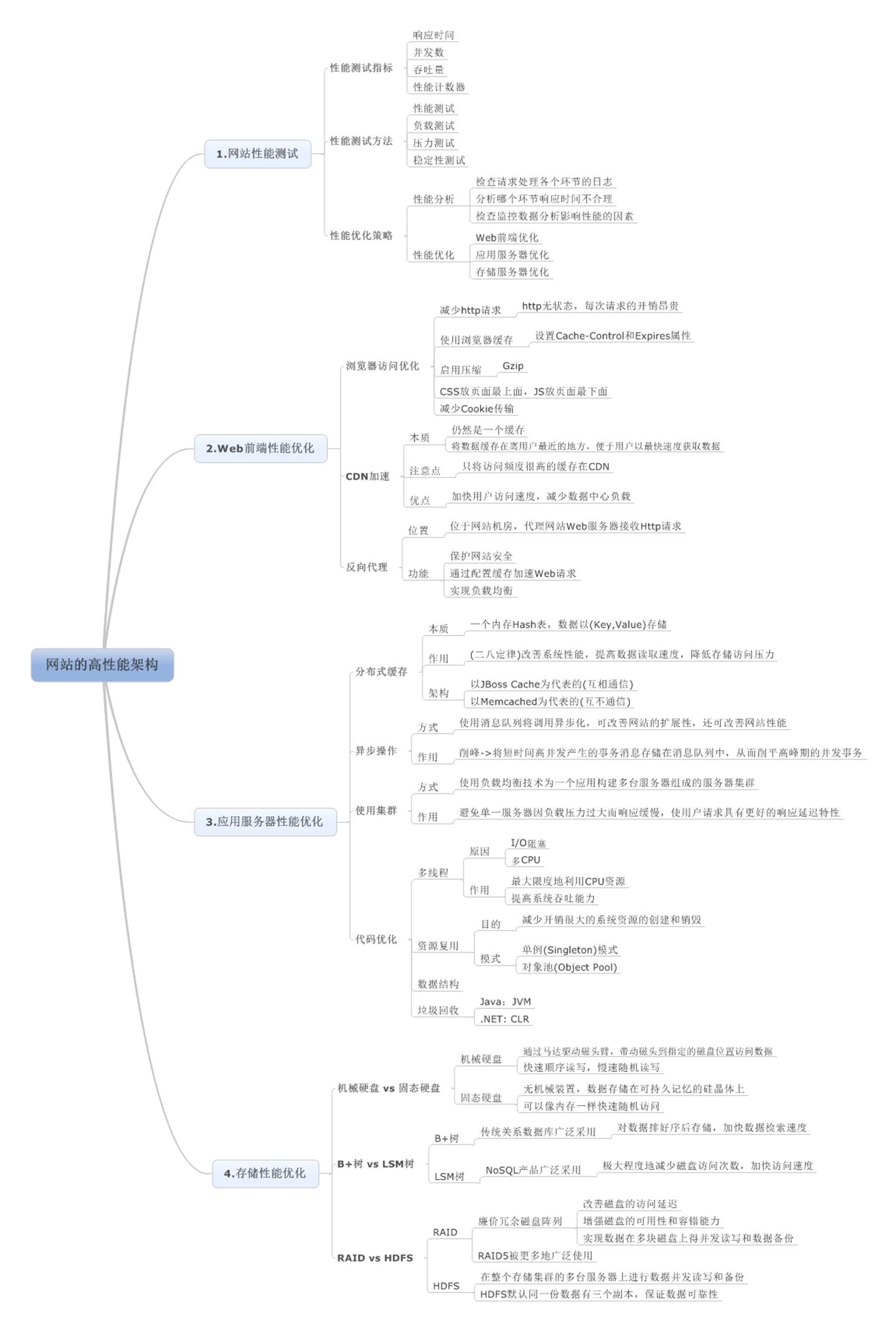
一、概述
性能测试是性能优化的前提和基础。也是性能优化检查和度量的标准。不同的视角下网站的性能有不同的标准,也有不同的优化手段
二、性能分类
-
用户视觉的性能
过程:用户情况à网站通讯时间à处理时间à用户计算机浏览器解析
优化手段
通过前端优化手段,通过html样式话,利用浏览器段并发和异步特性,挑战浏览器缓存,使用CDN和反向代理使浏览器尽快返回用户感兴趣数据。即使不优化应用程序和架构,也可以很大程度改善用户视觉性能
-
开发人员视觉的性能
关注应用程序本身及子系统的性能,包括相应延迟,系统吞吐量,并发处理能力,系统稳定行等技术指标。
优化手段:
使用缓存加速数据读取,使用集群提高吞吐能力,使用异步消息加快请求响应及实现削峰,使用代码优化改善程序性能。
-
运维人员视觉的性能
运维人员更关注基础设施性能和资源利用率,如带宽处理能力,
优化手段:
服务器硬件配置,数据中心网络架构,服务器和网络带宽利用率等主要优化手段建设,使用高性价比定制服务器,利用虚拟化技术优化资源利用。
三、架构设计中要考虑的核心五要素
性能、可用性、扩展性、伸缩性、安全性
四、网站性能测试
(1)性能测试指标:①响应时间;②并发数;③吞吐量;④性能计数器;
(2)性能测试方法:①性能测试;②负载测试;③压力测试;④稳定性测试;
(3)性能优化策略:
①性能分析:排查一个网站的性能瓶颈和排查一个应用查询的性能手法基本相同:检查请求处里的各个环节日志,分析那个环节响应时间不合理,超过预期;然后检查监控数据,分析影响性能的主要因素是内存,磁盘,网络还是cpu,是代码问题还是架构不合理,或是系统资源不足
②性能优化:Web前端优化,应用服务器优化,存储服务器优化;
性能优化前的准备
性能的测试指标
响应时间
应用执行一个操作需要的时间,包括从发出请求开始到收到最后响应数据所需要的时间。响应时间是系统最重要的性能指标,直观地反映了系统的"快慢"。下表列出了一些常用的系统操作需要的响应时间。 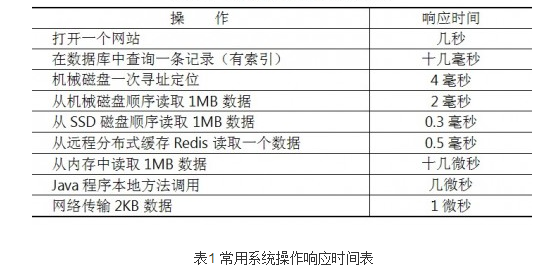
并发数
系统能够同时处理请求的数目
吞吐量
单位时间内系统处理的请求数量; 如:TPS、QPS(每秒查询数),HPS每秒http请求数量 ,PV 页面访问,随着并发数的增大,吞吐量随着增大; 超过阈值后,并发数继续增大,吞吐量下降,直到吞吐量降为0,网站宕机;理解上述3个指标:类比高速公路行车 ,吞吐量就是每天通过的车辆数 ,并发数是正在行驶的车辆 ,响应时间是车速
性能计数器
描述服务器或操作系统性能指标的一些数据指标。包括System Load,对象与线程数,内存使用,cpu使用,磁盘与网络io等指标.这些指标也是性能监控的重要指标。System Load反映系统Cpu正在指向和等待执行的进程数量。
性能测试方法
-
性能测试
以预期设定的性能值为目标,测试是否能满足预期 -
负载测试
不断加压到安全临界值 -
压力测试
超过安全负载直到崩溃下的最大负载 -
稳定性测试
特地环境下。持续运行一段较长时间。
下图中的横坐标表示消耗的系统资源,纵坐标表示系统处理能力(吞吐量)。在开始阶段,随着并发请求数目的增加,系统使用较少的资源就达到较好的处理能力(a~b段),这一段是网站的日常运行区间,网站的绝大部分访问负载压力都集中在这一段区间,被称作性能测试,测试目标是评估系统性能是否符合需求及设计目标;随着压力的持续增加,系统处理能力增加变缓,直到达到一个最大值(c点),这是系统的最大负载点,这一段被称作负载测试。测试目标是评估当系统因为突发事件超出日常访问压力的情况下,保证系统正常运行情况下能够承受的最大访问负载压力;超过这个点后,再增加压力,系统的处理能力反而下降,而资源消耗却更多,直到资源消耗达到极限(d点),这个点可以看作是系统的崩溃点,超过这个点继续加大并发请求数目,系统不能再处理任何请求,这一段被称作压力测试,测试目标是评估可能导致系统崩溃的最大访问负载压力。
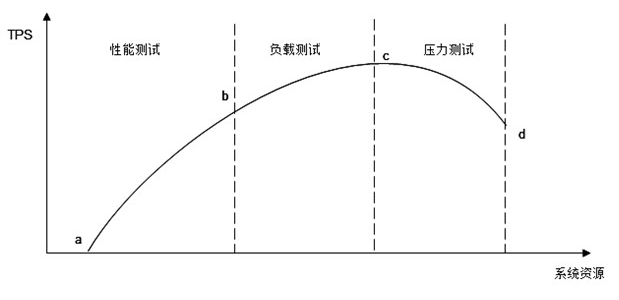
性能测试反应的是系统在实际生产环境中使用时,随着用户并发访问数量的增加,系统的处理能力。与性能曲线相对应的是用户访问的等待时间(系统响应时间),如图所示。

在日常运行区间,可以获得最好的用户响应时间,随着并发用户数的增加,响应延迟越来越大,直到系统崩溃,用户失去响应。
性能测试报告
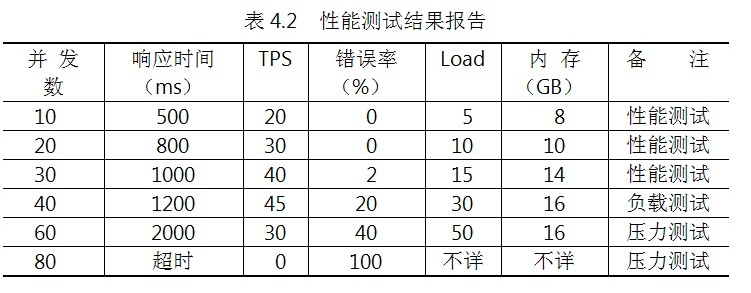
测试结果报告应能够反映上述性能测试曲线的规律,阅读者可以得到系统性能是否满足设计目标和业务要求、系统最大负载能力、系统最大压力承受能力等重要信息,下表是一个简单示例。
五、Web前端性能优化
(1)浏览器访问优化:
①减少http请求:因为http是无状态的,每次请求的开销都比较昂贵(需要建立通信链路、进行数据传输,而服务器端对于每个http请求都需要启动独立的线程去处理);减少http的主要手段是合并CSS、合并JS、合并图片(CSS精灵,利用偏移定位image);
②使用浏览器缓存:设置http头中Cache-Control和Expires属性;
③启用压缩:可以对html、css、js文件启用Gzip压缩,可以达到较高的压缩效率,但是压缩会对服务器及浏览器产生一定的压力;
④CSS放页面最上面,JS放页面最下面:浏览器会在下载完全部CSS之后才开始对整个页面进行渲染,因此最好将CSS放在页面最上面;而浏览器在加载JS后会立即执行,有可能会阻塞整个页面,造成页面显示缓慢,因此最好将JS放在页面最下面;
⑤减少Cookie传输:一方面,太大的Cookie会严重影响数据传输;另一方面,对于某些静态资源的访问(如CSS、JS等)发送Cookie没有意义;
(2)CDN加速:
CDN(内容分发网络)仍然是一个缓存,它将数据缓存在离用户最近的地方,便于用户以最快速度获取数据。即所谓的"网络访问第一跳",如下图所示:
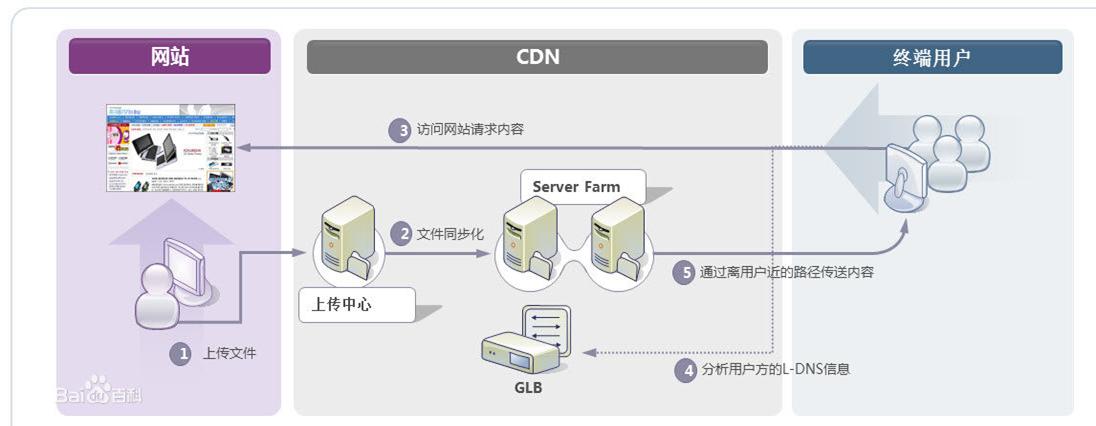
CDN只将访问频度很高的热点内容(例如:图片、视频、CSS、JS脚本等访问频度很高的内容)进行缓存,可以极大地加快用户访问速度,减少数据中心负载。
(3)反向代理:
反向代理服务器位于网站机房,代理网站Web服务器接收Http请求,对请求进行转发,如下图所示:
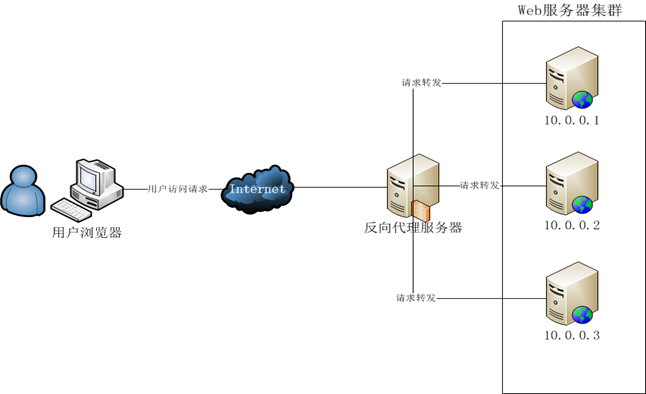
反向代理服务器具有以下功能:
①保护网站安全:任何来自Internet的请求都必须先经过代理服务器;
②通过配置缓存功能加速Web请求:减轻真实Web服务器的负载压力;
③实现负载均衡:均衡地分发请求,平衡集群中各个服务器的负载压力;
六、应用服务器性能优化
(1)分布式缓存:
PS:网站性能优化第一定律:优先考虑使用缓存优化性能。缓存是指将数据存储在相对较高访问速度的存储介质中(如内存),以供系统进行快速处理响应用户请求。
①缓存本质是一个内存Hash表,数据以(Key,Value)形式存储在内存中。
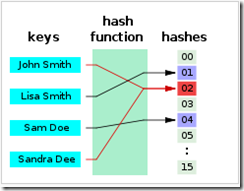
②缓存主要用来存放那些读写比很高、很少变化的数据,如商品的类目信息、热门商品信息等。这样,应用程序读取数据时,先到缓存中取,如缓存中没有或失效,再到数据库中取出,重新写入缓存以供下一次访问。因此,可以很好地改善系统性能,提高数据读取速度,降低存储访问压力。
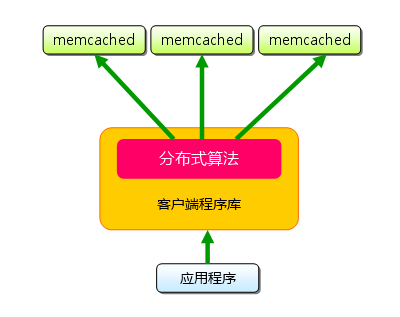
③分布式缓存架构:一方面是以以JBoss Cache为代表的互相通信派;另一方面是以Memcached为代表的互不通信派;
JBoss Cache需要将缓存信息同步到集群中的所有机器,代价比较大;而Memcached采用一种集中式的缓存集群管理,缓存与应用分离部署,应用程序通过一致性Hash算法选择缓存服务器远程访问缓存数据,缓存服务器之间互不通信,因而集群规模可以轻易地扩容,具有良好的伸缩性。
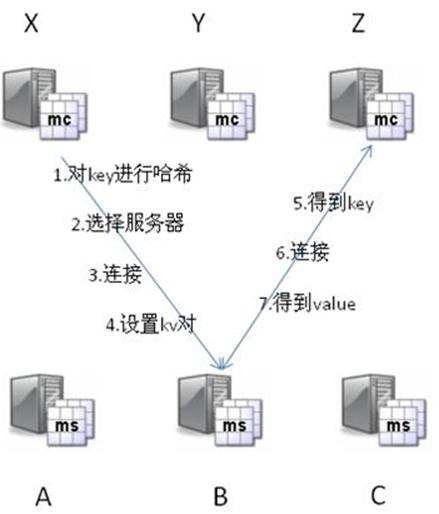
Memcached由两个核心组件组成:服务端(ms)和客户端(mc),在一个memcached的查询中,mc先通过计算key的hash值来确定kv对所处在的ms位置。当ms确定后,客户端就会发送一个查询请求给对应的ms,让它来查找确切的数据。因为这之间没有交互以及多播协议,所以 memcached交互带给网络的影响是最小化的。
(2)异步操作:
①使用消息队列将调用异步化,可改善网站的扩展性,还可改善网站性能;
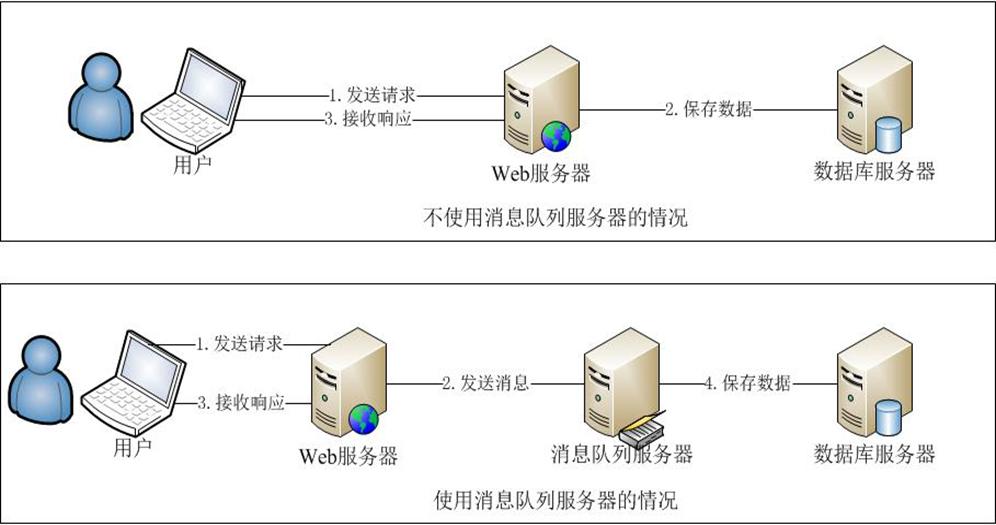
②消息队列具有削峰的作用->将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务;
PS:任何可以晚点做的事情都应该晚点再做。前提是:这个事儿确实可以晚点再做。
(3)使用集群:
①在高并发场景下,使用负载均衡技术为一个应用构建多台服务器组成的服务器集群;
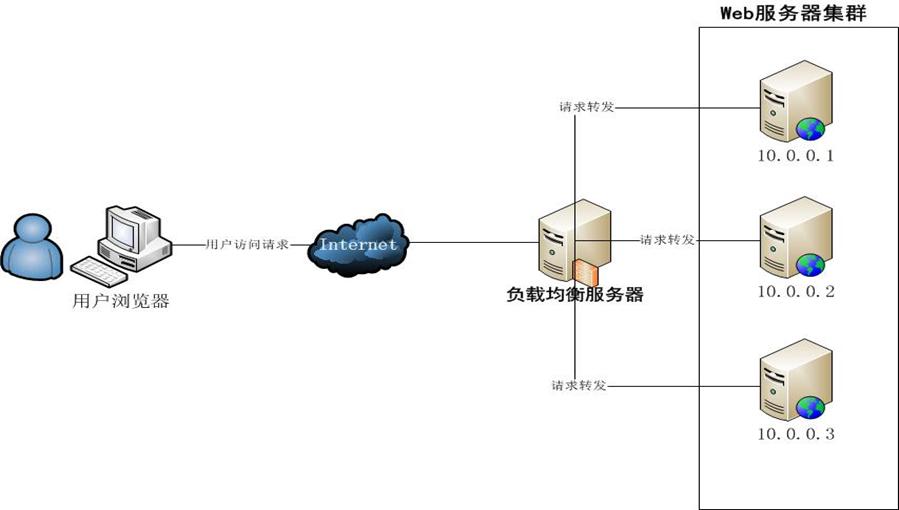
②可以避免单一服务器因负载压力过大而响应缓慢,使用户请求具有更好的响应延迟特性;
③负载均衡可以采用硬件设备,也可以采用软件负载。商用硬件负载设备(例如出名的F5)成本通常较高(一台几十万上百万很正常),所以在条件允许的情况下我们会采用软负载,软负载解决的两个核心问题是:选谁、转发,其中最著名的是LVS(Linux Virtual Server)。
PS:LVS是四层负载均衡,也就是说建立在OSI模型的第四层——传输层之上,传输层上有我们熟悉的TCP/UDP,LVS支持TCP/UDP的负载均衡。
LVS的转发主要通过修改IP地址(NAT模式,分为源地址修改SNAT和目标地址修改DNAT)、修改目标MAC(DR模式)来实现。有关LVS的详情请参考:http://www.importnew.com/11229.html
(4)代码优化:
①多线程:使用多线程的原因:一是IO阻塞,二是多CPU,都是为了最大限度地利用CPU资源,提高系统吞吐能力,改善系统性能;
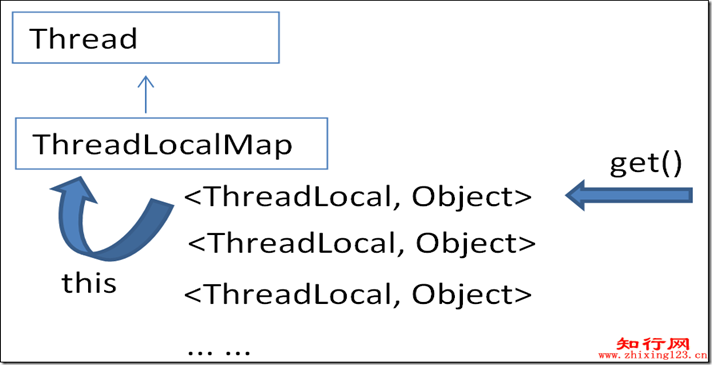
②资源复用:目的是减少开销很大的系统资源的创建和销毁,主要采用两种模式实现:单例(Singleton)和对象池(Object Pool)。例如,在.NET开发中,经常使用到的线程池,数据库连接池等,本质上都是对象池。
③数据结构:在不同场合合理使用恰当的数据结构,可以极大优化程序的性能。
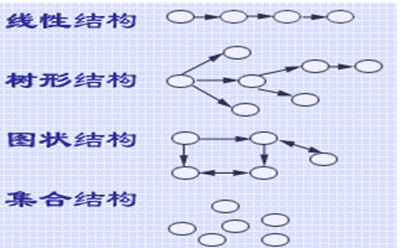
-
垃圾回收:理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安安全的代码。这里主要针对Java(JVM)和C#(CLR)一类的具有GC(垃圾回收机制)的语言。
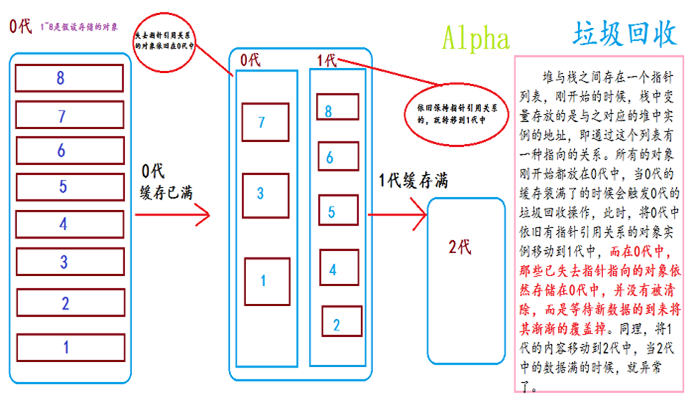
Java中JVM介绍及GC执行时机
内存分为堆栈和堆,堆栈用于存储线程上下文信息,如方法参数,局部变量等。堆则是存储对象的内存空间,对象的创建和销毁。垃圾回收就是在这里进行。
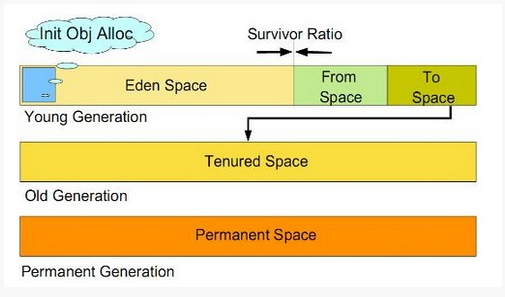
将JVM分为年轻带(Young Generation)和年老带(Old Generation),又将年轻带(Young Generation)分为,Eden区,From区,To区。新建对象总是在Eden区创建,当Eden区空间已满,就触发一次Young GC(Garbage Collection,垃圾回收),将还被使用的对象复制到From区,这样Eden区都是未使用的对象,还可以继续创建对象,当Eden去在次用完,在触发一次Young GC,将Eden区和From区还在使用的对象复制到To区。下一次Young GC则是将Eden区和To区对象复制到From区。经过多次GC,某些对象会在From和To区多次复制,如果超过某个阀值对象还未被释放,则将对象复制到Old Generation。如果Old Generation空间已经用完,那么会触发Full GC,即所谓的全量回收,全量回收对系统性能产生较大影响,因此应该根据业务特点和对象生命周期合理设置Young Generation和Old Generation区域大小,尽量减少Full GC.
七、存储性能优化
(1)机械硬盘还是固态硬盘?
①机械硬盘:通过马达驱动磁头臂,带动磁头到指定的磁盘位置访问数据。它能够实现快速顺序读写,慢速随机读写。
②固态硬盘(又称SSD):无机械装置,数据存储在可持久记忆的硅晶体上,因此可以像内存一样快速随机访问。
在目前的网站应用中,大部分应用访问数据都是随机的,这种情况下SSD具有更好的性能表现,但是性价比有待提升(蛮贵的,么么嗒)。
(2)B+树 vs LSM树
①传统关系型数据库广泛采用B+树,B+树是对数据排好序后再存储,加快数据检索速度。
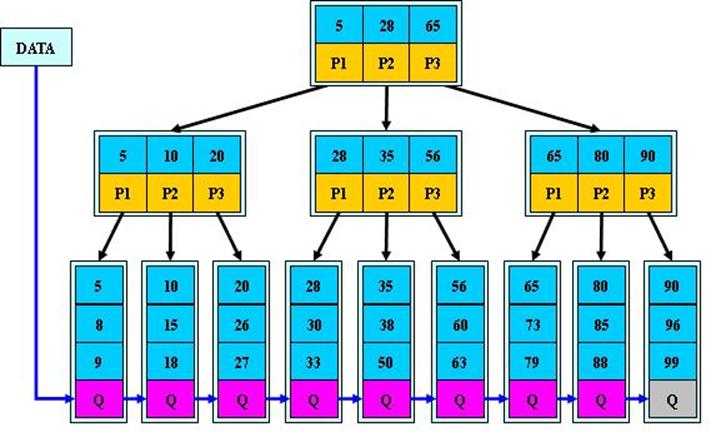
PS:目前大多数DB多采用两级索引的B+树,树的层次最多三层。因此可能需要5次磁盘访问才能更新一条记录(三次磁盘访问获得数据索引及行ID,一次数据文件读操作,一次数据文件写操作,终于知道数据库操作有多麻烦多耗时了)
②NoSQL(例如:HBase)产品广泛采用LSM树:
具体思想是:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘。不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近的修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。
LSM树的原理是:把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会被清除并写入到磁盘中,磁盘中的树定期可以做合并操作,合并成一棵大树,以优化读性能。
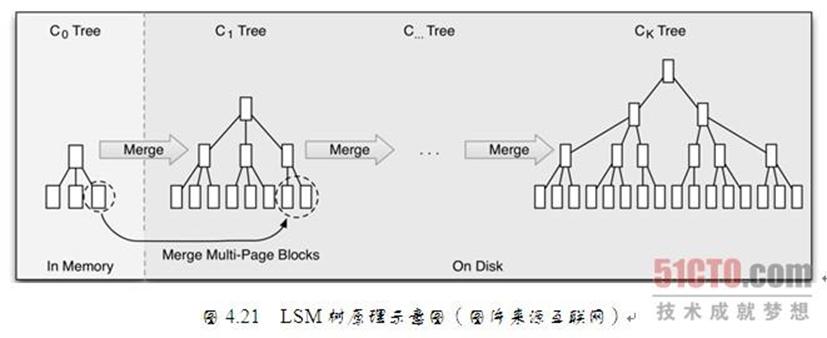
LSM树的优势在于:在LSM树上进行一次数据更新不需要磁盘访问,在内存即可完成,速度远快于B+树。
八、学习总结
对于网站的高性能架构这一章的阅读,通过大牛的书籍我们学到了从三个主要方面的性能优化策略,虽然都是理论,而且还只是浅显地说明,但是对于我们这些广大的开发菜鸟来说,扩展知识面,了解一点优化策略不是一件坏事,我们可以从中注意到日常的代码规范,如何写出高效的代码也是一件值得研究的事儿。在书中,看到了作者写了这样一句话,贴出来与各位正在学习途中的菜鸟们共享:"归根结底,技术是为业务服务的,技术选型和架构决策依赖业务规划乃至企业战略规划,离开业务发展的支撑和驱动,技术走不远,甚至还会迷路"。出来实习了一年多,对这句话感慨颇多,也吃了很多的亏,在和客户的沟通交流上也有了自己的一点感悟,所以贴出来与各位园友共勉。最后,希望作为菜鸟的我们,在技术这条路上能够走得远一些,迷路不重要,重要的是能够迷途知返,么么嗒!再过一个多月,就要开始找工作了,希望在此期间能够认真阅读完自己的计划书单,加油!
参考文献
(1)李智慧,《大型网站技术架构-核心原理与案例分析》,http://item.jd.com/11322972.html
(2)周言之,《Memcached详解》,http://blog.csdn.net/zlb824/article/details/7466943
(3)百度百科,CDN,http://baike.baidu.com/view/8689800.htm
(4)王晨纯,《Web基础架构:负载均衡和LVS》,http://www.importnew.com/11229.html
(5)辉之光,《B树、B-树、B+树》,http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
(6)yanghuahui's blog,《LSM树由来、设计思想以及应用到HBase的索引》,http://www.cnblogs.com/yanghuahui/p/3483754.html
本章思维导图
声明
部分内容转载自http://www.cnblogs.com/edisonchou/博客