learn from:
莫烦教keras的视频:
https://morvanzhou.github.io/tutorials/machine-learning/keras/2-1-regressor/
keras官方文档:
https://keras.io/zh/
import numpy as np
np.random.seed(1337)
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
#造数据
#这个函数在之前《[学习笔记]numpy走一趟》中提到过,很实用的函数
#这里创建从-1 到 1的200个数的数组
X = np.linspace(-1,1,200)
np.random.shuffle(X) #打乱X数组的顺序
Y = 0.5 * X + 2 + np.random.normal(0, 0.05, 200) #造函数关系Y=0.5*x+2,并加扰动
#可视化我们造的数据
plt.scatter(X,Y) #画散点图
plt.show()
#分训练集与测试集
X_train, Y_train = X[:160], Y[:160]
X_test, Y_test = X[160:], Y[160:]
#建网络
model = Sequential() #网络按顺序构建
model.add(Dense(output_dim=1, input_dim=1))
#model.add(Dense(output_dim=1) #下一层会自动把上层的output_dim作为这层的input_dim
#选择loss function 和 optimizer
#mae:L1损失函数
#sgd:Stochastic Gradient Descent
model.compile(loss='mae',optimizer='sgd')
print('\nTesting ------------------------')
for step in range(301):
cost = model.train_on_batch(X_train, Y_train)
if step % 100 == 0:
print('train cost:',cost)
#train_on_batch(self, x, y, class_weight=None, sample_weight=None)
#本函数在一个batch的数据上进行一次参数更新。返回训练误差的标量值或标量值的list,与evaluate的情形相同
print('\nTesting--------------------------')
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:',cost)
w, b = model.layers[0].get_weights()
print('weight=',w,'\nbiases=',b)
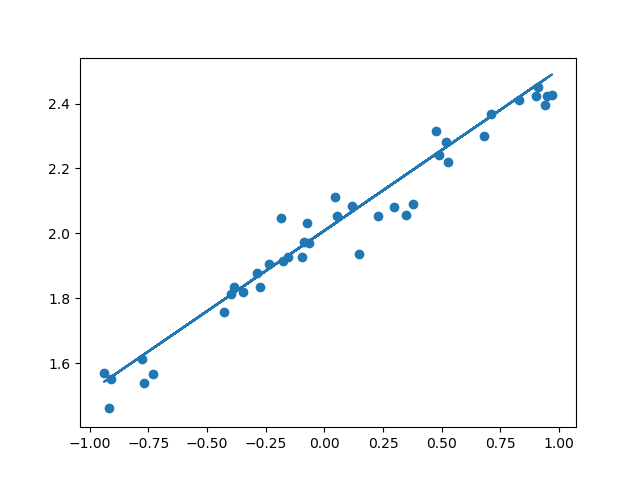
Y_pred = model.predict(X_test)
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred)
plt.show()
结果:
Testing ------------------------
train cost: 2.004756
train cost: 1.0045557
train cost: 0.050725747
train cost: 0.041173898
Testing--------------------------
40/40 [==============================] - 0s 294us/step
test cost: 0.044322382658720016
weight= [[0.4958204]]
biases= [2.008875]
可视化我们造的data:

可视化结果: