上一节中,我们利用了预训练的VGG网络卷积基,来简单的提取了图像的特征,并用这些特征作为输入,训练了一个小分类器。
这种方法好处在于简单粗暴,特征提取部分的卷积基不需要训练。但缺点在于,一是别人的模型是针对具体的任务训练的,里面提取到的特征不一定适合自己的任务;二是无法使用图像增强的方法进行端到端的训练。
因此,更为常用的一种方法是预训练模型修剪 + 微调,好处是可以根据自己任务需要,将预训练的网络和自定义网络进行一定的融合;此外还可以使用图像增强的方式进行端到端的训练。仍然以VGG16为例,过程为:
- 在已经训练好的基网络(base network)上添加自定义网络;
- 冻结基网络,训练自定义网络;
- 解冻部分基网络,联合训练解冻层和自定义网络。
注意在联合训练解冻层和自定义网络之前,通常要先训练自定义网络,否则,随机初始化的自定义网络权重会将大误差信号传到解冻层,破坏解冻层以前学到的表示,使得训练成本增大。
第一步:对预训练模型进行修改
##################第一步:在已经训练好的卷积基上添加自定义网络######################
import numpy as np
from keras.applications.vgg16 import VGG16
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
#搭建模型
conv_base = VGG16(include_top=False, input_shape=(150,150,3)) #模型也可以看作一个层
model = Sequential()
model.add(conv_base)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
#model.summary()
第二步:冻结卷积基,训练自定义网络
######################第二步:冻结卷积基,训练自定义网络##########################
#冻结卷积基,确保结果符合预期。或者用assert len(model.trainable_weights) == 30来验证
print("冻结之前可训练的张量个数:", len(model.trainable_weights)) #结果为30
conv_base.trainable = False
print("冻结之后可训练的张量个数:", len(model.trainable_weights)) #结果为4
#注:只有后两层Dense可以训练,每层一个权重张量和一个偏置张量,所以有4个
#利用图像生成器进行图像增强
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255) #验证、测试的图像生成器不能用图像增强
train_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-small rain'
validation_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-smallvalidation'
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
#模型编译和训练,注意修改trainable属性之后需要重新编译,否则修改无效
from keras import optimizers
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
H = model.fit_generator(train_generator,
steps_per_epoch=2000/20,
epochs=30,
validation_data=validation_generator,
validation_steps=1000/20)
训练30个epoch之后,结果如图所示。(结果可视化代码见上一节)

第三步:解冻部分卷积基(第5个block),联合训练
通常keras的冻结和解冻操作用的是模型或层的trainable属性。需要注意三点:
- model.trainable是全局属性,layer.trainable是层的属性,单独定义层的这一属性后全局属性即失效;
- 定义这一属性后,模型需要重新编译才能生效;
- conv_base是一个模型,但它在总模型model中是作为一个层的实例,因此遍历model.layers时会把conv_base作为一个层,如果需要深入conv_base内部各层进行操作,需要遍历conv_base.layers。
为了确保trainable属性符合预期,通常会确认一下,下面一些代码可能会有用。(这段主要是便于理解,跑代码时可选择性忽略这段。)
#可视化各层序号及名称
for i, layer in enumerate(model.layers):
print(i, layer.name)
for i, layer in enumerate(conv_base.layers):
print(i, layer.name)
#由于之前操作错误,导致模型全部层都被冻结,所以这个模块先把所有层解冻
for layer in conv_base.layers: #先解冻卷积基中所有层的张量
layer.trainable = True
for layer in model.layers: #解冻model中所有层张量
layer.trainable = True
#查看各层的trainable属性
for layer in model.layers:
print(layer.name, layer.trainable)
for layer in conv_base.layers:
print(layer.name, layer.trainable)
#model.trainable = True #注意:设定单独层的trainable属性后,全局trainable属性无效
print(len(conv_base.trainable_weights)) #26
print(len(model.trainable_weights)) #30
经过第二步之后,卷积基被冻结,后两层Dense可训练。接下来正式开始第三步,解冻第5个block,联合训练解冻层和自定义网络。
######################第三步:解冻部分卷积基,联合训练##########################
#冻结VGG16中前四个block,解冻第五个block
flag = False #标记是否到达第五个block
for layer in conv_base.layers: #注意不是遍历model.layers
if layer.name == 'block5_conv1': #若到达第五个block,则标记之
flag = True
if flag == False: #若标记为False,则冻结,否则设置为可训练
layer.trainable = False
else:
layer.trainable = True
print(len(model.trainable_weights)) #应为10
#重新编译并训练。血泪教训,一定要重新编译,不然trainable属性就白忙活了!
from keras import optimizers
#注:吐血,官网文档参数learning_rate,这里竟然不认,只能用lr
model.compile(loss='binary_crossentropy',
optimizer=optimizers.Adam(lr=1e-5), metrics=['accuracy'])
H2 = model.fit_generator(train_generator,
steps_per_epoch=2000/20,
epochs=100,
validation_data=validation_generator,
validation_steps=1000/20)
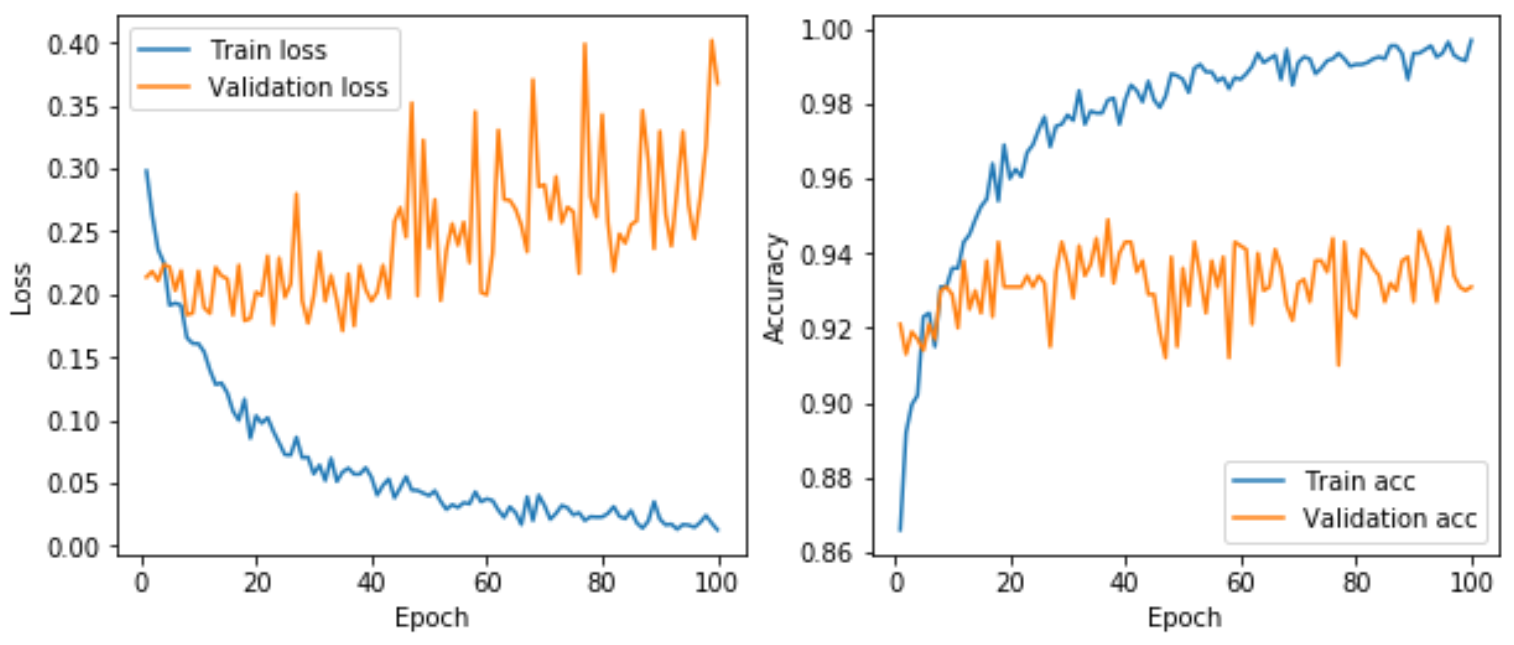
经过100个epoch之后,结果如下。可以看出验证准确率被提高到94%左右。
Reference:
书籍:Python深度学习