1.ArrayBlockingQueue
ArrayBlockingQueue是由数组支持的线程安全的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。一旦创建了这样的缓存区,就不能再增加其容量。试图向已满队列中放入元素会导致操作受阻塞;试图从空队列中提取元素将导致类似阻塞。此类支持对等待的生产者线程和消费者线程进行排序的可选公平策略。默认情况下,不保证是这种排序。然而,通过将公平性 (fairness) 设置为 true 而构造的队列允许按照 FIFO 顺序访问线程。公平性通常会降低吞吐量,但也减少了可变性和避免了“不平衡性”。
public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); }
从改造方法可以看出,ArrayBlockingQueue的实现机制是ReentrantLock和Condition来实现的。
2、LinkedBlockingDeque
LinkedBlockingDeque是用双向链表实现的,需要说明的是LinkedList也已经加入了Deque的一部分。
/** Maximum number of items in the deque */ private final int capacity;
/** * Creates a {@code LinkedBlockingDeque} with a capacity of * {@link Integer#MAX_VALUE}. */ public LinkedBlockingDeque() { this(Integer.MAX_VALUE); }
public LinkedBlockingDeque(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; }
- 要想支持阻塞功能,队列的容量一定是固定的,否则无法在入队的时候挂起线程。也就是capacity是final类型的。
- 既然是双向链表,每一个结点就需要前后两个引用,这样才能将所有元素串联起来,支持双向遍历。也即需要prev/next两个引用。
- 双向链表需要头尾同时操作,所以需要first/last两个节点,当然可以参考LinkedList那样采用一个节点的双向来完成,那样实现起来就稍微麻烦点。
- 既然要支持阻塞功能,就需要锁和条件变量来挂起线程。这里使用一个锁两个条件变量来完成此功能。
3、LinkedBlockingQueue
LinkedBlockingQueue是一个基于已链接节点的、范围任意的blocking queue的实现,也是线程安全的。按 FIFO(先进先出)排序元素。队列的头部 是在队列中时间最长的元素。队列的尾部 是在队列中时间最短的元素。
/** * Creates a {@code LinkedBlockingQueue} with a capacity of * {@link Integer#MAX_VALUE}. */ public LinkedBlockingQueue() { this(Integer.MAX_VALUE); }
public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node<E>(null); }
可选的容量范围构造方法参数作为防止队列过度扩展的一种方法。如果未指定容量,则它等于 Integer.MAX_VALUE。除非插入节点会使队列超出容量,否则每次插入后会动态地创建链接节点。
此外它还不接受null值:
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); // Note: convention in all put/take/etc is to preset local var // holding count negative to indicate failure unless set. int c = -1; Node<E> node = new Node<E>(e); final ReentrantLock putLock = this.putLock; final AtomicInteger count = this.count; putLock.lockInterruptibly();
4、PriorityBlockingQueue
PriorityBlockingQueue是一个无界的线程安全的阻塞队列,它使用与PriorityQueue相同的顺序规则,并且提供了阻塞检索的操作。
public PriorityBlockingQueue(int initialCapacity) { this(initialCapacity, null); }
public PriorityBlockingQueue(int initialCapacity, Comparator<? super E> comparator) { if (initialCapacity < 1) throw new IllegalArgumentException(); this.lock = new ReentrantLock(); this.notEmpty = lock.newCondition(); this.comparator = comparator; this.queue = new Object[initialCapacity]; }
从其构造方法可以看到到,有一个Comparator的接口。没错,这个就是判断元素Priority的关键:当前和其他对象比较,如果compare方法返回负数,那么在队列里面的优先级就比较高。当然,你在创建PriorityBlockingQueue的时候可以不指定Comparator对象,但是你被要求在被存放元素中去实现。
public boolean offer(E e) { if (e == null) throw new NullPointerException(); final ReentrantLock lock = this.lock; lock.lock(); int n, cap; Object[] array; while ((n = size) >= (cap = (array = queue).length)) tryGrow(array, cap); try { Comparator<? super E> cmp = comparator; if (cmp == null) siftUpComparable(n, e, array); else siftUpUsingComparator(n, e, array, cmp); size = n + 1; notEmpty.signal(); } finally { lock.unlock(); } return true; }
private static <T> void siftUpComparable(int k, T x, Object[] array) { Comparable<? super T> key = (Comparable<? super T>) x; while (k > 0) { int parent = (k - 1) >>> 1; Object e = array[parent]; if (key.compareTo((T) e) >= 0) break; array[k] = e; k = parent; } array[k] = key; }
每次offer元素,都会有一个siftUpComparable操作,也就是排序,如果没有构造的时候传入自己实现的比较器,就采用自然排序,否则采用比较器规则,进行二分查找,比较,保持列头是比较器希望的那个最大或则最小元素。
5、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque
ConcurrentHashMap支持高并发、高吞吐量的线程安全HashMap实现,其实现原理是锁分离机制,将数据分Segment管理。每个Segment拥有独立的锁。
/** * The segments, each of which is a specialized hash table */ final Segment<K,V>[] segments;
下面代码是Hash链中的元素:
static final class HashEntry<K,V> { final K key; final int hash; volatile V value; final HashEntry<K,V> next; }
我们可以看到Key,hash,HashEntry都是final类型的,这就决定了ConcurrentHashMap的必须在链表头插入,修改也只能从链表头开始遍历找到对应Key的元素进行修改,而删除这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。注意到Value使用了volatile修饰,这样程序在读的时候就不用加锁也能保证内存可见性。当然,在跨段操作(contains,size)中,还是会获取全部Segment中的锁去操作的,尽量避免跨段操作。
ConcurrentLinkedQueue、ConcurrentLinkedDeque分别是使用单向链表和双向链表实现,原理还是锁分离机制。
7、ConcurrentSkipListMap
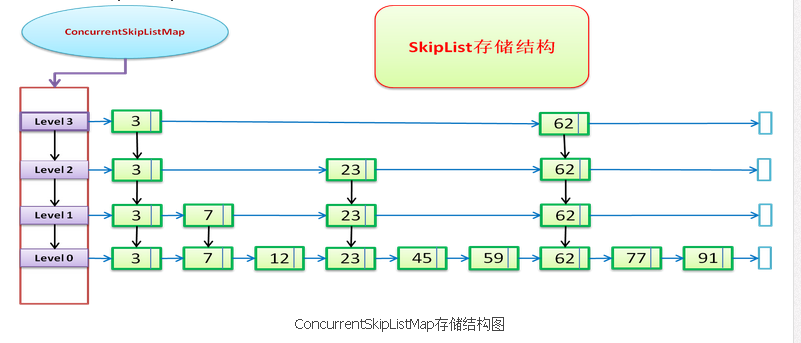
ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够在O(log(n))时间内完成查找、插入、删除操作。 在非多线程的情况下,应当尽量使用TreeMap。此外对于并发性相对较低的并行程序可以使用Collections.synchronizedSortedMap将TreeMap进行包装,也可以提供较好的效率。对于高并发程序,应当使用ConcurrentSkipListMap,能够提供更高的并发度。同样,ConcurrentSkipListMap支持Map的键值进行排序(参考:http://hi.baidu.com/yao1111yao/item/0f3008163c4b82c938cb306d)
concurrentHashMap与ConcurrentSkipListMap性能测试 在4线程1.6万数据的条件下,ConcurrentHashMap 存取速度是ConcurrentSkipListMap 的4倍左右。
但ConcurrentSkipListMap有几个ConcurrentHashMap 不能比拟的优点: 1、ConcurrentSkipListMap 的key是有序的。
2、ConcurrentSkipListMap 支持更高的并发。ConcurrentSkipListMap 的存取时间是log(N),和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出他的优势(参考:http://wenku.baidu.com/link?url=n40zltjgTbXUuV2CtXX1E4sBila9SI5rBs_qK1flOkwmJThF5ICLpF1xvU504PyUYGxx5RmqDdJdnYljcMro9gQ8AQe7RXgxKVfs2MV1J7m)。
8、ConcurrentSkipListSet
ConcurrentSkipListSet是线程安全的有序的集合,适用于高并发的场景。ConcurrentSkipListSet和TreeSet,它们虽然都是有序的集合。但是,第一,它们的线程安全机制不同,TreeSet是非线程安全的,而ConcurrentSkipListSet是线程安全的。第二,ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,而TreeSet是通过TreeMap实现的。
9、CopyOnWriteArrayList、CopyOnWriteArraySet
传统的List在多线程同时读写的时候会抛出java.util.ConcurrentModificationException,而CopyOnWriteArrayList是使用CopyOnWrite(写时复制)技术解决了这个问题,这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更有效。
写时复制:
/** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
我们可以看到写的过程中加了锁,因为如果不加锁的话,每条线程都会生成一个快照,造成内存消耗。先Arrays.copyOf了一份内存快照,然后写这份内存快照,写完最后将这份内存快照的应用转移到CopyOnWriteArrayList中。
/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array;
关于读,存储的变量使用volatile关键字,可以不加锁的情况下解决内存可见性的问题。对于CopyOnWriteArraySet而言就简单多了,只是持有一个CopyOnWriteArrayList,仅仅在add/addAll的时候检测元素是否存在,如果存在就不加入集合中。
最后关于CopyOnWrite的建议,由于插入会Copy内存,最后会导致垃圾回收,所以尽量少使用add操作,如果需要,尽量使用批量插入操作。对于经常插入的容器是不建议用这个的。
10、DelayQueue
DelayQueue是一个无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的Delayed 元素。根据这个特性么我们可以使用DelayQueue来实现缓存系统、实时调度系统等。
DelayQueue是一个BlockingQueue,其特化的参数是Delayed。Delayed扩展了Comparable接口,比较的基准为延时的时间值,Delayed接口的实现类getDelay的返回值应为固定值(final)。DelayQueue内部是使用PriorityQueue实现的。我们可以说DelayQueue = BlockingQueue + PriorityQueue + Delayed;
public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E> { private final transient ReentrantLock lock = new ReentrantLock(); private final PriorityQueue<E> q = new PriorityQueue<E>();
查看器take方法的实现,可以了解到它确实是根据元素的延迟期来决定是否可读的:
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { for (;;) { E first = q.peek(); if (first == null) available.await(); else { long delay = first.getDelay(NANOSECONDS); if (delay <= 0) return q.poll(); first = null; // don't retain ref while waiting if (leader != null) available.await(); else { Thread thisThread = Thread.currentThread(); leader = thisThread; try { available.awaitNanos(delay); } finally { if (leader == thisThread) leader = null; } } } } } finally { if (leader == null && q.peek() != null) available.signal(); lock.unlock(); } }
11、LinkedTransferQueue
LinkedTransferQueue=ConcurrentLinkedQueue+SynchronousQueue (in “fair” mode)+LinkedBlockingQueue,LinkedTransferQueue实现了一个重要的接口TransferQueue,该接口含有下面几个重要方法:
1. transfer(E e)
若当前存在一个正在等待获取的消费者线程,即立刻移交之;否则,会插入当前元素e到队列尾部,并且等待进入阻塞状态,到有消费者线程取走该元素。
2. tryTransfer(E e)
若当前存在一个正在等待获取的消费者线程(使用take()或者poll()函数),使用该方法会即刻转移/传输对象元素e;
若不存在,则返回false,并且不进入队列。这是一个不阻塞的操作。
3. tryTransfer(E e, long timeout, TimeUnit unit)
若当前存在一个正在等待获取的消费者线程,会立即传输给它; 否则将插入元素e到队列尾部,并且等待被消费者线程获取消费掉,
若在指定的时间内元素e无法被消费者线程获取,则返回false,同时该元素被移除。
4. hasWaitingConsumer()
判断是否存在消费者线程
5. getWaitingConsumerCount()
获取所有等待获取元素的消费线程数量