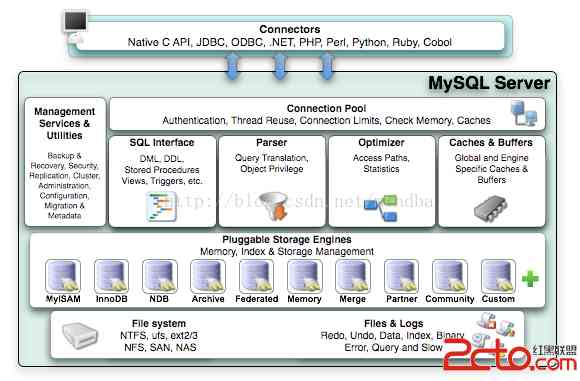
mysql由以下几个部分组成:
连接池组件
管理服务和工具组件
sql接口组价
查询分析器组价
优化器组价
缓存(cache)组价
插件式存储引擎
物理文件。
可以看出,MySQL数据库区别于其他数据库的最重要的一个特点就是其插件式的表存储引擎。存储引擎是基于表的,而不是数据库。是底层物理结构的实现,每个存储引擎开发者可以按照自己的意愿来开发。
mysql数据库的核心在于存储引擎。innodb甚至是mysql数据库OLTP应用中使用最广泛的存储引擎。
InnoDB存储引擎:
第一个完整支持ACID事务MYSQL存储引擎
设计目标主要是在线事务处理。特点:行锁设计、支持外键,并支持类似于Oracle的非锁定读,即默认读取操作不会产生锁。通过多版本并发控制来获得高并发性,并且实现了SQL标志的4种隔离级别,默认为repeatable级别。使用一种next-key-locking的策略来避免幻读,此外innoDB提供了插入缓冲、二次写、自适应哈希索引、预读等高性能和高可用的功能。表中数据的存储采用了聚集方式,因此每张表的存储都是按照主键的顺序进行存放。没有显示定义主键的话,innoDB会为每一行生成一个6自己的ROWID,并以此为主键。
MYISAM:
不支持事务,表锁设计,支持全文索引,只要面向一些OLAP的数据库应用。缓冲池只缓存索引文件,而不是数据文件,这点和大多数的数据库都非常不同。
InnoDB体系架构:
1.后台线程:
1)master Thread
2)IO Thread
3)Purge Thread
4)Page Cleaner Thread
2.内存
1)缓冲池
2)LRU List、Free List和Flush List
3)重做日志缓冲
4)额外的内存池
NDB:
是一个集群存储引擎,类似于Oracle的RAC集群。NDB的特点使数据全部放在内存中(5.1以后可以将非索引数据放在磁盘上),因此主键查找的速度极快,并且通过添加NDB数据存储节点可以先行地提高数据库性能,是高可用、高性能的集群系统。ndb的链接操作join实在mysql数据库层完成的,而不是存储引擎层,意味着负责连接操作需要巨大的网络开销,查询速度很慢。
memory存储引擎:
将表中的数据存放在内存中,如果数据重启或发生崩溃,表中的数据将消失。非常适合存储临时数据的临时表,以及数据仓库中的维度表。默认使用哈希索引,而不是我们熟悉的B+数索引。虽然速度快,只支持表锁,并发性能较差,并且不支持text和bolb类型。存储变长字段varchar是按照定长字段(char)的方式进行的,因此会浪费内存。
Achive存储引擎:
只支持insert和select。5.1以后开始支持索引。使用zlib算法将数据行进行压缩后存储,压缩比一般可达1:10,。非常适合存储归档信息,如日志信息。使用行锁来实现高并发的插入操作,但是其本身并不是事务安全的存储引擎,其设计目标主要是提高告诉的插入和压缩功能。
Federated存储引擎:
并不存储表,只是指向一台远程MySQL数据库服务器上的表。
Maria存储引擎:
新开发的引擎,可以看成是myisam的后续版本。特点:支持缓存数据和索引文件,应用了行锁设计,提供了mvcc功能,支持事务和非事务安全的选项,以及更好的BLOB字符类型的处理性能。
第四章 表
4.1索引组织表
1)首先判断表中是否有非空的唯一索引。如果有,则该列即为主键。
2)如果不符合上述条件,innodb存储引擎自动创建一个六字节大小的指针。
当表中多个非空唯一索引时。inndb存储引擎将选择见表时第一个定义的非空唯一索引主键
4.7视图
在MySQL中,视图是一个命名的虚表,它由一个sql查询来定义,可以当做表使用。与持久表不同的是,视图中的数据没有实际的物理存储。
视图的作用:被当做一个抽象装置,特别是对于一些应用程序,程序本身不需要关心基表的结构,只需要按照视图定义来取数据或更新数据,因此在一定程度上起到一个安全层的作用。
4.8分区表
分区功能并不是在存储引擎层完成的,因此不是只有innoDB才支持分区,常见的存储引擎innoDB、myisam、nbd都支持,有些如csv、fedorated、merge等不支持。
分区:将一个表或索引分解为更小、更可管理的部分。逻辑上来讲,只有一个表或索引,但是物理上这个表或索引可能由数十个物理分区组成。MySQL支持水平分区,不支持垂直分区。此外,MySQL数据库的分区是局部分区索引,一个分区中既放了数据又放了索引。而全局分区是指,数据存放在各个分区中,但是索引数据的索引放在一个对象中。MySQL暂时不支持全局分区。
分区类型:range分区、List分区、Hash分区、key分区、column分区。
一般情况下:OLAP应用如数据仓库、数据集市,分区的确是可以很好的挺高查询的性能,因为OLAP应用大多数查询需要频繁地扫描一张很大的表。对于OLTP应用,分区应该格外小心。B+树索引可以很好的完成操作,不需要分区的帮助,并且设计不好的分区会带来严重的性能问题。
第5章 索引
索引太多,应用程序的性能可能会受到影响。而索引太少,对查询性能又会产出影响,要找到一个平衡点。
innoDB支持的索引:
B+树索引
全文索引
哈希索引:innoDB支持的哈希索引是自适应的,会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在一张表中生成哈希索引。
B+树:并不能找到一个给定健值的具体行,能找到的知识被查找数据行所在的页。然后数据库通过页读入到内存,再在内存中进行查找,最后得到要查找的数据。是目前关系型数据库系统中查找最为常用和最有效的索引。
B+树索引分为聚集索引和辅助索引。叶子节点存放着索引的数据。聚集索引与辅助索引不同的是,叶子节点存放的是否是一整行的信息。
聚集索引:按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点成为数据页。聚集索引的这个特征决定了索引组织表中数据也是索引的一部分。每张表只能有一个聚集索引。在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。由于定义了数据的逻辑结构,聚集索引能够特别快的访问针对范围值的查询。
辅助索引(非聚集索引):叶子节点并不包含行记录的全部数据。