前置知识: virtual table in C++
对于每个opr,dispatcher构建了一个vtable(c++多态性相关概念)。dispatcher的工作就是根据输入的tensor和其他一些meta信息,计算dispatch key,然后根据vtable跳转到相应的函数
c++ virtual table : https://www.cnblogs.com/ijpq/p/16291824.html
与c++ vtable区别:
| c++ vatable | pytorch vtable | 解释 | |
|---|---|---|---|
| 每个类有一个vtable | 每个opr有一个vtable | 在pytorch中,扩展一个已有的opr,只需要提供一个新的vtable。 | |
| 只有*this指针重要 | 不仅考虑tensor,还有其他的meta信息 | ||
| 支持boxing和unboxing |
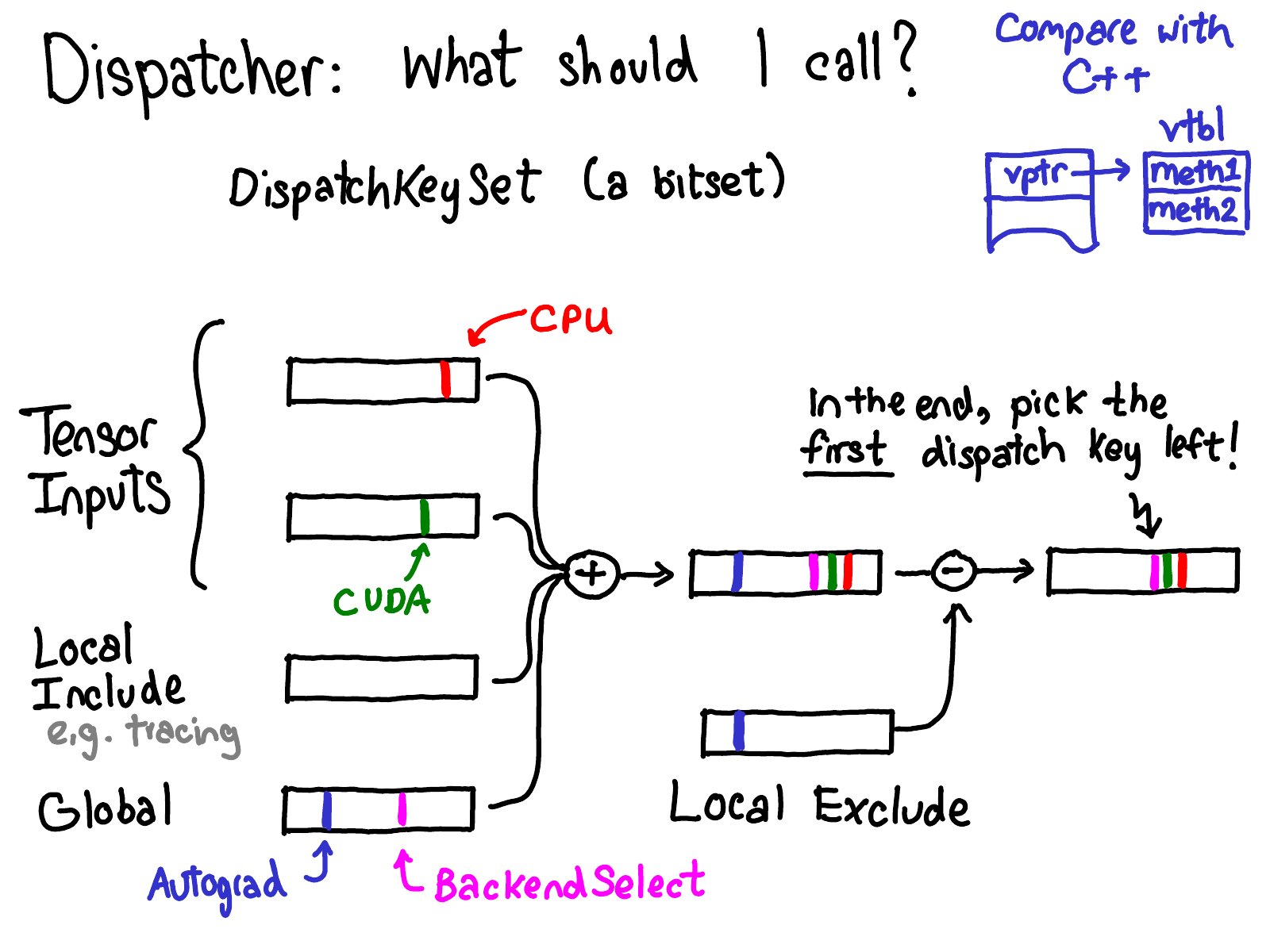
- 每个tensor可以决定一套dispatch key
- local include set, 与tensor无关的一些key, 例如tracing(目前还不知道tracing干啥的)
- global set,是一些必须要设定的key。之前autograd是位于这个global set的,但是现在放进tensor了
- local exclude set, 放一些已经dispatch过的key,这样就不会再set中出现,避免重复dispatch
一个autograd的dispatch过程(早期位于global set时的过程)
起始状态时,autograd位于global,exclude是空的。
执行dispatch过程,找到优先级最高的autograd key,调用autograd handler。在autograd过程中,创建了RAII AutoNonVariableTypeMode,它的作用是把autograd放入exclude中。
继续dispatch,跳过autograd,找到cpu key。
local TLS仍然处于call tree中,使得后续的dispatch操作会跳过autograd。
最后,从函数返回,RAII将autograd从exclude中删除.
一个tracing的过程
一个backendselect过程
函数指针是如何进入virtual table的?
通过registeration api实现的: https://pytorch.org/tutorials/advanced/dispatcher.html
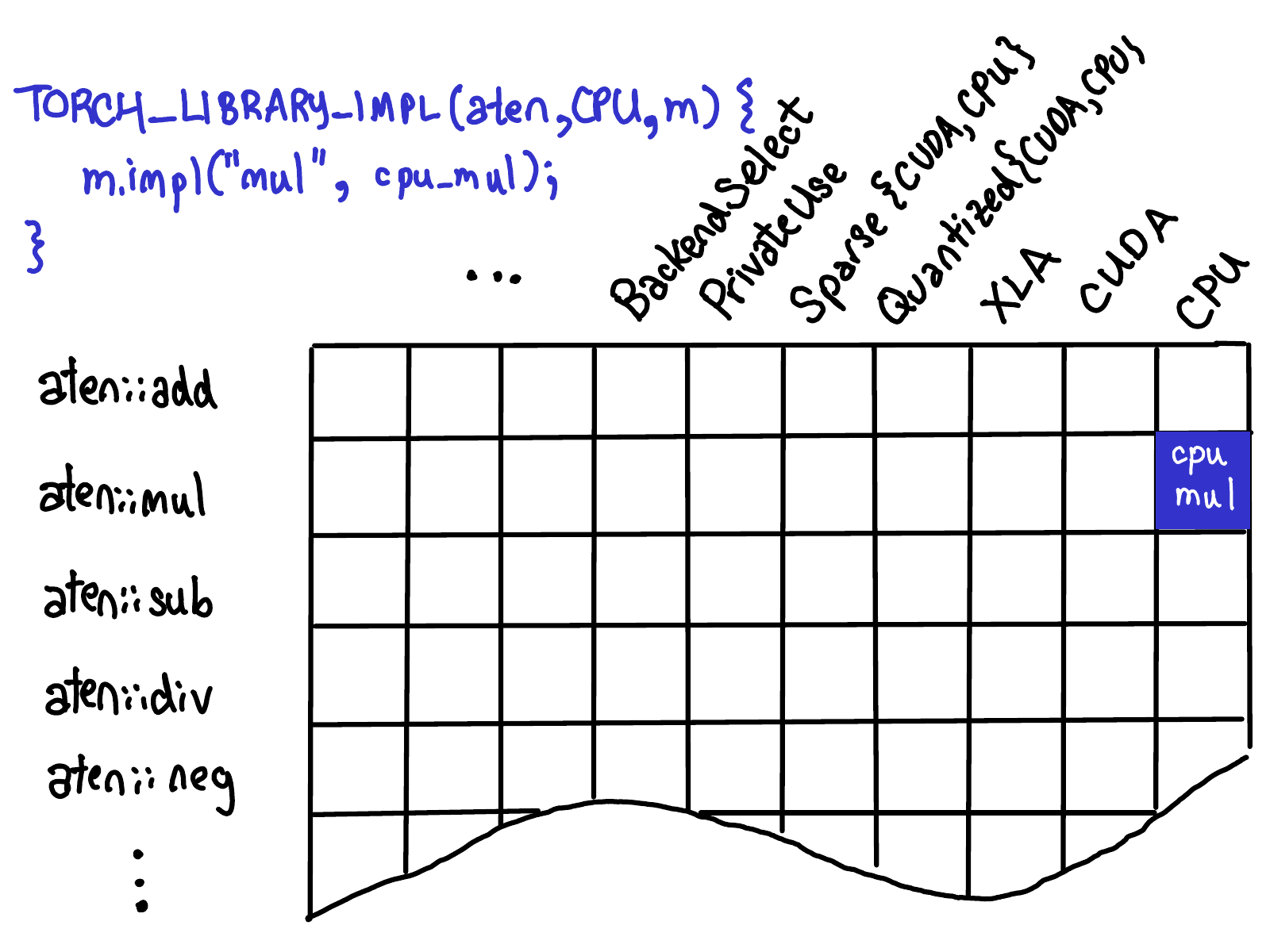
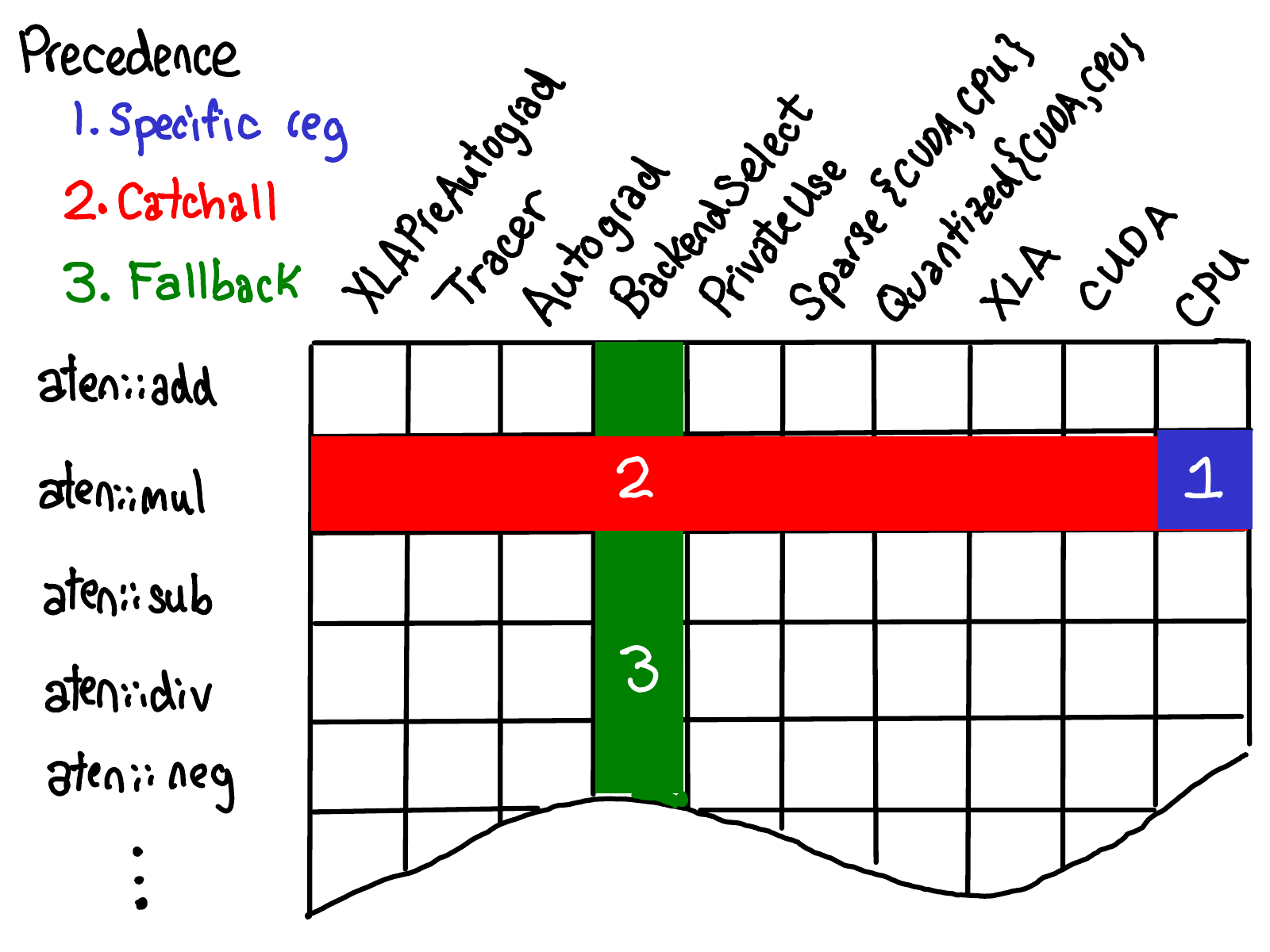
与registeration api交互的三个方式:定义schema(m.def),给一个dispatch key实现register(m.impl), fallback(m.fallback)(这三个表述比较模糊,见下面的图)

给一个dispatch key实现register如下,图示给CPU这个key实现register,即将cpu_mul这个kernel注册到cpu这个key上
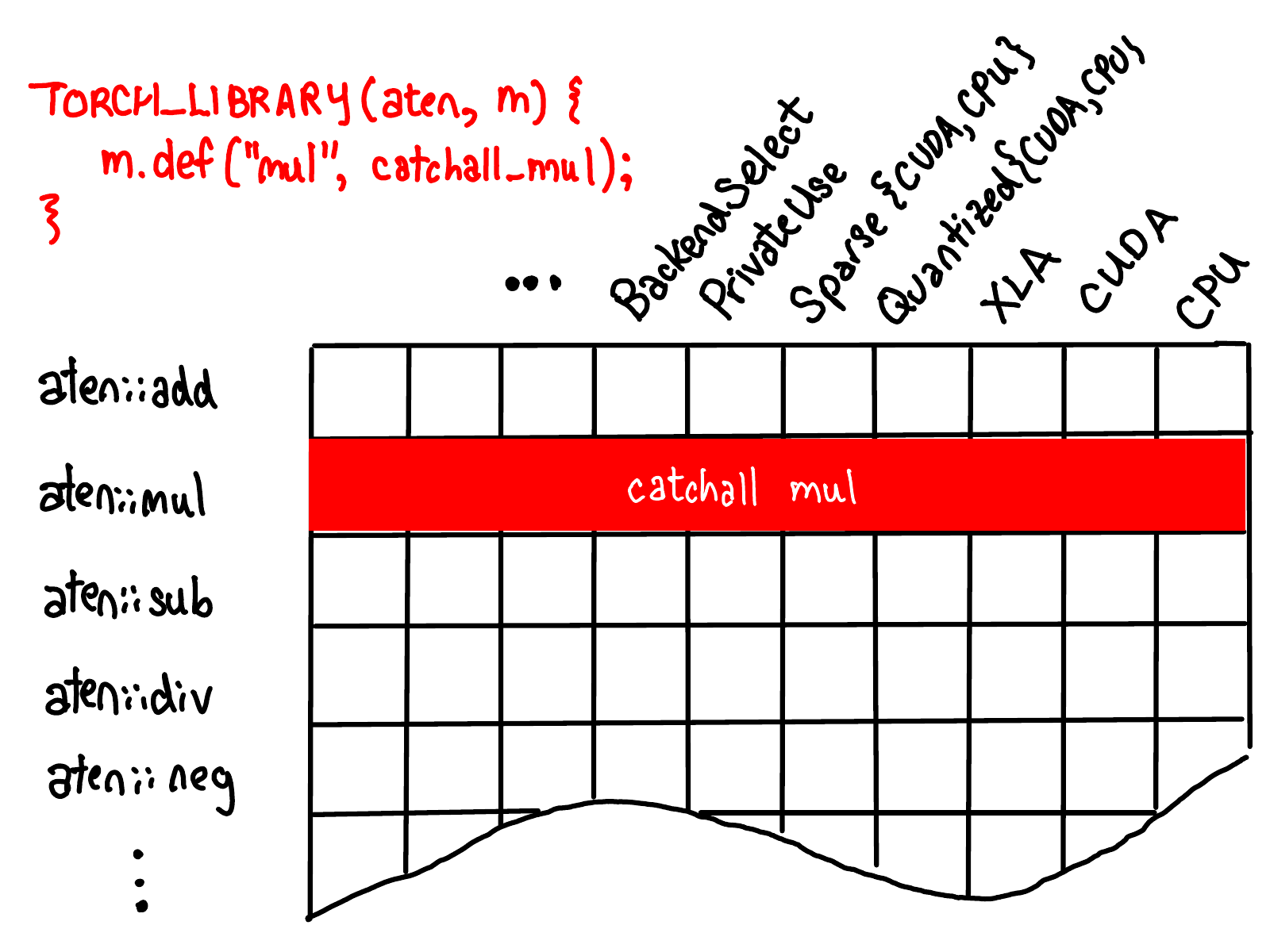
比如还可以给所有的key都注册同样的kernel。不过这种方式应该是不建议的
或者是给所有的opr都注册同样的fallback
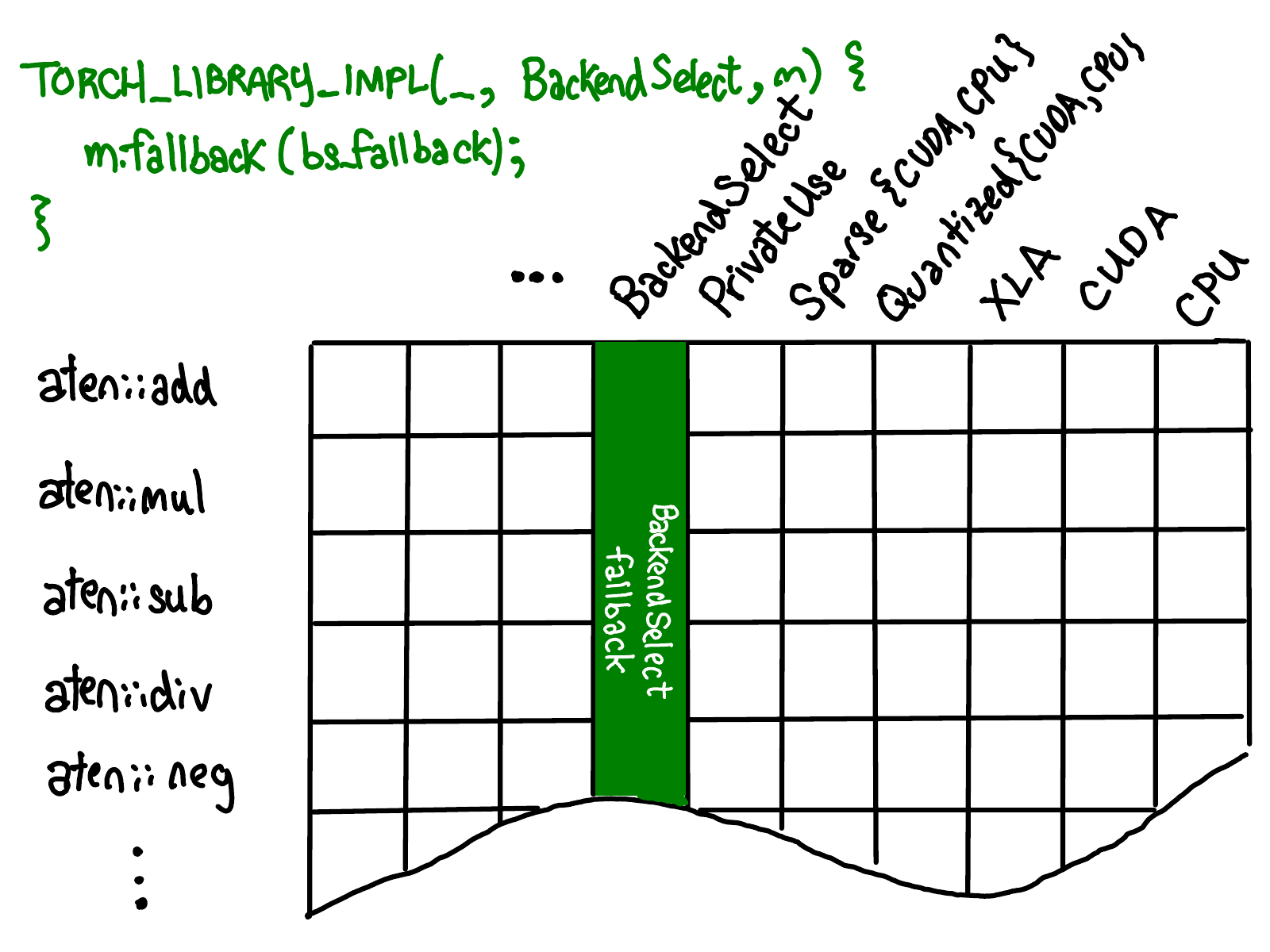
这三种操作存在优先级顺序,如下
boxing/unboxing
boxed数据表示,是指各种类型的数据有同样的layout。这样的话可以给不同type的数据写相同的调用方法
unboxed数据表示,是指各种类型的数据有适合自己的layout,在cpp中,由于是unboxed数据表示,所以可以借助模板来写相同的调用代码。
在torch中实现了boxed数据表示,//TODO