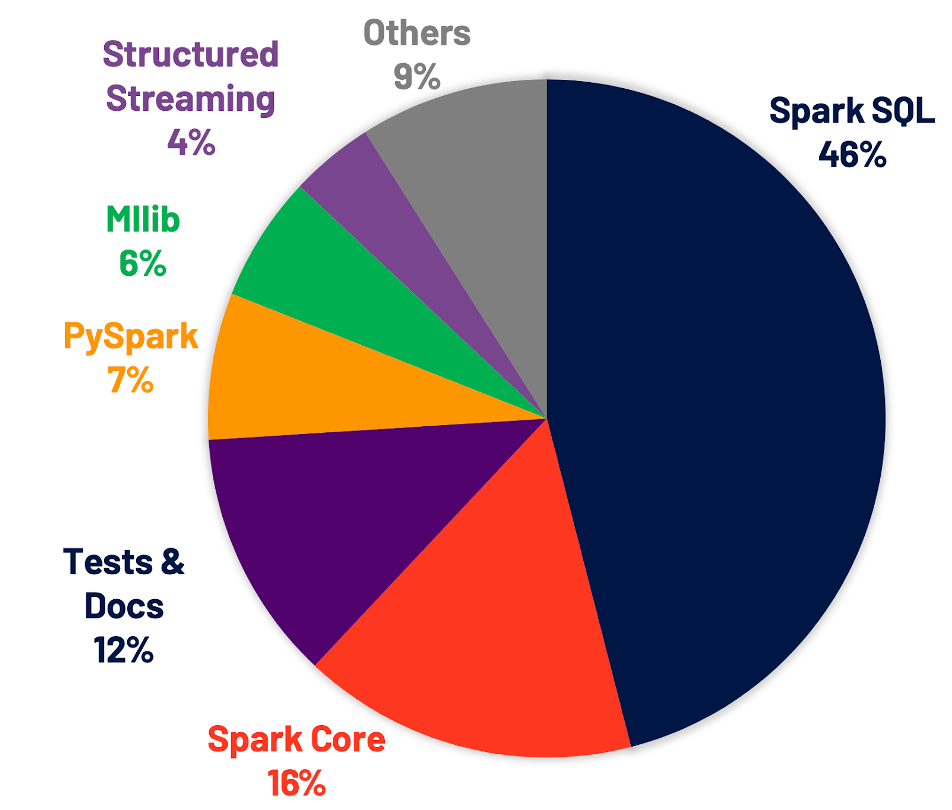
Spark3.0已经发布半年之久,这次大版本的升级主要是集中在性能优化和文档丰富上,其中46%的优化都集中在Spark SQL上,SQL优化里最引人注意的非Adaptive Query Execution莫属了。
Adaptive Query Execution(AQE)是英特尔大数据技术团队和百度大数据基础架构部工程师在Spark 社区版本的基础上,改进并实现的自适应执行引擎。近些年来,Spark SQL 一直在针对CBO 特性进行优化,而且做得十分成功。
CBO基本原理
首先,我们先来介绍另一个基于规则优化(Rule-Based Optimization,简称RBO)的优化器,这是一种经验式、启发式的优化思路,优化规则都已经预先定义好,只需要将SQL往这些规则上套就可以。简单的说,RBO就像是一个经验丰富的老司机,基本套路全都知道。
然而世界上有一种东西叫做 – 不按套路来。与其说它不按套路来,倒不如说它本身并没有什么套路。最典型的莫过于复杂Join算子优化,对于这些Join来说,通常有两个选择题要做:
-
Join应该选择哪种算法策略来执行?BroadcastJoin or ShuffleHashJoin or SortMergeJoin?不同的执行策略对系统的资源要求不同,执行效率也有天壤之别,同一个SQL,选择到合适的策略执行可能只需要几秒钟,而如果没有选择到合适的执行策略就可能会导致系统OOM。
-
对于雪花模型或者星型模型来讲,多表Join应该选择什么样的顺序执行?不同的Join顺序意味着不同的执行效率,比如A join B join C,A、B表都很大,C表很小,那A join B很显然需要大量的系统资源来运算,执行时间必然不会短。而如果使用A join C join B的执行顺序,因为C表很小,所以A join C会很快得到结果,而且结果集会很小,再使用小的结果集 join B,性能显而易见会好于前一种方案。
大家想想,这有什么固定的优化规则么?并没有。说白了,你需要知道更多关于表的基础信息(表大小、表记录总条数等),再通过一定规则代价评估才能从中选择一条最优的执行计划。所以,CBO 意为基于代价优化策略,它需要计算所有可能执行计划的代价,并挑选出代价最小的执行计划。
AQE对于整体的Spark SQL的执行过程做了相应的调整和优化,它最大的亮点是可以根据已经完成的计划结点真实且精确的执行统计结果来不停的反馈并重新优化剩下的执行计划。
CBO这么难实现,Spark怎么解决?
CBO 会计算一些和业务数据相关的统计数据,来优化查询,例如行数、去重后的行数、空值、最大最小值等。Spark会根据这些数据,自动选择BHJ或者SMJ,对于多Join场景下的Cost-based Join Reorder,来达到优化执行计划的目的。
但是,由于这些统计数据是需要预先处理的,会过时,所以我们在用过时的数据进行判断,在某些情况下反而会变成负面效果,拉低了SQL执行效率。
Spark3.0的AQE框架用了三招解决这个问题:
- 动态合并shuffle分区(Dynamically coalescing shuffle partitions)
- 动态调整Join策略(Dynamically switching join strategies)
- 动态优化数据倾斜Join(Dynamically optimizing skew joins)
下面我们来详细介绍这三个特性。
动态合并 shuffle 的分区
在我们处理的数据量级非常大时,shuffle通常来说是最影响性能的。因为shuffle是一个非常耗时的算子,它需要通过网络移动数据,分发给下游算子。
在shuffle中,partition的数量十分关键。partition的最佳数量取决于数据,而数据大小在不同的query不同stage都会有很大的差异,所以很难去确定一个具体的数目:
- 如果partition过少,每个partition数据量就会过多,可能就会导致大量数据要落到磁盘上,从而拖慢了查询。
- 如果partition过多,每个partition数据量就会很少,就会产生很多额外的网络开销,并且影响Spark task scheduler,从而拖慢查询。
为了解决该问题,我们在最开始设置相对较大的shuffle partition个数,通过执行过程中shuffle文件的数据来合并相邻的小partitions。
例如,假设我们执行SELECT max(i) FROM tbl GROUP BY j,表tbl只有2个partition并且数据量非常小。我们将初始shuffle partition设为5,因此在分组后会出现5个partitions。若不进行AQE优化,会产生5个tasks来做聚合结果,事实上有3个partitions数据量是非常小的。
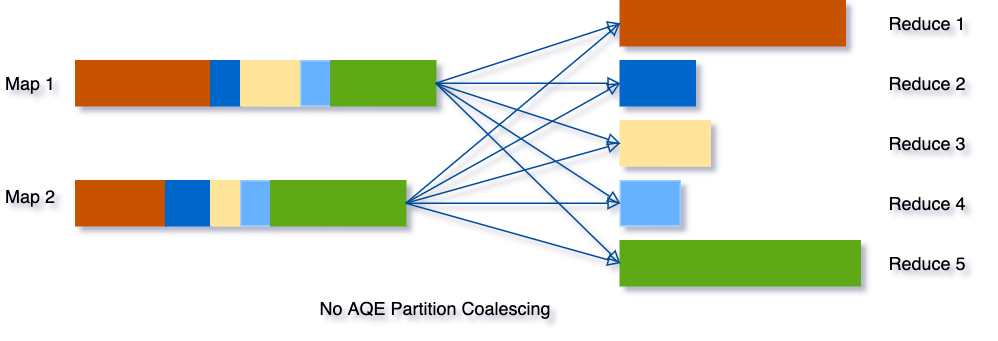
然而在这种情况下,AQE只会生成3个reduce task。

动态切换join策略
Spark 支持许多 Join 策略,其中 broadcast hash join 通常是性能最好的,前提是参加 join 的一张表的数据能够装入内存。由于这个原因,当 Spark 估计参加 join 的表数据量小于广播大小的阈值时,其会将 Join 策略调整为 broadcast hash join。但是,很多情况都可能导致这种大小估计出错——例如存在一个非常有选择性的过滤器。
由于AQE拥有精确的上游统计数据,因此可以解决该问题。比如下面这个例子,右表的实际大小为15M,而在该场景下,经过filter过滤后,实际参与join的数据大小为8M,小于了默认broadcast阈值10M,应该被广播。
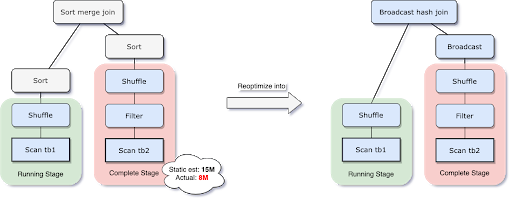
在我们执行过程中转化为BHJ的同时,我们甚至可以将传统shuffle优化为本地shuffle(例如shuffle读在mapper而不是基于reducer)来减小网络开销。
动态优化数据倾斜
Join里如果出现某个key的数据倾斜问题,那么基本上就是这个任务的性能杀手了。在AQE之前,用户没法自动处理Join中遇到的这个棘手问题,需要借助外部手动收集数据统计信息,并做额外的加盐,分批处理数据等相对繁琐的方法来应对数据倾斜问题。
数据倾斜本质上是由于集群上数据在分区之间分布不均匀所导致的,它会拉慢join场景下整个查询。AQE根据shuffle文件统计数据自动检测倾斜数据,将那些倾斜的分区打散成小的子分区,然后各自进行join。
我们可以看下这个场景,Table A join Table B,其中Table A的partition A0数据远大于其他分区。
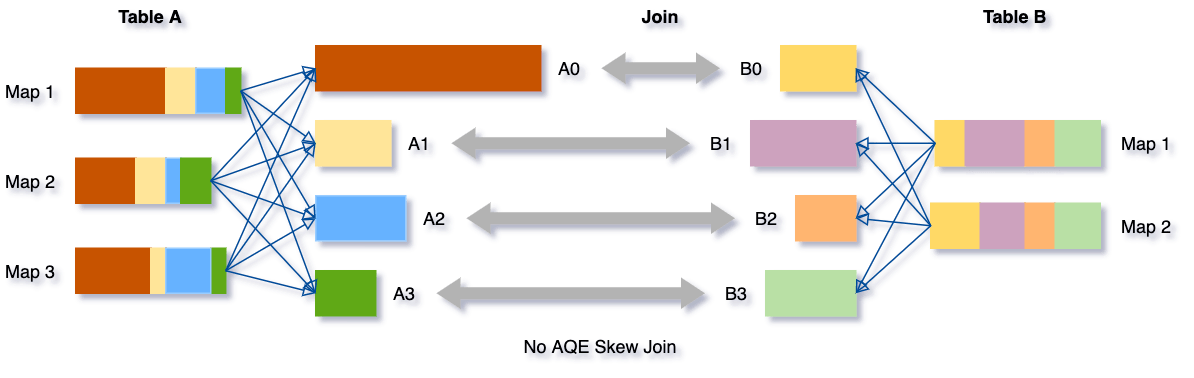
AQE会将partition A0切分成2个子分区,并且让他们独自和Table B的partition B0进行join。
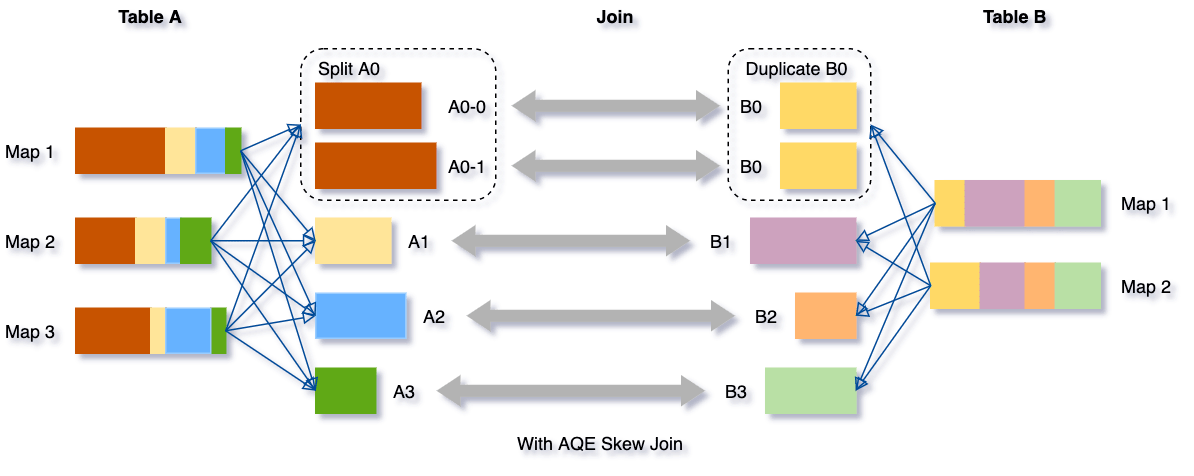
如果不做这个优化,SMJ将会产生4个tasks并且其中一个执行时间远大于其他。经优化,这个join将会有5个tasks,但每个task执行耗时差不多相同,因此个整个查询带来了更好的性能。
如何开启AQE
我们可以设置参数spark.sql.adaptive.enabled为true来开启AQE,在Spark 3.0中默认是false,并满足以下条件:
- 非流式查询
- 包含至少一个exchange(如join、聚合、窗口算子)或者一个子查询
AQE通过减少了对静态统计数据的依赖,成功解决了Spark CBO的一个难以处理的trade off(生成统计数据的开销和查询耗时)以及数据精度问题。相比之前具有局限性的CBO,现在就显得非常灵活。
Spark CBO源码实现
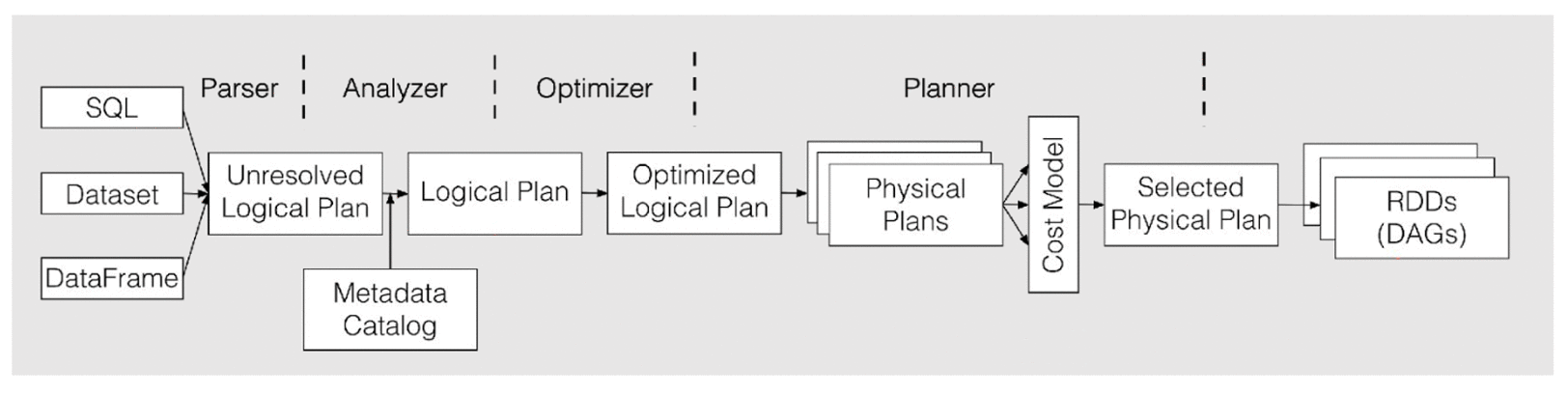
Adaptive Execution 模式是在使用Spark物理执行计划注入生成的。在QueryExecution类中有 preparations 一组优化器来对物理执行计划进行优化, InsertAdaptiveSparkPlan 就是第一个优化器。
InsertAdaptiveSparkPlan 使用 PlanAdaptiveSubqueries Rule对部分SubQuery处理后,将当前 Plan 包装成 AdaptiveSparkPlanExec 。
当执行 AdaptiveSparkPlanExec 的 collect() 或 take() 方法时,全部会先执行 getFinalPhysicalPlan() 方法生成新的SparkPlan,再执行对应的SparkPlan对应的方法。
// QueryExecution类
lazy val executedPlan: SparkPlan = {
executePhase(QueryPlanningTracker.PLANNING) {
QueryExecution.prepareForExecution(preparations, sparkPlan.clone())
}
}
protected def preparations: Seq[Rule[SparkPlan]] = {
QueryExecution.preparations(sparkSession,
Option(InsertAdaptiveSparkPlan(AdaptiveExecutionContext(sparkSession, this))))
}
private[execution] def preparations(
sparkSession: SparkSession,
adaptiveExecutionRule: Option[InsertAdaptiveSparkPlan] = None): Seq[Rule[SparkPlan]] = {
// `AdaptiveSparkPlanExec` is a leaf node. If inserted, all the following rules will be no-op
// as the original plan is hidden behind `AdaptiveSparkPlanExec`.
adaptiveExecutionRule.toSeq ++
Seq(
PlanDynamicPruningFilters(sparkSession),
PlanSubqueries(sparkSession),
EnsureRequirements(sparkSession.sessionState.conf),
ApplyColumnarRulesAndInsertTransitions(sparkSession.sessionState.conf,
sparkSession.sessionState.columnarRules),
CollapseCodegenStages(sparkSession.sessionState.conf),
ReuseExchange(sparkSession.sessionState.conf),
ReuseSubquery(sparkSession.sessionState.conf)
)
}
// InsertAdaptiveSparkPlan
override def apply(plan: SparkPlan): SparkPlan = applyInternal(plan, false)
private def applyInternal(plan: SparkPlan, isSubquery: Boolean): SparkPlan = plan match {
// ...some checking
case _ if shouldApplyAQE(plan, isSubquery) =>
if (supportAdaptive(plan)) {
try {
// Plan sub-queries recursively and pass in the shared stage cache for exchange reuse.
// Fall back to non-AQE mode if AQE is not supported in any of the sub-queries.
val subqueryMap = buildSubqueryMap(plan)
val planSubqueriesRule = PlanAdaptiveSubqueries(subqueryMap)
val preprocessingRules = Seq(
planSubqueriesRule)
// Run pre-processing rules.
val newPlan = AdaptiveSparkPlanExec.applyPhysicalRules(plan, preprocessingRules)
logDebug(s"Adaptive execution enabled for plan: $plan")
AdaptiveSparkPlanExec(newPlan, adaptiveExecutionContext, preprocessingRules, isSubquery)
} catch {
case SubqueryAdaptiveNotSupportedException(subquery) =>
logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} is enabled " +
s"but is not supported for sub-query: $subquery.")
plan
}
} else {
logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} is enabled " +
s"but is not supported for query: $plan.")
plan
}
case _ => plan
}
AQE对Stage 分阶段提交执行和优化过程如下:
private def getFinalPhysicalPlan(): SparkPlan = lock.synchronized {
// 第一次调用 getFinalPhysicalPlan方法时为false,等待该方法执行完毕,全部Stage不会再改变,直接返回最终plan
if (isFinalPlan) return currentPhysicalPlan
// In case of this adaptive plan being executed out of `withActive` scoped functions, e.g.,
// `plan.queryExecution.rdd`, we need to set active session here as new plan nodes can be
// created in the middle of the execution.
context.session.withActive {
val executionId = getExecutionId
var currentLogicalPlan = currentPhysicalPlan.logicalLink.get
var result = createQueryStages(currentPhysicalPlan)
val events = new LinkedBlockingQueue[StageMaterializationEvent]()
val errors = new mutable.ArrayBuffer[Throwable]()
var stagesToReplace = Seq.empty[QueryStageExec]
while (!result.allChildStagesMaterialized) {
currentPhysicalPlan = result.newPlan
// 接下来有哪些Stage要执行,参考 createQueryStages(plan: SparkPlan) 方法
if (result.newStages.nonEmpty) {
stagesToReplace = result.newStages ++ stagesToReplace
// onUpdatePlan 通过listener更新UI
executionId.foreach(onUpdatePlan(_, result.newStages.map(_.plan)))
// Start materialization of all new stages and fail fast if any stages failed eagerly
result.newStages.foreach { stage =>
try {
// materialize() 方法对Stage的作为一个单独的Job提交执行,并返回 SimpleFutureAction 来接收执行结果
// QueryStageExec: materialize() -> doMaterialize() ->
// ShuffleExchangeExec: -> mapOutputStatisticsFuture -> ShuffleExchangeExec
// SparkContext: -> submitMapStage(shuffleDependency)
stage.materialize().onComplete { res =>
if (res.isSuccess) {
events.offer(StageSuccess(stage, res.get))
} else {
events.offer(StageFailure(stage, res.failed.get))
}
}(AdaptiveSparkPlanExec.executionContext)
} catch {
case e: Throwable =>
cleanUpAndThrowException(Seq(e), Some(stage.id))
}
}
}
// Wait on the next completed stage, which indicates new stats are available and probably
// new stages can be created. There might be other stages that finish at around the same
// time, so we process those stages too in order to reduce re-planning.
// 等待,直到有Stage执行完毕
val nextMsg = events.take()
val rem = new util.ArrayList[StageMaterializationEvent]()
events.drainTo(rem)
(Seq(nextMsg) ++ rem.asScala).foreach {
case StageSuccess(stage, res) =>
stage.resultOption = Some(res)
case StageFailure(stage, ex) =>
errors.append(ex)
}
// In case of errors, we cancel all running stages and throw exception.
if (errors.nonEmpty) {
cleanUpAndThrowException(errors, None)
}
// Try re-optimizing and re-planning. Adopt the new plan if its cost is equal to or less
// than that of the current plan; otherwise keep the current physical plan together with
// the current logical plan since the physical plan's logical links point to the logical
// plan it has originated from.
// Meanwhile, we keep a list of the query stages that have been created since last plan
// update, which stands for the "semantic gap" between the current logical and physical
// plans. And each time before re-planning, we replace the corresponding nodes in the
// current logical plan with logical query stages to make it semantically in sync with
// the current physical plan. Once a new plan is adopted and both logical and physical
// plans are updated, we can clear the query stage list because at this point the two plans
// are semantically and physically in sync again.
// 对前面的Stage替换为 LogicalQueryStage 节点
val logicalPlan = replaceWithQueryStagesInLogicalPlan(currentLogicalPlan, stagesToReplace)
// 再次调用optimizer 和planner 进行优化
val (newPhysicalPlan, newLogicalPlan) = reOptimize(logicalPlan)
val origCost = costEvaluator.evaluateCost(currentPhysicalPlan)
val newCost = costEvaluator.evaluateCost(newPhysicalPlan)
if (newCost < origCost ||
(newCost == origCost && currentPhysicalPlan != newPhysicalPlan)) {
logOnLevel(s"Plan changed from $currentPhysicalPlan to $newPhysicalPlan")
cleanUpTempTags(newPhysicalPlan)
currentPhysicalPlan = newPhysicalPlan
currentLogicalPlan = newLogicalPlan
stagesToReplace = Seq.empty[QueryStageExec]
}
// Now that some stages have finished, we can try creating new stages.
// 进入下一轮循环,如果存在Stage执行完毕, 对应的resultOption 会有值,对应的allChildStagesMaterialized 属性 = true
result = createQueryStages(currentPhysicalPlan)
}
// Run the final plan when there's no more unfinished stages.
// 所有前置stage全部执行完毕,根据stats信息优化物理执行计划,确定最终的 physical plan
currentPhysicalPlan = applyPhysicalRules(result.newPlan, queryStageOptimizerRules)
isFinalPlan = true
executionId.foreach(onUpdatePlan(_, Seq(currentPhysicalPlan)))
currentPhysicalPlan
}
}
// SparkContext
/**
* Submit a map stage for execution. This is currently an internal API only, but might be
* promoted to DeveloperApi in the future.
*/
private[spark] def submitMapStage[K, V, C](dependency: ShuffleDependency[K, V, C])
: SimpleFutureAction[MapOutputStatistics] = {
assertNotStopped()
val callSite = getCallSite()
var result: MapOutputStatistics = null
val waiter = dagScheduler.submitMapStage(
dependency,
(r: MapOutputStatistics) => { result = r },
callSite,
localProperties.get)
new SimpleFutureAction[MapOutputStatistics](waiter, result)
}
// DAGScheduler
def submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C],
callback: MapOutputStatistics => Unit,
callSite: CallSite,
properties: Properties): JobWaiter[MapOutputStatistics] = {
val rdd = dependency.rdd
val jobId = nextJobId.getAndIncrement()
if (rdd.partitions.length == 0) {
throw new SparkException("Can't run submitMapStage on RDD with 0 partitions")
}
// We create a JobWaiter with only one "task", which will be marked as complete when the whole
// map stage has completed, and will be passed the MapOutputStatistics for that stage.
// This makes it easier to avoid race conditions between the user code and the map output
// tracker that might result if we told the user the stage had finished, but then they queries
// the map output tracker and some node failures had caused the output statistics to be lost.
val waiter = new JobWaiter[MapOutputStatistics](
this, jobId, 1,
(_: Int, r: MapOutputStatistics) => callback(r))
eventProcessLoop.post(MapStageSubmitted(
jobId, dependency, callSite, waiter, Utils.cloneProperties(properties)))
waiter
}
当前,AdaptiveSparkPlanExec 中对物理执行的优化器列表如下:
// AdaptiveSparkPlanExec
@transient private val queryStageOptimizerRules: Seq[Rule[SparkPlan]] = Seq(
ReuseAdaptiveSubquery(conf, context.subqueryCache),
CoalesceShufflePartitions(context.session),
// The following two rules need to make use of 'CustomShuffleReaderExec.partitionSpecs'
// added by `CoalesceShufflePartitions`. So they must be executed after it.
OptimizeSkewedJoin(conf),
OptimizeLocalShuffleReader(conf),
ApplyColumnarRulesAndInsertTransitions(conf, context.session.sessionState.columnarRules),
CollapseCodegenStages(conf)
)
其中 OptimizeSkewedJoin方法就是针对最容易出现数据倾斜的Join进行的优化:
AQE模式下,每个Stage执行之前,前置依赖Stage已经全部执行完毕,那么就可以获取到每个Stage的stats信息。
当发现shuffle partition的输出超过partition size的中位数的5倍,且partition的输出大于 256M 会被判断产生数据倾斜, 将partition 数据按照targetSize进行切分为N份。
targetSize = max(64M, 非数据倾斜partition的平均大小)。
优化前 shuffle 如下:
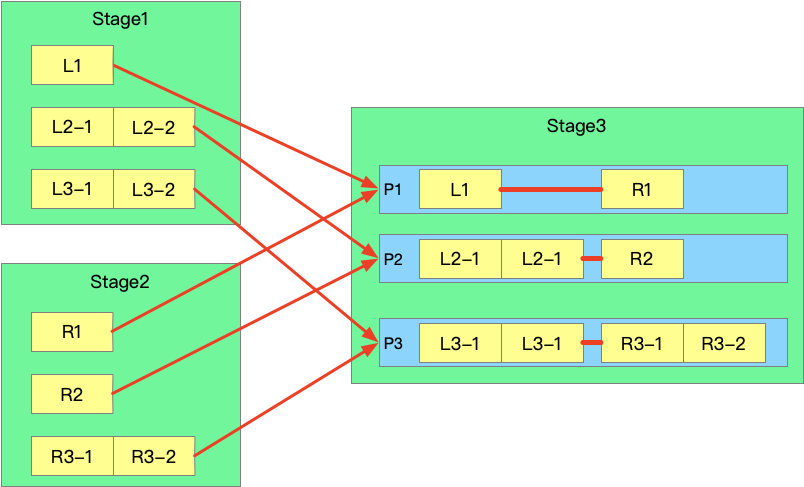
优化后 shuffle:

Spark3.0AQE在FreeWheel的应用与实践
FreeWheel团队通过高效的敏捷开发赶在 2020 年圣诞广告季之前在生产环境顺利发布上线,整体性能提升高达 40%(对于大 batch)的数据,AWS Cost 平均节省 25%~30%之间,大约每年至少能为公司节省百万成本。
主要升级改动
打开 Spark 3.0 AQE 的新特性,主要配置如下:
"spark.sql.adaptive.enabled": true,
"spark.sql.adaptive.coalescePartitions.enabled": true,
"spark.sql.adaptive.coalescePartitions.minPartitionNum": 1,
"spark.sql.adaptive.advisoryPartitionSizeInBytes": "128MB"
需要注意的是,AQE 特性只是在 reducer 阶段不用指定 reducer 的个数,但并不代表你不再需要指定任务的并行度了。因为 map 阶段仍然需要将数据划分为合适的分区进行处理,如果没有指定并行度会使用默认的 200,当数据量过大时,很容易出现 OOM。建议还是按照任务之前的并行度设置来配置参数spark.sql.shuffle.partitions和spark.default.parallelism。
我们来仔细看一下为什么升级到 3.0 以后可以减少运行时间,又能节省集群的成本。 以 Optimus 数据建模里的一张表的运行情况为例:
- 在 reduce 阶段从没有 AQE 的40320个 tasks 锐减到4580个 tasks,减少了一个数量级。
- 下图里下半部分是没有 AQE 的 Spark 2.x 的 task 情况,上半部分是打开 AQE 特性后的 Spark 3.x 的情况。

- 从更详细的运行时间图来看,shuffler reader后同样的 aggregate 的操作等时间也从4.44h到2.56h,节省将近一半。
- 左边是 spark 2.x 的运行指标明细,右边是打开 AQE 后通过custom shuffler reader后的运行指标情况。
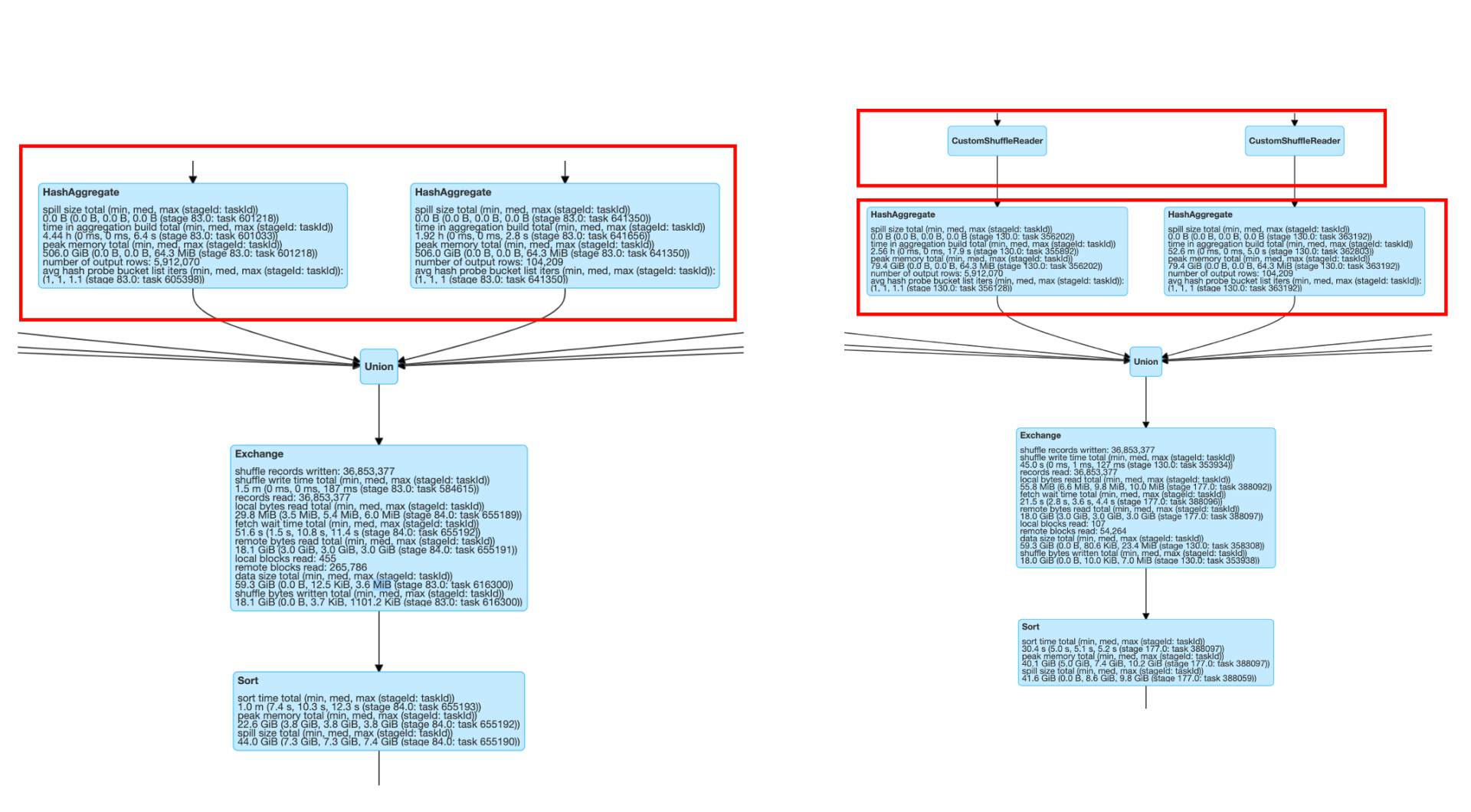
性能提升
AQE性能
AQE对于整体的 Spark SQL 的执行过程做了相应的调整和优化(如下图),它最大的亮点是可以根据已经完成的计划结点真实且精确的执行统计结果来不停的反馈并重新优化剩下的执行计划。
AQE 自动调整 reducer 的数量,减小 partition 数量。Spark 任务的并行度一直是让用户比较困扰的地方。如果并行度太大的话,会导致 task 过多,overhead 比较大,整体拉慢任务的运行。而如果并行度太小的,数据分区会比较大,容易出现 OOM 的问题,并且资源也得不到合理的利用,并行运行任务优势得不到最大的发挥。
而且由于 Spark Context 整个任务的并行度,需要一开始设定好且没法动态修改,这就很容易出现任务刚开始的时候数据量大需要大的并行度,而运行的过程中通过转化过滤可能最终的数据集已经变得很小,最初设定的分区数就显得过大了。AQE 能够很好的解决这个问题,在 reducer 去读取数据时,会根据用户设定的分区数据的大小(spark.sql.adaptive.advisoryPartitionSizeInBytes)来自动调整和合并(Coalesce)小的 partition,自适应地减小 partition 的数量,以减少资源浪费和 overhead,提升任务的性能。
由上面单张表可以看到,打开 AQE 的时候极大的降低了 task 的数量,除了减轻了 Driver 的负担,也减少启动 task 带来的 schedule,memory,启动管理等 overhead,减少 cpu 的占用,提升的 I/O 性能。
拿历史 Data Pipelines 为例,同时会并行有三十多张表在 Spark 里运行,每张表都有极大的性能提升,那么也使得其他的表能够获得资源更早更多,互相受益,那么最终整个的数据建模过程会自然而然有一个加速的结果。
大 batch(>200G)相对小 batch(< 100G )有比较大的提升,有高达 40%提升,主要是因为大 batch 本身数据量大,需要机器数多,设置并发度也更大,那么 AQE 展现特性的时刻会更多更明显。而小 batch 并发度相对较低,那么提升也就相对会少一些,不过也是有 27.5%左右的加速。
内存优化
除了因为 AQE 的打开,减少过碎的 task 对于 memory 的占用外,Spark 3.0 也在其他地方做了很多内存方面的优化,比如 Aggregate 部分指标瘦身、Netty 的共享内存 Pool 功能、Task Manager 死锁问题、避免某些场景下从网络读取 shuffle block等等,来减少内存的压力。一系列内存的优化加上 AQE 特性叠加从前文内存实践图中可以看到集群的内存使用同时有30%左右的下降。
实践成果
升级主要的实践成果如下:
性能提升明显
-
历史数据 Pipeline 对于大 batch 的数据(200~400G/每小时)性能提升高达40%, 对于小 batch(小于 100G/每小时)提升效果没有大 batch 提升的那么明显,每天所有 batches平均提升水平27.5%左右。
-
预测数据性能平均提升30%。由于数据输入源不一样,目前是分别两个 pipelines 在跑历史和预测数据,产生的表的数目也不太一样,因此做了分别的评估。
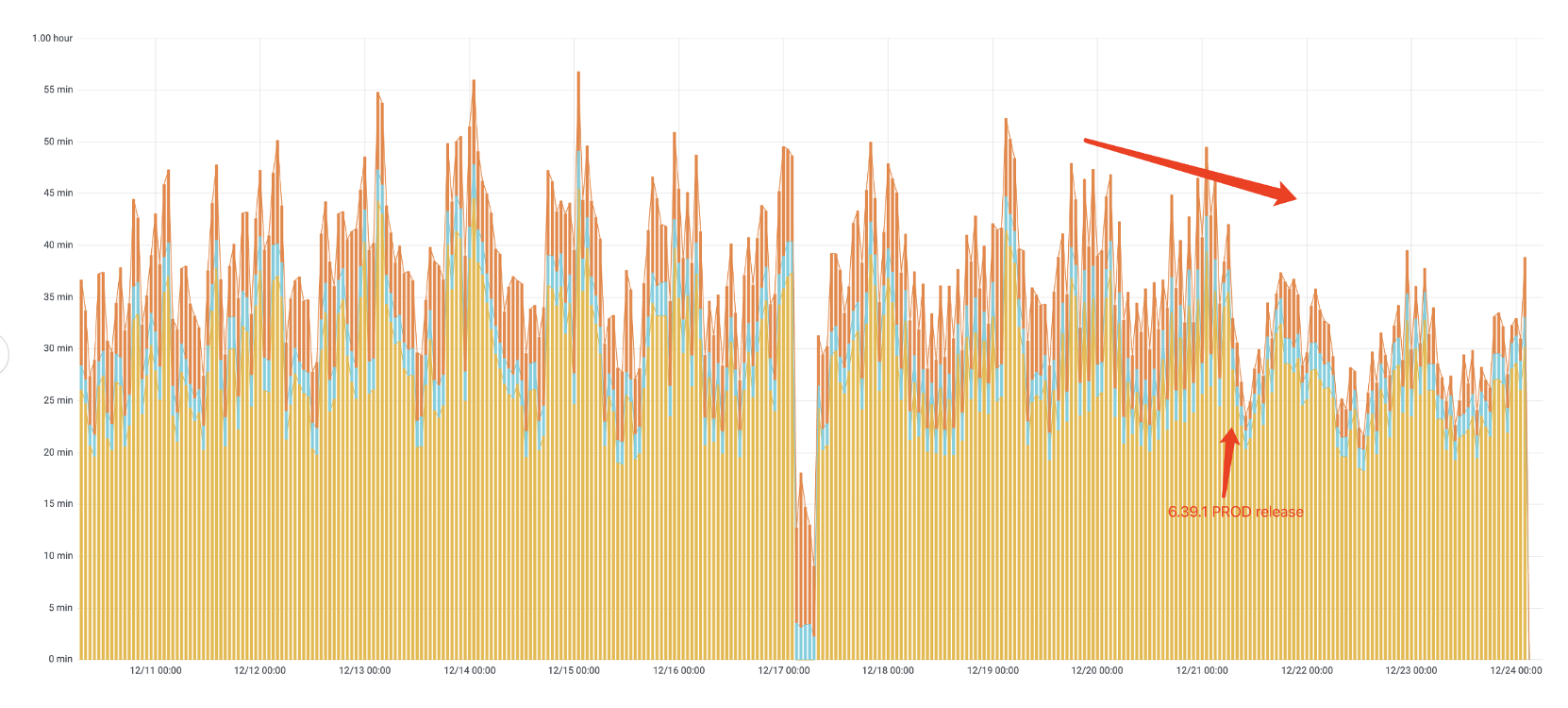
以历史数据上线后的端到端到运行时间为例(如下图),肉眼可见上线后整体 pipeline 的运行时间有了明显的下降,能够更快的输出数据供下游使用。
集群内存使用降低
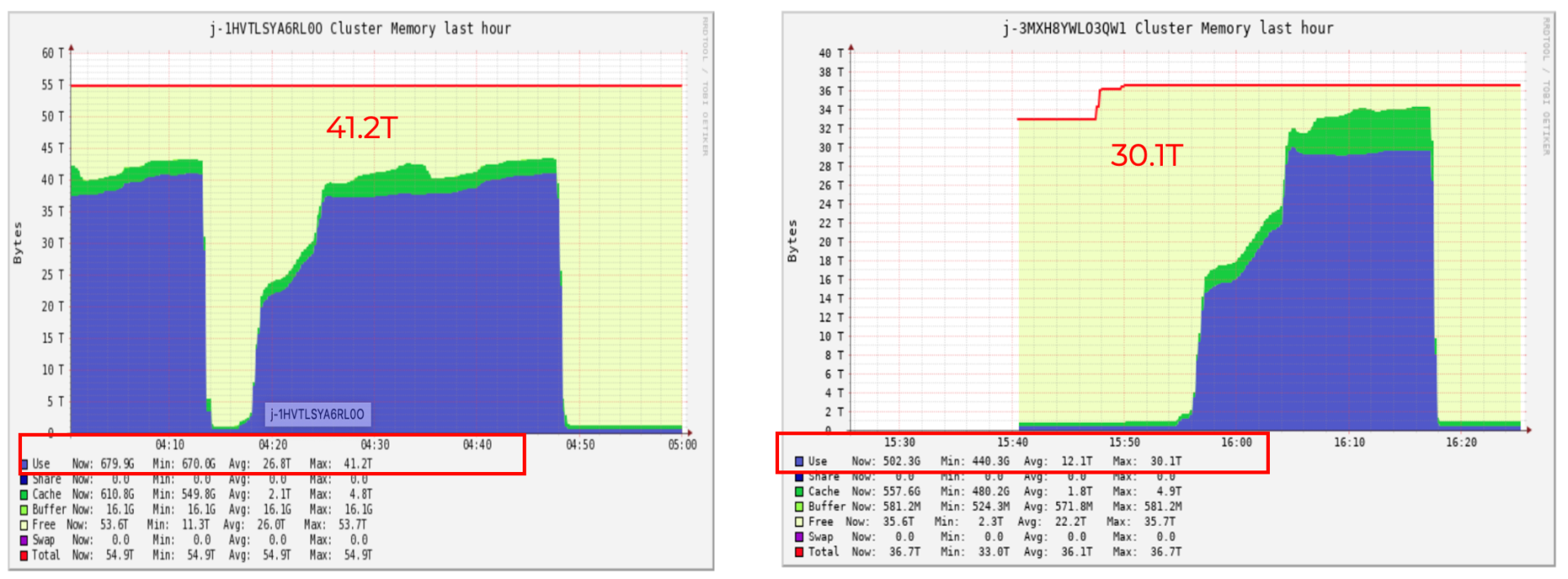
集群内存使用对于大 batch 达降低30%左右,每天平均平均节省25%左右。
以历史数据上线后的运行时集群的 memory 在 ganglia 上的截图为例(如下图),整体集群的内存使用从 41.2T 降到 30.1T,这意味着我们可以用更少的机器花更少的钱来跑同样的 Spark 任务。
AWS Cost 降低
Pipelines 做了自动的 Scale In/Scale Out 策略: 在需要资源的时候扩集群的 Task 结点,在任务结束后自动去缩集群的 Task 结点,且会根据每次 batch 数据的大小通过算法学习得到最佳的机器数。通过升级到 Spark 3.0 后,由于现在任务跑的更快并且需要的机器更少,上线后统计 AWS Cost 每天节省30%左右,大约一年能为公司节省百万成本。
欢迎关注,《大数据成神之路》系列文章
欢迎关注,《大数据成神之路》系列文章
欢迎关注,《大数据成神之路》系列文章