学习了两周PaddlePaddle,刚开始都是比较简单的网络,直到遇到YoloV3这个大家伙,它的程序内容涉及图像增广(训练数据扩充),锚框生成(以及微调),候选区域生成、目标标注、特征提取、特征位置对应、损失函数构建、多尺度检测等等,最终构成的是一个end2end的目标识别程序。我并没有看原论文,直接按照Paddle课程中的ipython notebook过了一遍,把碰到的难点全部记录下来。
一、目标检测及相关著名模型

目标检测是图像识别的升级版,需要识别出图片中包含的物体(多种物体),并且标注出位置信息(用框标出来)。如果目标检测算法足够快,便可处理视频帧,做到视频目标检测。
用最基本的方法,记得吴恩达的机器学习公开课上提过,假设我们已经有了用于图像识别的模型,但是无法标注出位置信息,我们可以使用不同大小的滑动窗口,在输入图片上进行滑动(从左到右从上往下全覆盖,并且使用多种尺寸的滑动窗口),判断目标并得到位置。但这样计算量太大了,没法使用。
所以新的目标检测算法,会生成可能包含物体的候选区域,只在候选区域上进行识别。著名的算法有利用Selective Search的R-CNN,Fast R-CNN、使用RPN的Faster R-CNN,Mask R-CNN等。
YoloV3算法只使用一个网络同时产生候选区域并预测出物体的类别和位置,叫做单阶段检测算法。
二、基础知识、术语等概念

在图片中,把物体框出来的方框,叫做bounding box 边界框,一个方框可用两种表达方式记录,一般叫做xyxy(记录方框最上角和右下角的坐标)和xywh(记录方框中心坐标及长度和宽度)。
训练集中,真实的包含目标的方框(一般是人工标注的)叫做ground truth box,真实框;模型预测出来的框叫prediction box预测框。
还有一种框,是人们假想出来的框,也可以是随机生成的框,叫做锚框(anchor box),图像识别就发生在锚框里。
# 绘制锚框
def draw_anchor_box(center, length, scales, ratios, img_height, img_width):
"""
以center为中心,产生一系列锚框
其中length指定了一个基准的长度
scales是包含多种尺寸比例的list
ratios是包含多种长宽比的list
img_height和img_width是图片的尺寸,生成的锚框范围不能超出图片尺寸之外
"""
bboxes = []
for scale in scales:
for ratio in ratios:
h = length*scale*math.sqrt(ratio)
w = length*scale/math.sqrt(ratio)
x1 = max(center[0] - w/2., 0.)
y1 = max(center[1] - h/2., 0.)
x2 = min(center[0] + w/2. - 1.0, img_width - 1.0)
y2 = min(center[1] + h/2. - 1.0, img_height - 1.0)
print(center[0], center[1], w, h)
bboxes.append([x1, y1, x2, y2])
for bbox in bboxes:
draw_rectangle(currentAxis, bbox, edgecolor = 'b')
蓝色方框就是生成的3个不同长宽比的锚框。

交并比(Intersection of Union)
这是个非常重要的概念,用来计算两个方框的重合程度,公式为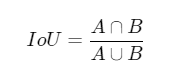
 ,
,
计算结果是0-1之间的,越大说明重合度越高,它的代码实现也很机智,包含了所有可能的情况。

# 计算IoU,矩形框的坐标形式为xyxy,这个函数会被保存在box_utils.py文件中
def box_iou_xyxy(box1, box2):
# 获取box1左上角和右下角的坐标
x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]
# 计算box1的面积
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
# 获取box2左上角和右下角的坐标
x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]
# 计算box2的面积
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
# 计算相交矩形框的坐标
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
# 计算相交矩形行的高度、宽度、面积
inter_h = np.maximum(ymax - ymin + 1., 0.)
inter_w = np.maximum(xmax - xmin + 1., 0.)
intersection = inter_h * inter_w
# 计算相并面积
union = s1 + s2 - intersection
# 计算交并比
iou = intersection / union
return iou
# 计算IoU,矩形框的坐标形式为xywh
def box_iou_xywh(box1, box2):
x1min, y1min = box1[0] - box1[2]/2.0, box1[1] - box1[3]/2.0
x1max, y1max = box1[0] + box1[2]/2.0, box1[1] + box1[3]/2.0
s1 = box1[2] * box1[3]
x2min, y2min = box2[0] - box2[2]/2.0, box2[1] - box2[3]/2.0
x2max, y2max = box2[0] + box2[2]/2.0, box2[1] + box2[3]/2.0
s2 = box2[2] * box2[3]
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
inter_h = np.maximum(ymax - ymin, 0.)
inter_w = np.maximum(xmax - xmin, 0.)
intersection = inter_h * inter_w
union = s1 + s2 - intersection
iou = intersection / union
return iou
三、虫子识别数据集、及图像增广
这个数据集给了train val test 三部分数据,其中train和val包含xml格式的标注信息,标注信息其实就是虫子的ground truth box(简称gtbox)坐标及虫子类别(一共6类),画出来如下图。
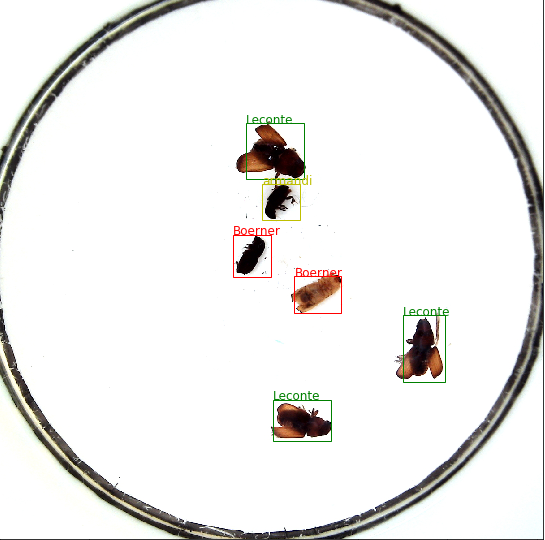
为了模拟真实环境,需要对训练集做一些增广处理,扩大了数据集,抑制过拟合,提高泛化能力。
(1)随机改变亮暗、对比度和颜色等
import numpy as np
import cv2
from PIL import Image, ImageEnhance
import random
# 随机改变亮暗、对比度和颜色等
def random_distort(img):
# 随机改变亮度
def random_brightness(img, lower=0.5, upper=1.5):
e = np.random.uniform(lower, upper)
return ImageEnhance.Brightness(img).enhance(e)
# 随机改变对比度
def random_contrast(img, lower=0.5, upper=1.5):
e = np.random.uniform(lower, upper)
return ImageEnhance.Contrast(img).enhance(e)
# 随机改变颜色
def random_color(img, lower=0.5, upper=1.5):
e = np.random.uniform(lower, upper)
return ImageEnhance.Color(img).enhance(e)
ops = [random_brightness, random_contrast, random_color]
np.random.shuffle(ops)
img = Image.fromarray(img)
img = ops[0](img)
img = ops[1](img)
img = ops[2](img)
img = np.asarray(img)
return img
由于没有改变图像大小,所以原物体分类、位置标注信息不变。
示例图如下: