goroutine 和 thread
- thread
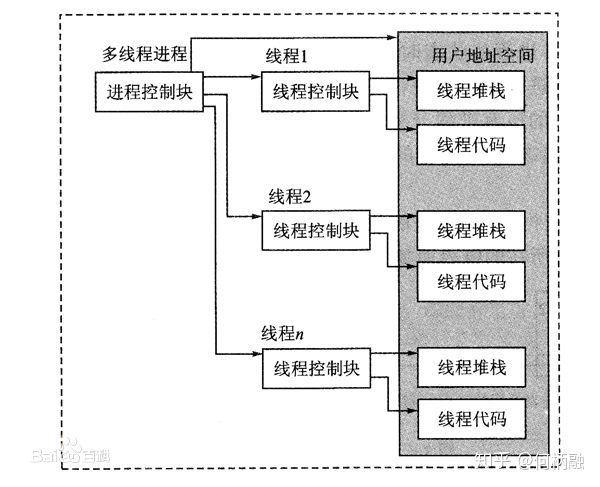
linux线程本质是轻量级进程,
线程的特点是资源共享,意思就是线程之间共享进程的内存空间,所以一个线程可以访问另一个线程的局部变量,
线程也有自己独立的堆栈,用户的代码逻辑可以在这些堆栈上执行。
当用户启动一个线程时,需要指定一个
让该线程执行的起始函数和
该函数的参数,
那么线程要做的事情就是去执行用户指定的函数。而且在线程里可以创建另一个线程。
- 内存占用
创建一个 goroutine 的栈内存消耗为 2 KB,
实际运行过程中,如果栈空间不够用,会自动进行扩容。
创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。
对于一个用 Go 构建的 HTTP Server 而言,对到来的每个请求,创建一个 goroutine 用来处理是非常轻松的一件事。而如果
用一个使用线程作为并发原语的语言构建的服务,
例如 Java 来说,每个请求对应一个线程则太浪费资源了,很快就会出 OOM 错误(OutOfMermoryError)。
- 创建和销毀
Thread 创建和销毀都会有巨大的消耗,
因为要和操作系统打交道,是内核级的,
通常解决的办法就是线程池。而
goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。
- 切换
当 threads 切换时,需要保存各种寄存器,以便将来恢复:
16 general purpose registers,
PC (Program Counter),
SP (Stack Pointer),
segment registers,
16 XMM registers,
FP coprocessor state,
16 AVX registers,
all MSRs etc.
而 goroutines 切换只需保存三个寄存器:
Program Counter,
Stack Pointer and
BP。
一般而言,线程切换会消耗 1000-1500 纳秒,一个纳秒平均可以执行 12-18 条指令。所以由于线程切换,执行指令的条数会减少 12000-18000。
Goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。
因此,goroutines 切换成本比 threads 要小得多。
m:n模型
Go runtime 会负责 goroutine 的生老病死,从创建到销毁整个生命周期,都一手包办。
Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),
之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。这就是 M:N 模型:
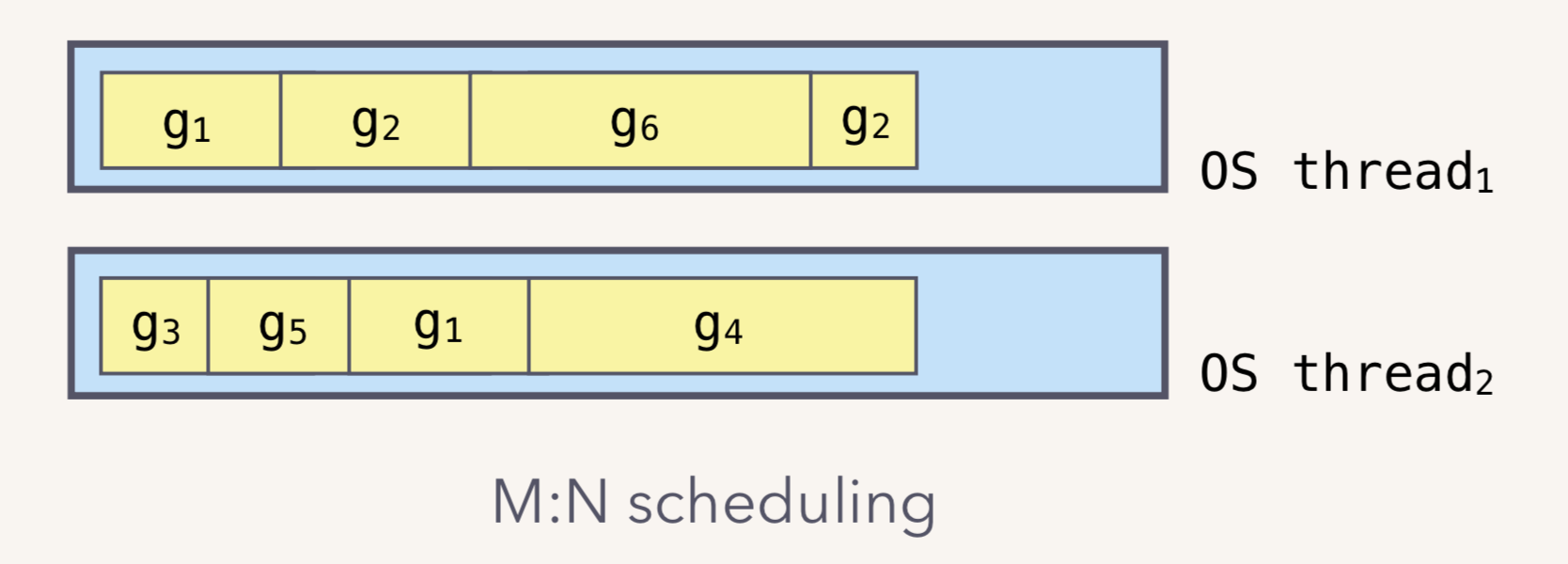
在同一时刻,一个线程上只能跑一个 goroutine。
当 goroutine 发生阻塞(例如上篇文章提到的向一个 channel 发送数据,被阻塞)时,runtime 会把当前 goroutine 调度走,让其他 goroutine 来执行。
目的就是不让一个线程闲着,榨干 CPU 的每一滴油水。
什么是 scheduler
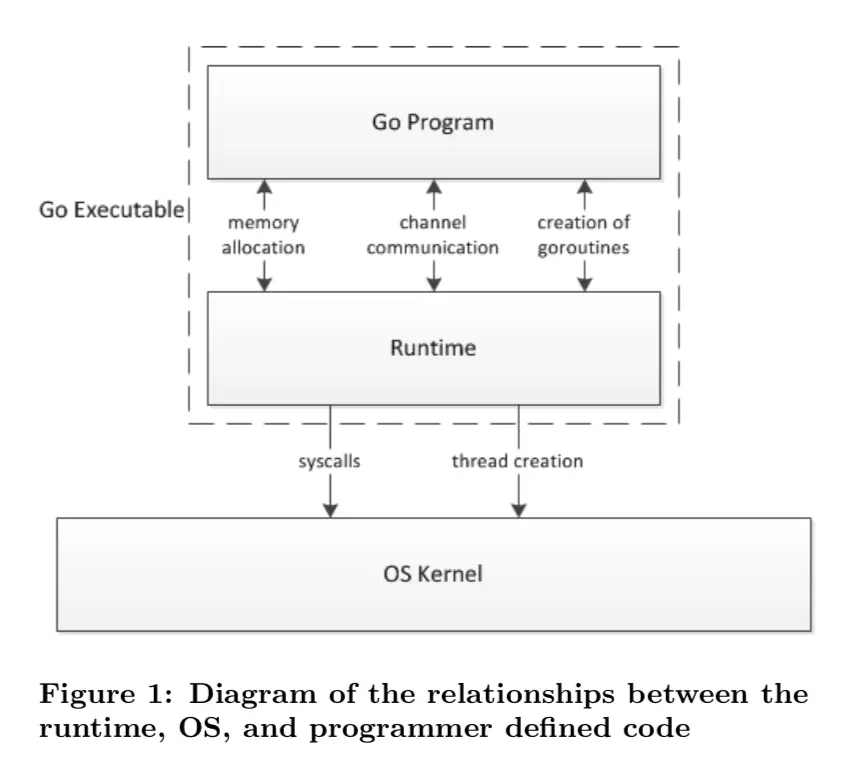
Go 程序的执行由两层组成:
Go Program
Runtime,即用户程序和运行时。
它们之间通过函数调用来实现
内存管理、
channel 通信、
goroutines 创建等功能。
用户程序进行的系统调用都会被 Runtime 拦截,以此来帮助它进行调度以及垃圾回收相关的工作。
为什么要 scheduler
Go scheduler 可以说是 Go 运行时的一个最重要的部分了。
Runtime 维护所有的 goroutines,并通过 scheduler 来进行调度。
Goroutines 和 threads 是独立的,
但是 goroutines 要依赖 threads 才能执行。
Go 程序执行的高效和 scheduler 的调度是分不开的。
scheduler 底层原理
实际上在操作系统看来,所有的程序都是在执行多线程。
将 goroutines 调度到线程上执行,仅仅是 runtime 层面的一个概念,在操作系统之上的层面。
scheduler有三个基础的结构体来实现 goroutines 的调度。g,m,p。
G(goroutine)
调度系统的最基本单位goroutine,存储了
goroutine的执行stack信息、
goroutine状态以及
goroutine的任务函数等。
在G的眼中只有P,P就是运行G的“CPU”。P保存了需要执行的那些goroutine;
相当于两级线程
// 每个g的实例都有任务函数,如下代码, 任务函数是userFunc
userFunc := func() {
fmt.Println("hi boya!")
}
go userFunc()
P(processor)
P表示逻辑processor,代表线程M的执行的上下文。
P的最大作用是其拥有的各种G对象队列、链表、cache和状态。
P的数量也代表了golang的执行并发度,即有多少goroutine可以同时运行
这里的p虽然表示逻辑处理器,但P并不执行任何代码,
对G来说,P相当于CPU核,G只有绑定到P才能被调度。
对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等
M(machine)
M代表着真正的执行计算资源,可以认为它就是os thread(系统线程)。
M是真正调度系统的执行者,每个M就像一个勤劳的工作者,总是从各种队列中找到可运行的G,而且这样M的可以同时存在多个。
M在绑定有效的P后,进入调度循环,而且M并不保留G状态,这是G可以跨M调度的基础。
在整个go调度的层面,对外的是M,P会找到一个M,让它去与外面的线程交互,从而去真正执行程序。
- GPM的关系示意图
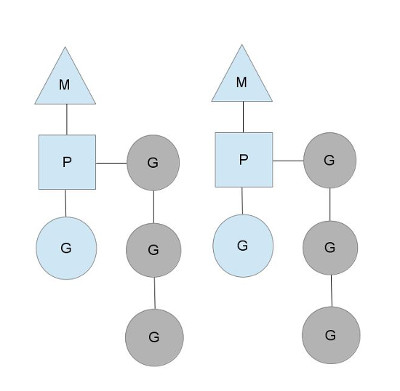
通过连线可以看出来,
M和P有关联,
G和P有关联,
但M和G没有关联, 这是为何G可以在不同的M上执行的本质原因。g眼中之后p, p选一个m执行, 对外的是M
当然还有一个核心的结构体:sched,它总览全局。
Runtime 起始时会启动一些 G:
垃圾回收的 G,
执行调度的 G,
运行用户代码的 G;
并且会创建一个 M 用来开始 G 的运行。
随着时间的推移,更多的 G 会被创建出来,更多的 M 也会被创建出来。
- src/runtime/runtime2.go
type g struct {...
type m struct {...
type p struct {...
type schedt struct {...

Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 global runqueues。这是一个全局的 runqueue,优先级比较低,以示惩罚。
总览
通常讲到 Go scheduler 都会提到 GPM 模型,我们来一个个地看。
下图是我使用的 mac 的硬件信息,只有 2 个核。
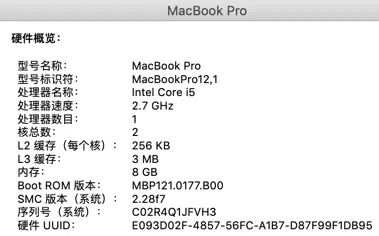
func main() {
// NumCPU 返回当前进程可以用到的逻辑核心数
fmt.Println(runtime.NumCPU()) //因为 NumCPU 返回的是逻辑核心数,而非物理核心数,所以最终结果是 4。
}
当我在本地启动一个 Go 程序时,会得到 4 个系统线程去执行任务,每个线程会搭配一个 P。
G、P、M 都说完了,还有两个比较重要的组件没有提到: 全局可运行队列(GRQ)和本地可运行队列(LRQ)。 LRQ 存储本地(也就是具体的 P)的可运行 goroutine,GRQ 存储全局的可运行 goroutine,这些 goroutine 还没有分配到具体的 P。
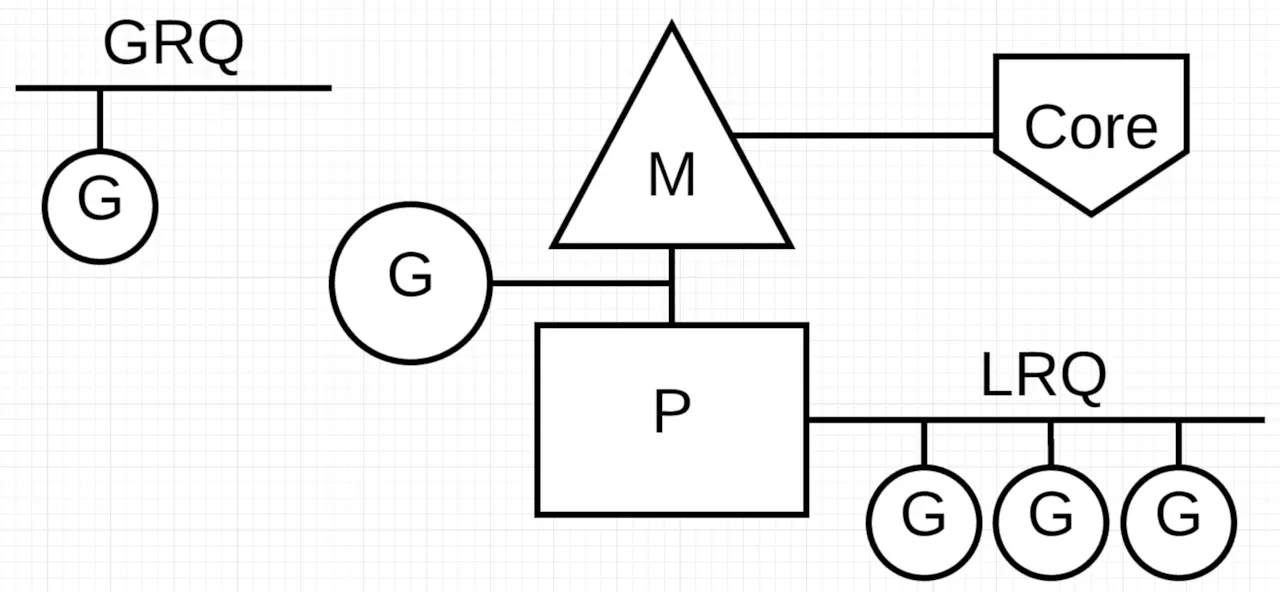
Go scheduler 是 Go runtime 的一部分,它内嵌在 Go 程序里,和 Go 程序一起运行。因此它运行在用户空间,在 kernel 的上一层。和 Os scheduler 抢占式调度(preemptive)不一样,Go scheduler 采用协作式调度(cooperating)。
work stealing
Go scheduler 的职责就是将所有处于 runnable 的 goroutines 均匀分布到在 P 上运行的 M。
当一个 P 发现自己的 LRQ 已经没有 G 时,会从其他 P “偷” 一些 G 来运行。看看这是什么精神!自己的工作做完了,为了全局的利益,主动为别人分担。这被称为 Work-stealing,Go 从 1.1 开始实现。
Go scheduler 使用 M:N 模型,在任一时刻,M 个 goroutines(G) 要分配到 N 个内核线程(M),这些 M 跑在个数最多为 GOMAXPROCS 的逻辑处理器(P)上。每个 M 必须依附于一个 P,每个 P 在同一时刻只能运行一个 M。如果 P 上的 M 阻塞了,那它就需要其他的 M 来运行 P 的 LRQ 里的 goroutines。
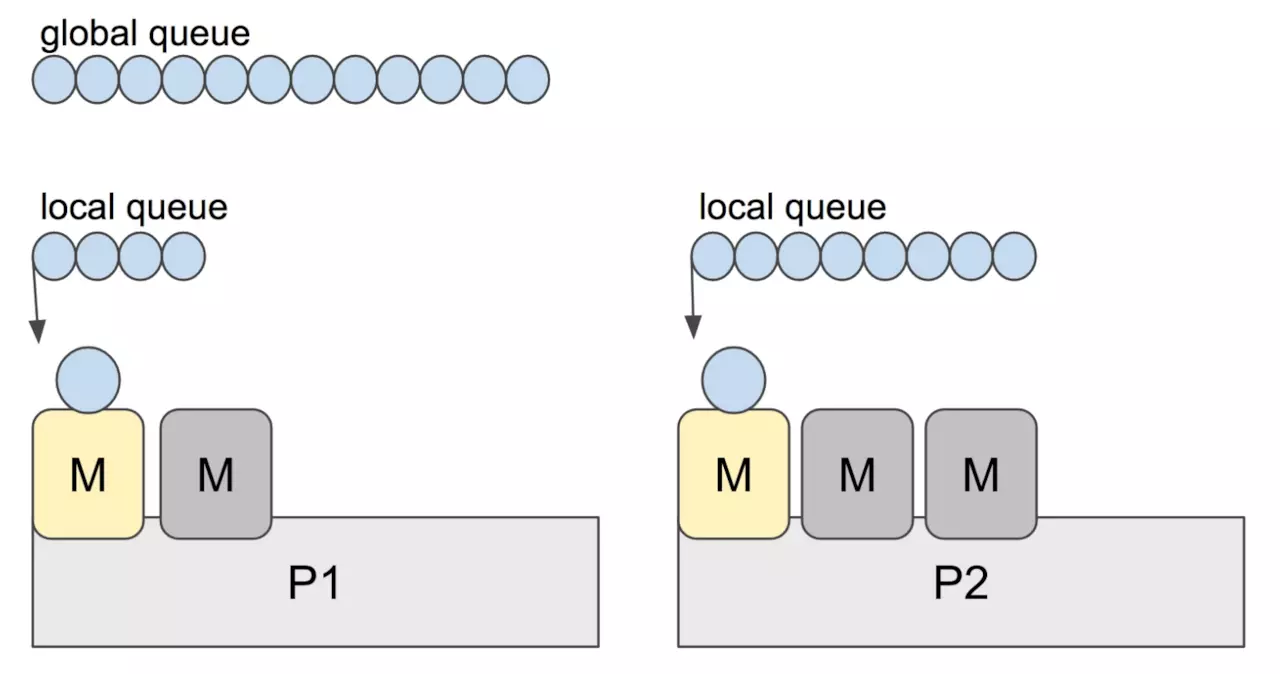
个人感觉,上面这张图比常见的那些用三角形表示 M,圆形表示 G,矩形表示 P 的那些图更生动形象。
找到一个可执行的 goroutine 后,就会一直执行下去,直到被阻塞。
当 P2 上的一个 G 执行结束,它就会去 LRQ 获取下一个 G 来执行。如果 LRQ 已经空了,就是说本地可运行队列已经没有 G 需要执行,并且这时 GRQ 也没有 G 了。这时,P2 会随机选择一个 P(称为 P1),P2 会从 P1 的 LRQ “偷”过来一半的 G。
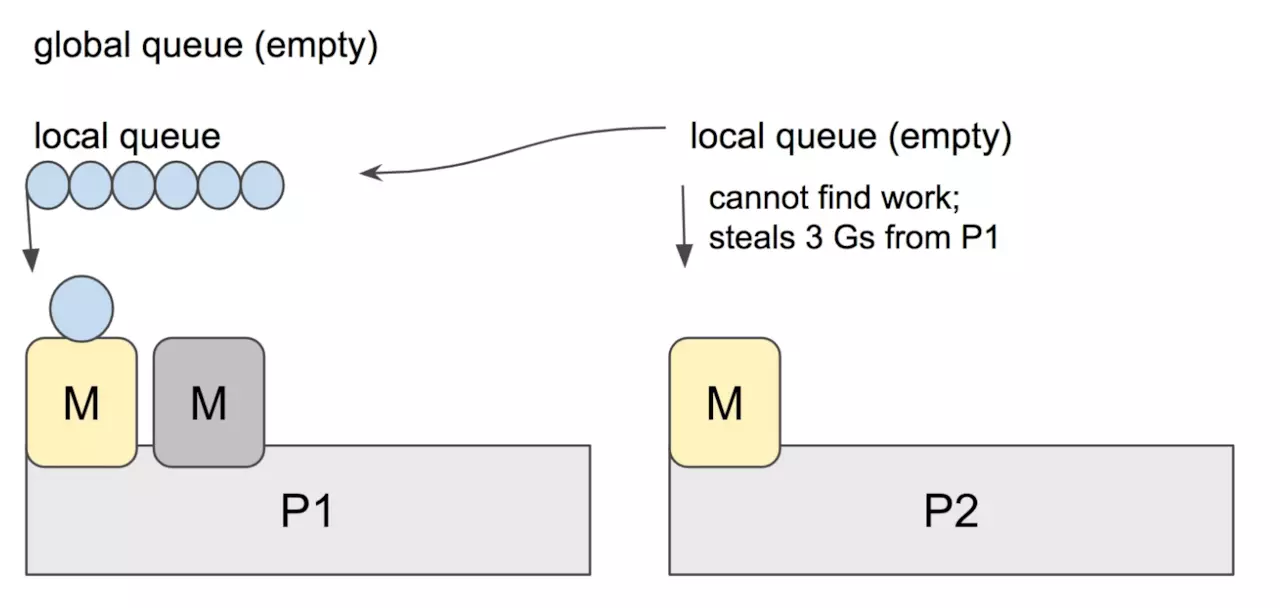
这样做的好处是,有更多的 P 可以一起工作,加速执行完所有的 G。
调度中存在的问题
问题1 G不均
我们知道,现实情况有的goroutine运行的快,有的慢,那么势必肯定会带来的问题就是,忙的忙死,闲的闲死,go肯定不允许摸鱼的P存在,势必要榨干所有劳动力。
如果你没有任务,那么,我们看到模型中还有一个全局G队列的存在,如本地队列已满,会一次性转移半数到全局队列。其他闲的小伙子就会从全局队列中拿;(顺便说一下,优先级是先拿下一个需要执行的,然后去本地队列中拿,再去全局队列中拿,先把自己的做完再做别人的嘛)同时如果全局都没有了,就会去抢别人的做。
问题2 任务卡主了
万一有个程序员启动一个goroutine去执行一个任务,然后这个任务一直睡觉(sleep)就是循环睡觉,那咋办嘛!你作为执行人,你总不能说,让它一直占用着一整个线程的资源,然后后面的goroutine都卡主了,那如果只有一个核心P,不就完蛋了?聪明的go才不会那么傻,它采用了抢占式调度来解决这个问题。只要你这个任务执行超过一定的时间(10ms),那么这个任务就会被标识为可抢占的,那么别的goroutine就可以抢先进来执行。只要下次这个goroutine进行函数调用,那么就会被强占,同时也会保护现场,然后重新放入P的本地队列里面等待下次执行。
谁来做的呢?
sysmon,就是这个背后默默付出的人,它是一个后台运行的监控线程,它来监控那些长时间运行的G任务然后设置可以强占的标识符。(同时顺便提一下,它还会做的一些事情,例如,释放闲置的span内存,2分钟的默认gc等)
问题3 阻塞可怎么办?
我们经常使用goroutine还有一个场景就是网络请求和IO操作,这种阻塞的情况下,我们的G和M又会怎么做呢?
这个时候有个叫做netpoller的东西出现了,当每次有一个网络请求阻塞的时候,如果按照原来的方法这个时候这个请求会阻塞线程,而有了netpoller这个东西,可以将请求阻塞到goroutine。
意思是说,当阻塞出现的时候,当前goroutine会被阻塞,等待阻塞notify,而放出M去做别的g,而当阻塞恢复的时候,netpoller就会通知对应的m可以做原来的g了。
同时还要顺便提一句,当P发现没有任务的时候,除了会找本地和全局,也会去netpoll中找。
问题4 系统方法调用阻塞?
还有一个问题,我们自己想可能比较难想到,就是当调用一些系统方法的时候,如果系统方法调用的时候发生阻塞就比较麻烦了。下面引用一段话:
当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于block on syscall状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。