前言
上篇文章主要介绍了在全链路压测准备阶段,最核心的一点:核心链路相关的知识。
梳理核心链路的一个重要目的是获得流量模型。但在全链路压测中,除了流量模型,业务模型和数据模型一样重要。
这篇文章,为大家介绍如何构建这三大模型。
业务场景模型
前文中有提到:核心业务对应的核心应用中,保证达成企业利润实现的最主要请求流量经过的路径,即是核心链路。
理解这句话之后,就能很好的理解业务场景模型了。下图是一个常见的电商双11大促时候的业务场景模型图,我以这个思维导图为例来做分析说明。
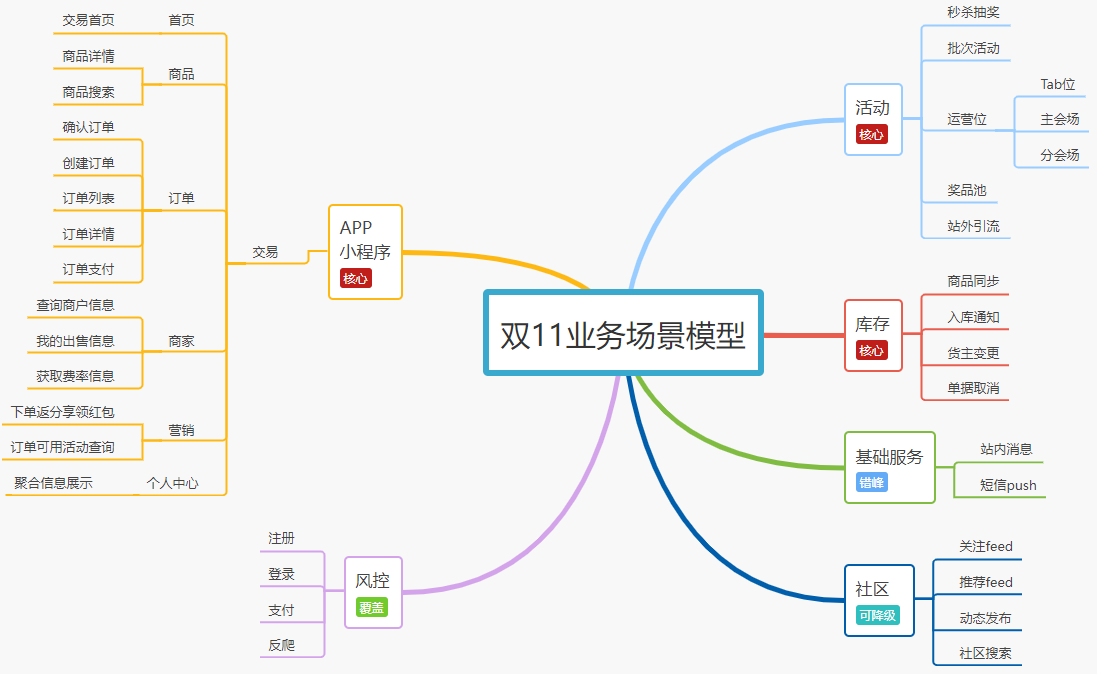
一般来说梳理业务场景模型大概有如下几个步骤:
- 根据业务特性和业务确定本次大促主要涉及的业务范围(如电商一般是交易、活动和库存业务);
- 确定大促涉及的业务范围中,对应的核心业务各有哪些(这里要对业务进一步的细化,如上图);
- 根据梳理出来的核心业务场景,进一步的进行打标赋权(假设流量过高或特殊情况,哪些可以放弃);
PS:上面提到的细化业务场景以及打标签赋予权重,是为了更明确的知道,哪些是最核心不能出问题的场景;
峰值流量模型
预估的流量模型要以峰值流量场景来预估,否则很可能由于错误的预估导致准备不足而致使大促期间线上出现问题。
峰值流量模型的预估,不仅是一个技术和监控的问题,还要综合考虑本次大促期间业务目标以及业务转化率的因素。举个例子:
业务目标:双11当天,预估平均客单价为500,单日GMV为10亿,那么支付订单量为10亿/500=200W;
转化技术指标:
1)假设日常支付订单量为50W,支付转化率为40%,订单支付QPS峰值为200。预估大促时的支付转化率为60%,
则可得:大促峰值订单支付QPS为(200/40%)*60%*(200W/50W)=1200QPS。这个1200QPS是个保底数值,一般为了留有一定冗余空间,会上浮30%,即订单支付的QPS预估为1500;
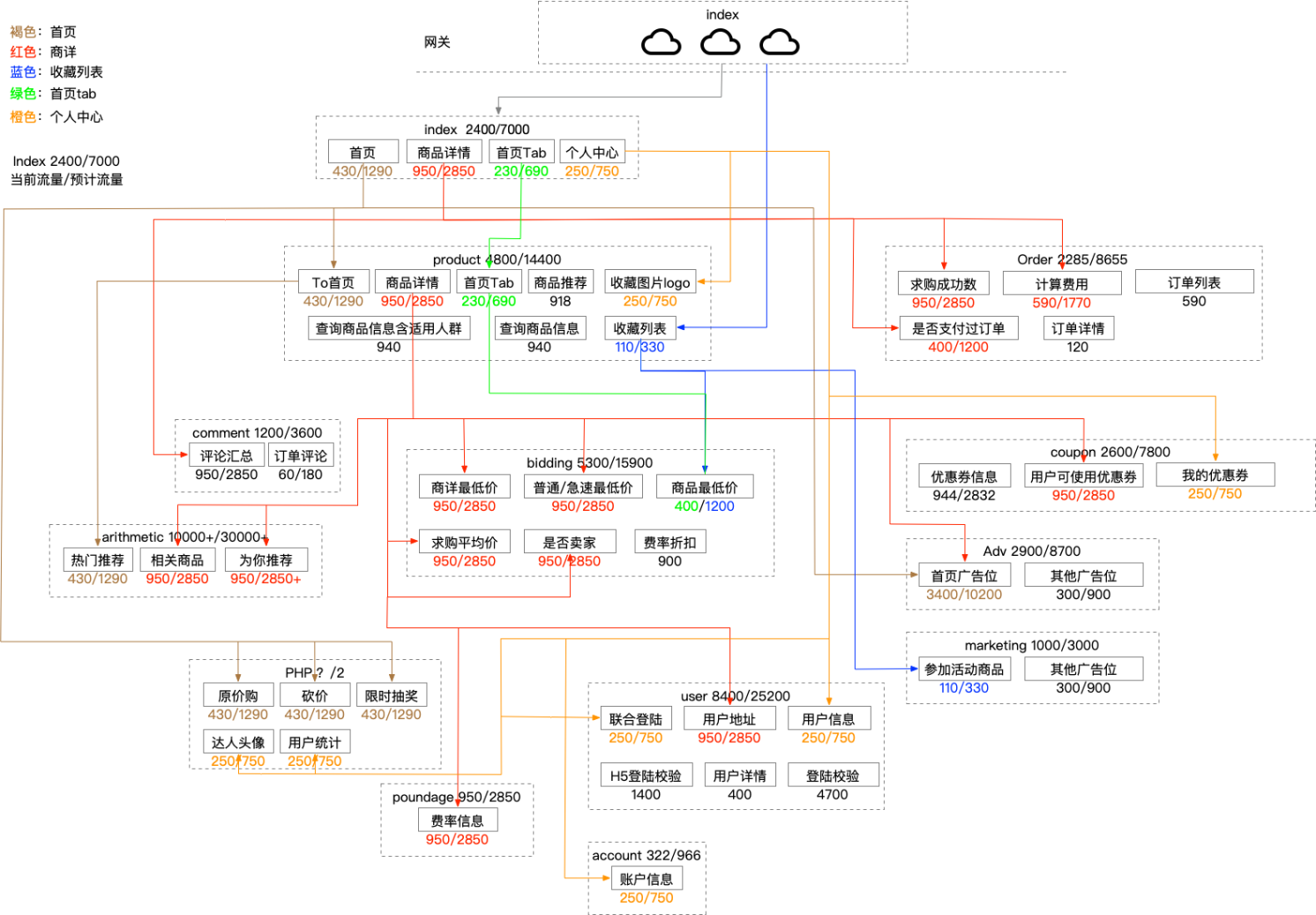
2)电商的导购浏览下单支付转化链路一般为:首页→商品详情→创建订单→订单支付→支付成功,这个过程是类似漏斗的一个转化逻辑。
假设首页→商品详情转化率为40%,商品详情→创建订单转化率为40%,创建订单→订单支付转化率为40%,那么可得:创建订单QPS为1500/40%=3750,商品详情QPS为3750/40%=9375,首页QPS为9375/40%=23437;
3)按照核心链路之间的依赖调用关系,借助监控和trace追踪,最终得到本次大促期间,所有涉及的核心应用及核心链路的QPS数值。
最终我们会得到类似如下的一个流量模型图:
压测数据模型
关于压测数据模型,实际上可以分为2个部分:压测模型和数据模型。
压测模型
以我个人经验,压测模型主要可以从如下几个维度去划分:
1.单机单接口基准(接口级别)
单机单接口的压测,可以通过梯度增加请求的方式,观察随着请求的增加,其性能表现&资源损耗的变化。
在目前的微服务架构下,整体链路的性能瓶颈,取决于短板(木桶原理)。因此,单机单链路基准测试的目的,是在全链路压测开始前进行性能摸底,定位排查链路瓶颈。
2.单机混合链路场景(服务级别)
单机混合场景,大多还是通过梯度增加请求的方式,观察服务级别的性能表现。
单机混合链路压测的目的,是排查上下游调用依赖的瓶颈,并以此测试结果作为限流预案的基准值。
重点关注3个指标:
- 安全水位(CPU50%)
- 告警水位(CPU70%)
- 最大水位(CPU≥90%&Load5≥150%)
3.生产全链路压测场景(生产集群)
针对生产集群的全链路压测,需要涉及的压测模型较多,一般有如下几种:
①.梯度加压模型:主要为了探测集群模式下系统的最大吞吐量(也避免压垮服务,造成事故);
②.固定并发模型:验证系统长期处于负载下的稳定性;
③.脉冲并发模型:探测系统的健壮性、验证限流熔断等服务保护措施的正确性&可用性;
④.超卖验证模型:对电商业务来说,主要针对一些限时抢购&秒杀的场景;一般这种场景,会涉及到分布式锁、
缓存、数据一致性等技术点;玩不好的话,容易造成客诉、资损、甚至服务异常宕机!
数据模型
聊完了压测模型,接着聊聊数据模型。数据场景,很多时候往往被忽视,但实际上数据场景更加重要。
如果测试过程中采用的数据不准确,那测试结果往往出现较大偏差。关于测试所需数据,可参考如下几点:
|
数据信息 |
说明 |
|
限制条件 |
用户操作权限、数据引用次数、数据过期设定(次数、绝对时间) |
|
数据量 |
实际生产环境的数据量为多少,在性能测试环境如何等量代换 |
|
数据类型 |
基础数据、热点数据、缓存数据、特殊数据 |
|
数据特点 |
是否可以复用、是否具有唯一性、自增、加密、拼接、转义等 |
|
准备方式 |
copy真实环境数据、预埋铺底数据、脱敏生成数据 |
|
隔离方案 |
如何避免测试数据的污染?影子库?环境隔离?标记区分? |
以我个人经验,数据模型中测试数据主要分为如下几种类型:
基础数据:也称之为铺底数据,铺底数据目的是与线上保持一致(至少数量级一致),再结合线上增长率,确认预埋数据量级及预埋方式。
涉及到压测时需要校验的数据,需要在铺底的时候就要精细化的设计,包括数据大小,数量,分布等。
热点数据:需要了解被测接口的实现逻辑,确认以下信息:
是否有热点数据相关的操作:比如说所有用户秒杀同一件商品;
不同类型数据处理逻辑有差异时,需通过测试数据多样化提高性能测试代码覆盖率;
缓存数据:要确认是否有缓存,缓存大小为多少(排除大key,一般来说142W的key占Redis一个G的内存);
秒杀抢购相关数据,一般来说都是进行队列处理,将该类型数据放入缓存中进行处理来应对高并发。
再比如用户登录所需的token等数据,在生产压测时,需要提前将其预热到缓存中,避免压测时用户服务成为瓶颈;