1. Nginx的模块与工作原理
Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(location是Nginx配置中的一个指令,用于URL匹配),而在这个location中所配置的每个指令将会启动不同的模块去完成相应的工作。
Nginx的模块从结构上分为核心模块、基础模块和第三方模块:
核心模块:HTTP模块、EVENT模块和MAIL模块
基础模块:HTTP Access模块、HTTP FastCGI模块、HTTP Proxy模块和HTTP Rewrite模块,
第三方模块:HTTP Upstream Request Hash模块、Notice模块和HTTP Access Key模块。
用户根据自己的需要开发的模块都属于第三方模块。正是有了这么多模块的支撑,Nginx的功能才会如此强大。
Nginx的模块从功能上分为如下三类。
Handlers(处理器模块):此模块直接处理请求,并进行输出内容和修改headers信息等操作。Handlers处理器模块一般只能有一个。
Filters (过滤器模块):此模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出。
Proxies (代理类模块):此模块是Nginx的HTTP Upstream之类的模块,这些模块主要与后端一些服务比如FastCGI等进行交互,实现服务代理和负载均衡等功能。
图1-1展示了Nginx模块常规的HTTP请求和响应的过程。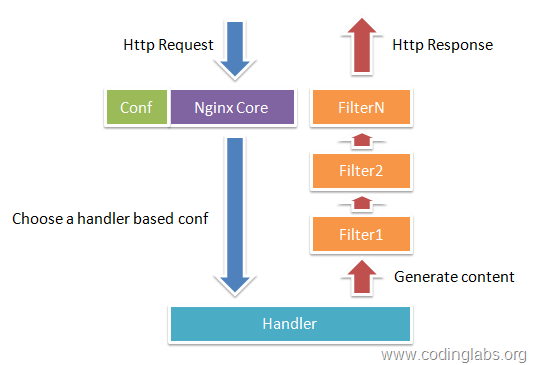
Nginx本身做的工作实际很少,当它接到一个HTTP请求时,它仅仅是通过查找配置文件将此次请求映射到一个location block,而此location中所配置的各个指令则会启动不同的模块去完成工作,因此模块可以看做Nginx真正的劳动工作者。通常一个location中的指令会涉及一个handler模块和多个filter模块(当然,多个location可以复用同一个模块)。handler模块负责处理请求,完成响应内容的生成,而filter模块对响应内容进行处理。
Nginx的模块直接被编译进Nginx,因此属于静态编译方式。启动Nginx后,Nginx的模块被自动加载,不像Apache,首先将模块编译为一个so文件,然后在配置文件中指定是否进行加载。在解析配置文件时,Nginx的每个模块都有可能去处理某个请求,但是同一个处理请求只能由一个模块来完成。
2. Nginx的进程模型
在工作方式上,Nginx分为单工作进程和多工作进程两种模式。在单工作进程模式下,除主进程外,还有一个工作进程,工作进程是单线程的;在多工作进程模式下,每个工作进程包含多个线程。Nginx默认为单工作进程模式。
Nginx在启动后,会有一个master进程和多个worker进程。
master进程
主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。
master进程充当整个进程组与用户的交互接口,同时对进程进行监护。它不需要处理网络事件,不负责业务的执行,只会通过管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。
我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
worker进程:
而基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的。
worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
nginx的进程模型,可以由下图来表示: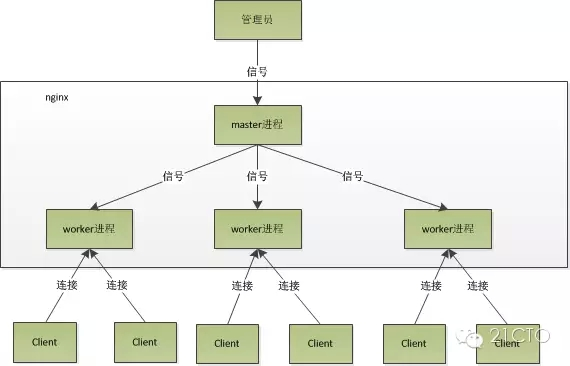
3. Nginx+FastCGI运行原理
1、什么是 FastCGI
FastCGI是一个可伸缩地、高速地在HTTP server和动态脚本语言间通信的接口。多数流行的HTTP server都支持FastCGI,包括Apache、Nginx和lighttpd等。同时,FastCGI也被许多脚本语言支持,其中就有PHP。
FastCGI是从CGI发展改进而来的。传统CGI接口方式的主要缺点是性能很差,因为每次HTTP服务器遇到动态程序时都需要重新启动脚本解析器来执行解析,然后将结果返回给HTTP服务器。这在处理高并发访问时几乎是不可用的。另外传统的CGI接口方式安全性也很差,现在已经很少使用了。
FastCGI接口方式采用C/S结构,可以将HTTP服务器和脚本解析服务器分开,同时在脚本解析服务器上启动一个或者多个脚本解析守护进程。当HTTP服务器每次遇到动态程序时,可以将其直接交付给FastCGI进程来执行,然后将得到的结果返回给浏览器。这种方式可以让HTTP服务器专一地处理静态请求或者将动态脚本服务器的结果返回给客户端,这在很大程度上提高了整个应用系统的性能。
2、Nginx+FastCGI运行原理
Nginx不支持对外部程序的直接调用或者解析,所有的外部程序(包括PHP)必须通过FastCGI接口来调用。FastCGI接口在Linux下是socket(这个socket可以是文件socket,也可以是ip socket)。
wrapper:为了调用CGI程序,还需要一个FastCGI的wrapper(wrapper可以理解为用于启动另一个程序的程序),这个wrapper绑定在某个固定socket上,如端口或者文件socket。当Nginx将CGI请求发送给这个socket的时候,通过FastCGI接口,wrapper接收到请求,然后Fork(派生)出一个新的线程,这个线程调用解释器或者外部程序处理脚本并读取返回数据;接着,wrapper再将返回的数据通过FastCGI接口,沿着固定的socket传递给Nginx;最后,Nginx将返回的数据(html页面或者图片)发送给客户端。这就是Nginx+FastCGI的整个运作过程,如图1-3所示。
所以,我们首先需要一个wrapper,这个wrapper需要完成的工作:
通过调用fastcgi(库)的函数通过socket和ningx通信(读写socket是fastcgi内部实现的功能,对wrapper是非透明的)
调度thread,进行fork和kill
和application(php)进行通信
3、spawn-fcgi与PHP-FPM
FastCGI接口方式在脚本解析服务器上启动一个或者多个守护进程对动态脚本进行解析,这些进程就是FastCGI进程管理器,或者称为FastCGI引擎。 spawn-fcgi与PHP-FPM就是支持PHP的两个FastCGI进程管理器。因此HTTPServer完全解放出来,可以更好地进行响应和并发处理。
spawn-fcgi与PHP-FPM的异同:
1)spawn-fcgi是HTTP服务器lighttpd的一部分,目前已经独立成为一个项目,一般与lighttpd配合使用来支持PHP。但是ligttpd的spwan-fcgi在高并发访问的时候,会出现内存泄漏甚至自动重启FastCGI的问题。即:PHP脚本处理器当机,这个时候如果用户访问的话,可能就会出现白页(即PHP不能被解析或者出错)。
2)Nginx是个轻量级的HTTP server,必须借助第三方的FastCGI处理器才可以对PHP进行解析,因此其实这样看来nginx是非常灵活的,它可以和任何第三方提供解析的处理器实现连接从而实现对PHP的解析(在nginx.conf中很容易设置)。nginx也可以使用spwan-fcgi(需要一同安装lighttpd,但是需要为nginx避开端口,一些较早的blog有这方面安装的教程),但是由于spawn-fcgi具有上面所述的用户逐渐发现的缺陷,现在慢慢减少用nginx+spawn-fcgi组合了。
由于spawn-fcgi的缺陷,现在出现了第三方(目前已经加入到PHP core中)的PHP的FastCGI处理器PHP-FPM,它和spawn-fcgi比较起来有如下优点:
由于它是作为PHP的patch补丁来开发的,安装的时候需要和php源码一起编译,也就是说编译到php core中了,因此在性能方面要优秀一些;
同时它在处理高并发方面也优于spawn-fcgi,至少不会自动重启fastcgi处理器。因此,推荐使用Nginx+PHP/PHP-FPM这个组合对PHP进行解析。
相对Spawn-FCGI,PHP-FPM在CPU和内存方面的控制都更胜一筹,而且前者很容易崩溃,必须用crontab进行监控,而PHP-FPM则没有这种烦恼。
FastCGI 的主要优点是把动态语言和HTTP Server分离开来,所以Nginx与PHP/PHP-FPM经常被部署在不同的服务器上,以分担前端Nginx服务器的压力,使Nginx专一处理静态请求和转发动态请求,而PHP/PHP-FPM服务器专一解析PHP动态请求。
4、Nginx+PHP-FPM
PHP-FPM是管理FastCGI的一个管理器,它作为PHP的插件存在,在安装PHP要想使用PHP-FPM时在老php的老版本(php5.3.3之前)就需要把PHP-FPM以补丁的形式安装到PHP中,而且PHP要与PHP-FPM版本一致,这是必须的)
PHP-FPM其实是PHP源代码的一个补丁,旨在将FastCGI进程管理整合进PHP包中。必须将它patch到你的PHP源代码中,在编译安装PHP后才可以使用。
PHP5.3.3已经集成php-fpm了,不再是第三方的包了。PHP-FPM提供了更好的PHP进程管理方式,可以有效控制内存和进程、可以平滑重载PHP配置,比spawn-fcgi具有更多优点,所以被PHP官方收录了。在./configure的时候带 –enable-fpm参数即可开启PHP-FPM。
fastcgi已经在php5.3.5的core中了,不必在configure时添加 --enable-fastcgi了。老版本如php5.2的需要加此项。
当我们安装Nginx和PHP-FPM完后,配置信息:
PHP-FPM的默认配置php-fpm.conf:
listen_address 127.0.0.1:9000 #这个表示php的fastcgi进程监听的ip地址以及端口
start_servers
min_spare_servers
max_spare_servers
Nginx配置运行php: 编辑nginx.conf加入如下语句:
location ~ .php$ {
root html;
fastcgi_pass 127.0.0.1:9000; 指定了fastcgi进程侦听的端口,nginx就是通过这里与php交互的
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /usr/local/nginx/html$fastcgi_script_name;
}
Nginx通过location指令,将所有以php为后缀的文件都交给127.0.0.1:9000来处理,而这里的IP地址和端口就是FastCGI进程监听的IP地址和端口。
其整体工作流程:
1)、FastCGI进程管理器php-fpm自身初始化,启动主进程php-fpm和启动start_servers个CGI 子进程。
主进程php-fpm主要是管理fastcgi子进程,监听9000端口。
fastcgi子进程等待来自Web Server的连接。
2)、当客户端请求到达Web Server Nginx是时,Nginx通过location指令,将所有以php为后缀的文件都交给127.0.0.1:9000来处理,即Nginx通过location指令,将所有以php为后缀的文件都交给127.0.0.1:9000来处理。
3)FastCGI进程管理器PHP-FPM选择并连接到一个子进程CGI解释器。Web server将CGI环境变量和标准输入发送到FastCGI子进程。
4)、FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server。当FastCGI子进程关闭连接时,请求便告处理完成。
5)、FastCGI子进程接着等待并处理来自FastCGI进程管理器(运行在 WebServer中)的下一个连接。
5. Nginx为啥性能高-多进程IO模型
1、nginx采用多进程模型好处
首先,对于每个worker进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多。
其次,采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快启动新的worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当前worker上的所有请求失败,不过不会影响到所有请求,所以降低了风险。
2、nginx多进程事件模型:异步非阻塞
虽然nginx采用多worker的方式来处理请求,每个worker里面只有一个主线程,那能够处理的并发数很有限啊,多少个worker就能处理多少个并发,何来高并发呢?非也,这就是nginx的高明之处,nginx采用了异步非阻塞的方式来处理请求,也就是说,nginx是可以同时处理成千上万个请求的。一个worker进程可以同时处理的请求数只受限于内存大小,而且在架构设计上,不同的worker进程之间处理并发请求时几乎没有同步锁的限制,worker进程通常不会进入睡眠状态,因此,当Nginx上的进程数与CPU核心数相等时(最好每一个worker进程都绑定特定的CPU核心),进程间切换的代价是最小的。
而apache的常用工作方式(apache也有异步非阻塞版本,但因其与自带某些模块冲突,所以不常用),每个进程在一个时刻只处理一个请求,因此,当并发数上到几千时,就同时有几千的进程在处理请求了。这对操作系统来说,是个不小的挑战,进程带来的内存占用非常大,进程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。

为什么nginx可以采用异步非阻塞的方式来处理呢,或者异步非阻塞到底是怎么回事呢?
我们先回到原点,看看一个请求的完整过程:首先,请求过来,要建立连接,然后再接收数据,接收数据后,再发送数据。
具体到系统底层,就是读写事件,而当读写事件没有准备好时,必然不可操作,如果不用非阻塞的方式来调用,那就得阻塞调用了,事件没有准备好,那就只能等了,等事件准备好了,你再继续吧。阻塞调用会进入内核等待,cpu就会让出去给别人用了,对单线程的worker来说,显然不合适,当网络事件越多时,大家都在等待呢,cpu空闲下来没人用,cpu利用率自然上不去了,更别谈高并发了。好吧,你说加进程数,这跟apache的线程模型有什么区别,注意,别增加无谓的上下文切换。所以,在nginx里面,最忌讳阻塞的系统调用了。不要阻塞,那就非阻塞喽。非阻塞就是,事件没有准备好,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。
nginx支持的事件模型如下(nginx的wiki):
Nginx支持如下处理连接的方法(I/O复用方法),这些方法可以通过use指令指定。
select– 标准方法。 如果当前平台没有更有效的方法,它是编译时默认的方法。你可以使用配置参数 –with-select_module 和 –without-select_module 来启用或禁用这个模块。
poll– 标准方法。 如果当前平台没有更有效的方法,它是编译时默认的方法。你可以使用配置参数 –with-poll_module 和 –without-poll_module 来启用或禁用这个模块。
kqueue– 高效的方法,使用于 FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 和 MacOS X. 使用双处理器的MacOS X系统使用kqueue可能会造成内核崩溃。
epoll – 高效的方法,使用于Linux内核2.6版本及以后的系统。在某些发行版本中,如SuSE 8.2, 有让2.4版本的内核支持epoll的补丁。
rtsig – 可执行的实时信号,使用于Linux内核版本2.2.19以后的系统。默认情况下整个系统中不能出现大于1024个POSIX实时(排队)信号。这种情况 对于高负载的服务器来说是低效的;所以有必要通过调节内核参数 /proc/sys/kernel/rtsig-max 来增加队列的大小。可是从Linux内核版本2.6.6-mm2开始, 这个参数就不再使用了,并且对于每个进程有一个独立的信号队列,这个队列的大小可以用 RLIMIT_SIGPENDING 参数调节。当这个队列过于拥塞,nginx就放弃它并且开始使用 poll 方法来处理连接直到恢复正常。
/dev/poll – 高效的方法,使用于 Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+ 和 Tru64 UNIX 5.1A+.
eventport – 高效的方法,使用于 Solaris 10. 为了防止出现内核崩溃的问题, 有必要安装这个 安全补丁。
在linux下面,只有epoll是高效的方法
下面再来看看epoll到底是如何高效的
Epoll是Linux内核为处理大批量句柄而作了改进的poll。 要使用epoll只需要这三个系统调用:epoll_create(2), epoll_ctl(2), epoll_wait(2)。它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux kernel 2.5.44),在2.6内核中得到广泛应用。
epoll的优点
支持一个进程打开大数目的socket描述符(FD)
select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是2048。对于那些需要支持的上万连接数目的IM服务器来说显 然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的 Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完 美的方案。不过 epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左 右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
IO效率不随FD数目增加而线性下降
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是”活跃”的,但 是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对”活跃”的socket进行操 作—这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有”活跃”的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个”伪”AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的—比如一个高速LAN环境,epoll并不比select/poll有什么效率,相 反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
使用mmap加速内核与用户空间的消息传递。
这 点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很 重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。而如果你想我一样从2.5内核就关注epoll的话,一定不会忘记手工 mmap这一步的。
内核微调
这一点其实不算epoll的优点了,而是整个linux平台的优点。也许你可以怀疑linux平台,但是你无法回避linux平台赋予你微调内核的能力。比如,内核TCP/IP协 议栈使用内存池管理sk_buff结构,那么可以在运行时期动态调整这个内存pool(skb_head_pool)的大小— 通过echo XXXX>/proc/sys/net/core/hot_list_length完成。再比如listen函数的第2个参数(TCP完成3次握手 的数据包队列长度),也可以根据你平台内存大小动态调整。更甚至在一个数据包面数目巨大但同时每个数据包本身大小却很小的特殊系统上尝试最新的NAPI网卡驱动架构。
推荐设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。像这种小的优化在nginx中非常常见,同时也说明了nginx作者的苦心孤诣。比如,nginx在做4个字节的字符串比较时,会将4个字符转换成一个int型,再作比较,以减少cpu的指令数等等。