线程B2取第2行。(线程组互不影响)
Current thread:当前线程。A1取第一行,A2取第一行;B1取第一行,B2取第一行(均取第一行)
---------------------
还要注意CSV Data Set Config放的位置影响取数结果:
场景一:如果放在循环控制器的上面:线程数:1,循环数:10,实际情况:循环上面的csv数据只读了线程数,下面的循环请求没有重新拿数据,还是使用第一次线程拿的数据,如图:
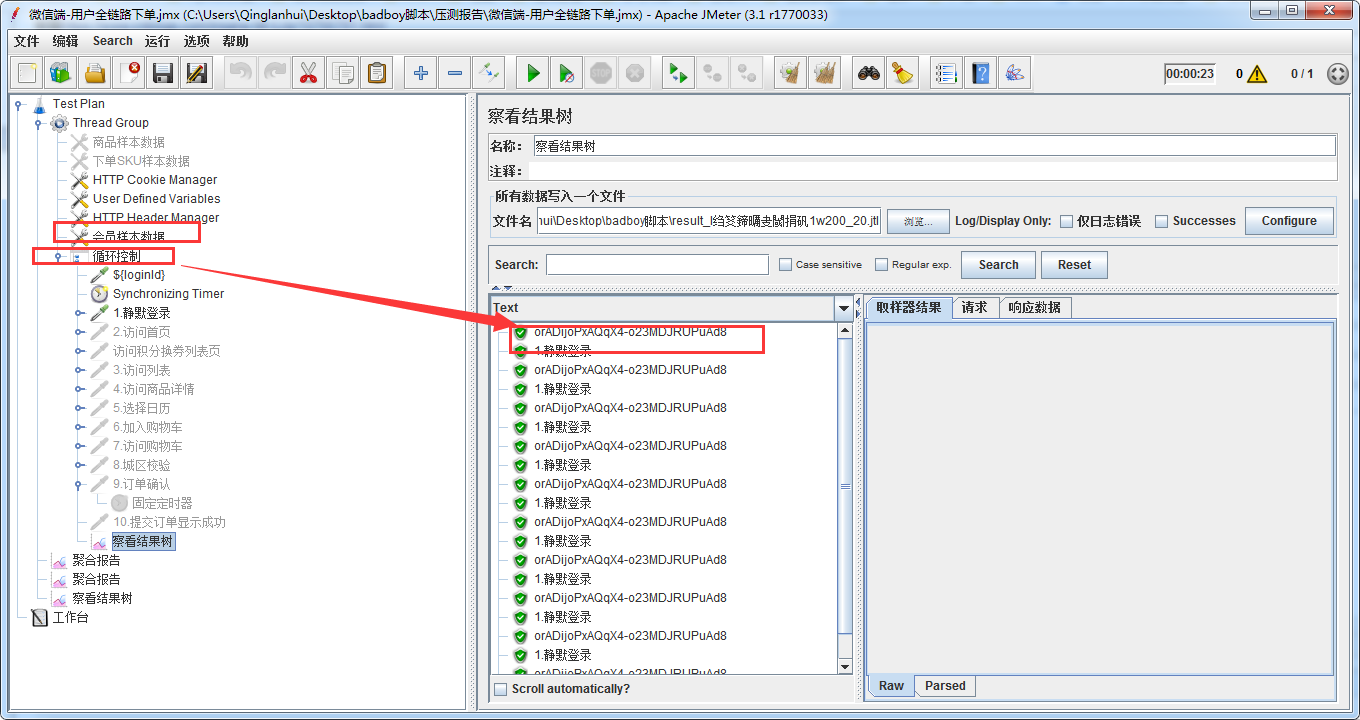
场景二:如果放在循环控制器的下面:线程数:1,循环数:10,实际情况:循环下面的csv数据只读了线程数,每次循环都会拿新的数据顺序取值,如图:
所以CSV Data Set Config放的位置和取数方式有很大的关系。