测试高远博同学的词频统计软件wf.exe
代码地址:https://coding.net/u/Rainbows/p/wc/git
需求:
以下bug可能在各个功能都存在,为了简洁说明只在功能4里展示,其余便不再赘述。
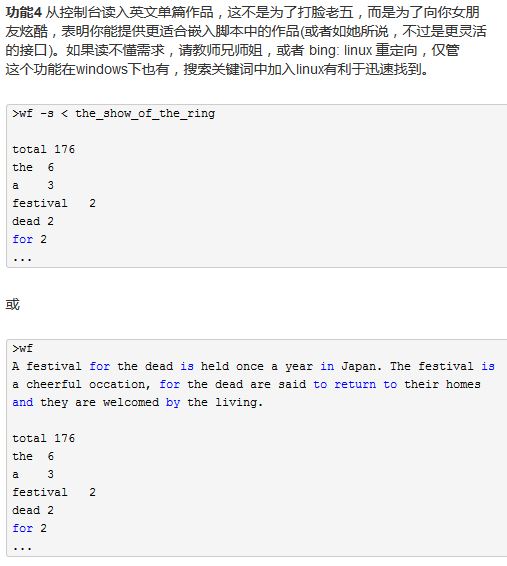
Bug1:未按规范输出单词
测试环境:windows10,命令行
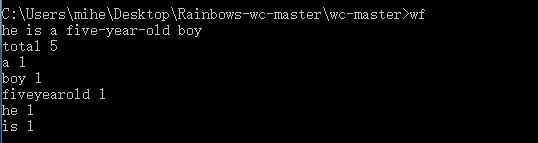
测试步骤:打开命令行并进入可执行文件所在目录,输入wf,回车之后键入he is a five-year-old boy
测试预期结果:five-year-old应原样输出并标明数量
测试结果:five-year-old中间的连字符不见了,三个拼接而成的单词挤在了一起。如果说five-year-old是否是一个单词存在争议,但是如下图所示fiveyearold肯定不叫单词
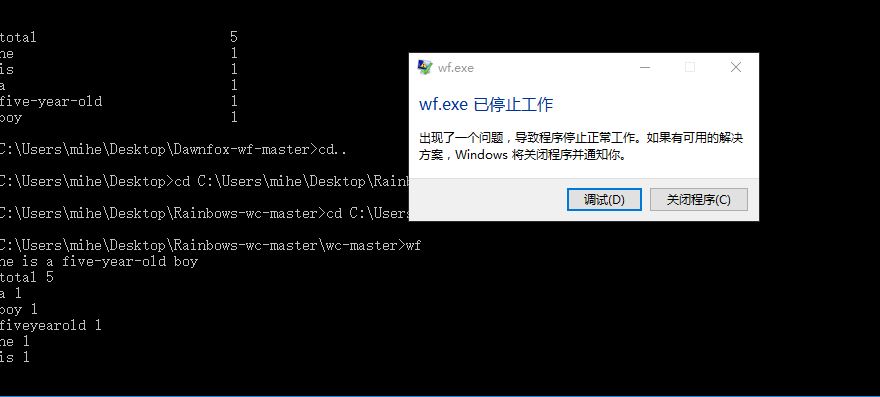
Bug2:程序非正常停止工作
测试环境:windows10,命令行
测试步骤:打开命令行并进入可执行文件所在目录,输入wf,回车之后键入“he is a five-year-old boy”,输入回车,再次输入回车
测试预期结果:我输入了两次回车,应该在下方有三行等待命令键入的当前路径显示
测试结果:在程序运行结束时并没有自动跳出,而第一次输入回车什么反应都没有,在第二次输入回车的时候程序停止工作
Bug3:输出单词空白
测试环境:windows10,命令行
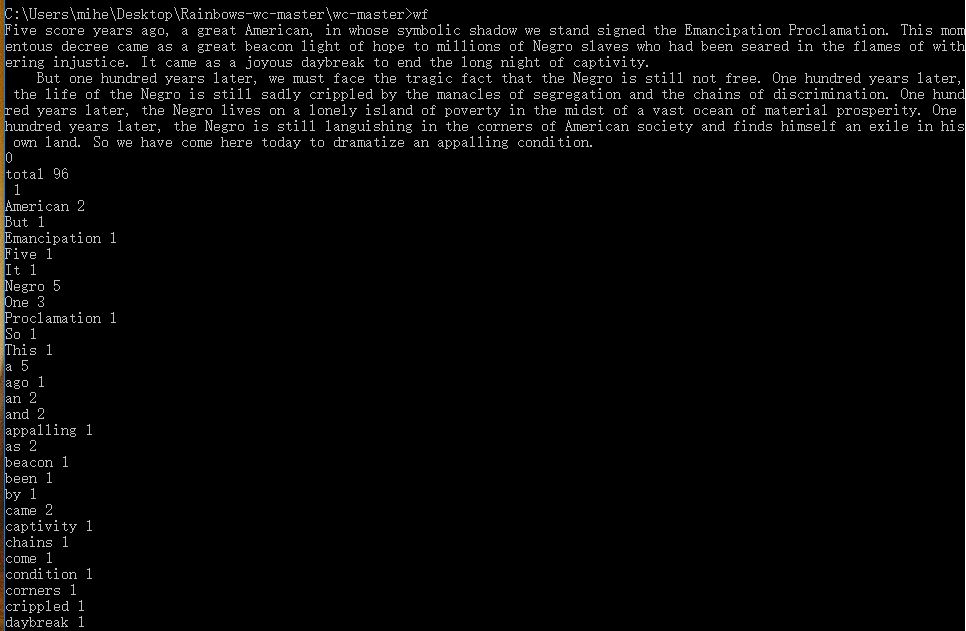
测试步骤:打开命令行并进入可执行文件所在目录,输入wf,回车之后将马丁路德金的《我有一个梦想》前两段复制并粘贴至命令行,按回车并按0结束输入(这并不符合功能要求)
测试预期结果:无需输入0即可输出词频,并正确显示词频
测试结果:需要按0,结束输入并把0当做结束输入的标志,并发现第一行没有单词却有“1”的数量标识

Bug4:无法区分大小写
测试环境:windows10,命令行
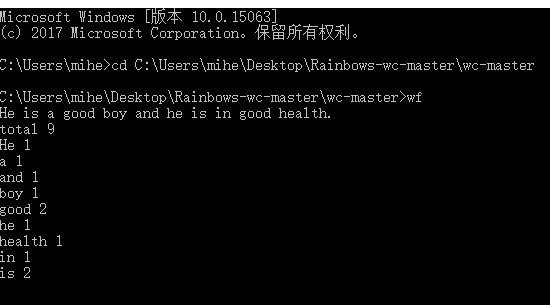
测试步骤:打开命令行并进入可执行文件所在目录,输入wf,回车之后输入“He is a good boy and he is in good health.”,再次回车得到结果
测试预期结果:正确区分大小写输出词频
测试结果:大写的He和小写的he并没有写作同一词而是分开统计
测试自己的bug:
综合各位的测试和我自己的测试,我的bug主要有以下几个:
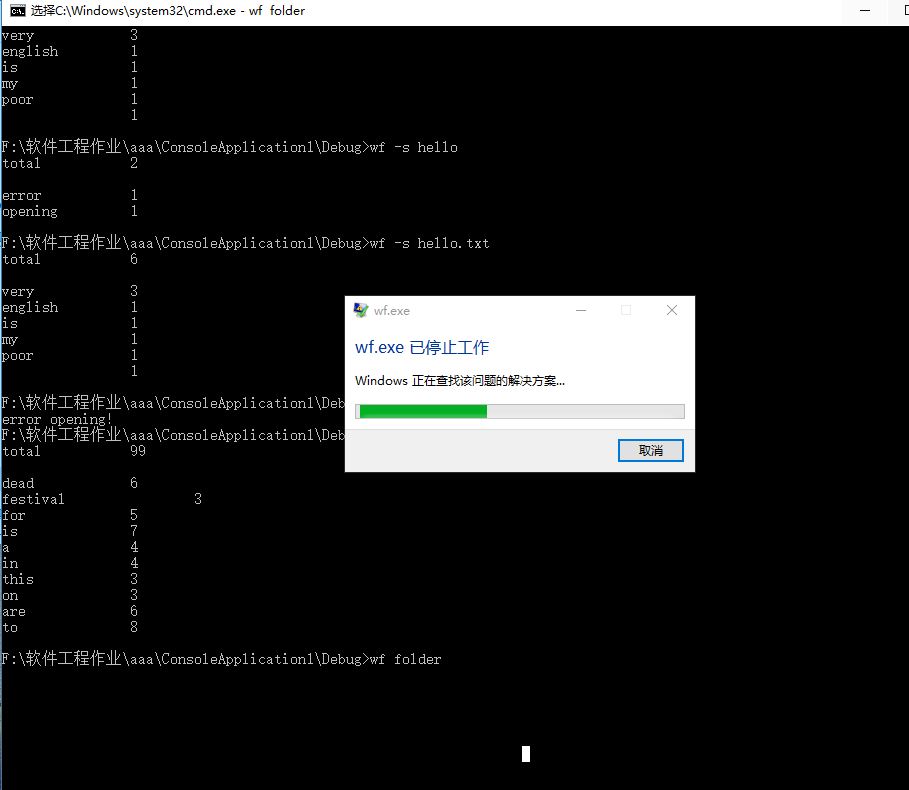
Bug1:在读取大文件的时候无法排序和正确统计词频
测试环境:windows10,命令行
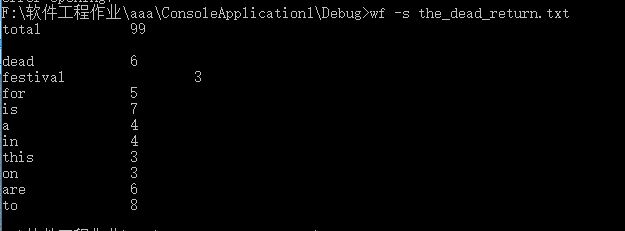
测试步骤:打开命令行并进入可执行文件所在目录,输入wf -s the_dead_return.txt,再次回车得到结果
测试预期结果:正确显示词频并将前十词频的单词进行排序
测试结果:无法排序,且部分单词词频不对
Bug2:无法读取文件夹并实现功能三
测试环境:windows10,命令行
测试步骤:打开命令行并进入可执行文件所在目录,输入wf folder,folder里预存了我的两个文本文件,再次回车得到结果
测试预期结果:正确按文件名字分别显示词频并将前十词频的单词进行排序
测试结果:程序非正常停止工作