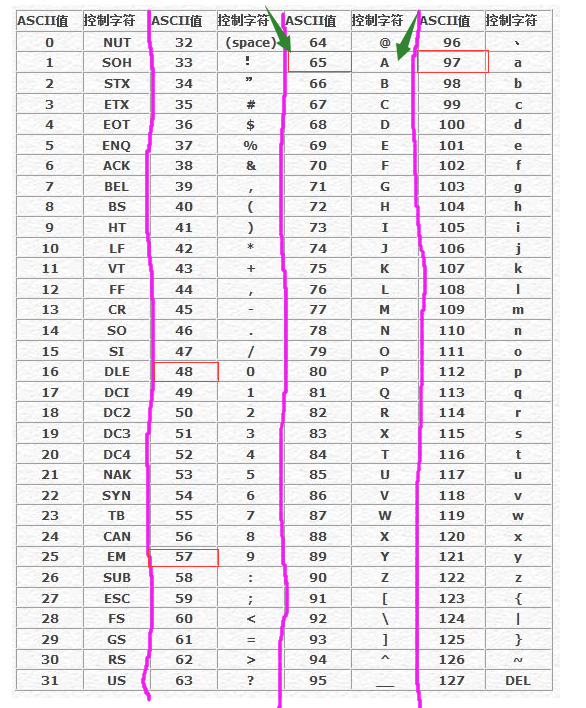
一,ASCII编码。
1、在计算机中,所有的数据在存储和运算时都要使用二进制数表示。而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则。是用7位二进制位表示的,范围是:0000 0000 到 0111 1111。即表示从0~127,一共128个状态,对应128个符号。一般都是用8位二进制位表示ASCII,最高位全部都默认为0。这样就实现了现实生活中符号用计算机表示出来。ASCII定义了128个字符,包括33个不可打印的控制字符(non-printing control characters)和95个可打印的字符。32以下的及最后一个127是所谓的控制字符。(0x00~0x1F以及0x7F)。
2、由ASCII表可以知道:数字 < 大写字母 < 小写字母。
3、字符与二进制之间的一一对应关系如下:
一,LATIN1编码。ISO-8859-1编码是单字节编码,向下兼容ASCII。其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。ISO-8859-1又称Latin-1,是一个8位单字节字符集,它把ASCII的最高位也利用起来,并兼容了ASCII,新增的理论空间是128,但它并没有完全用完。可以看到,新增部分也保留了前面的32个位置(中间绿色部分,0x80-0x9F),与前面的ASCII部分类似,所以实际只增加了128-32=96个,主要是西欧的一些字符,另外可以看到乘号(0xD7)和除号(0xF7)也被包含进来了。
一,Unicode编码。
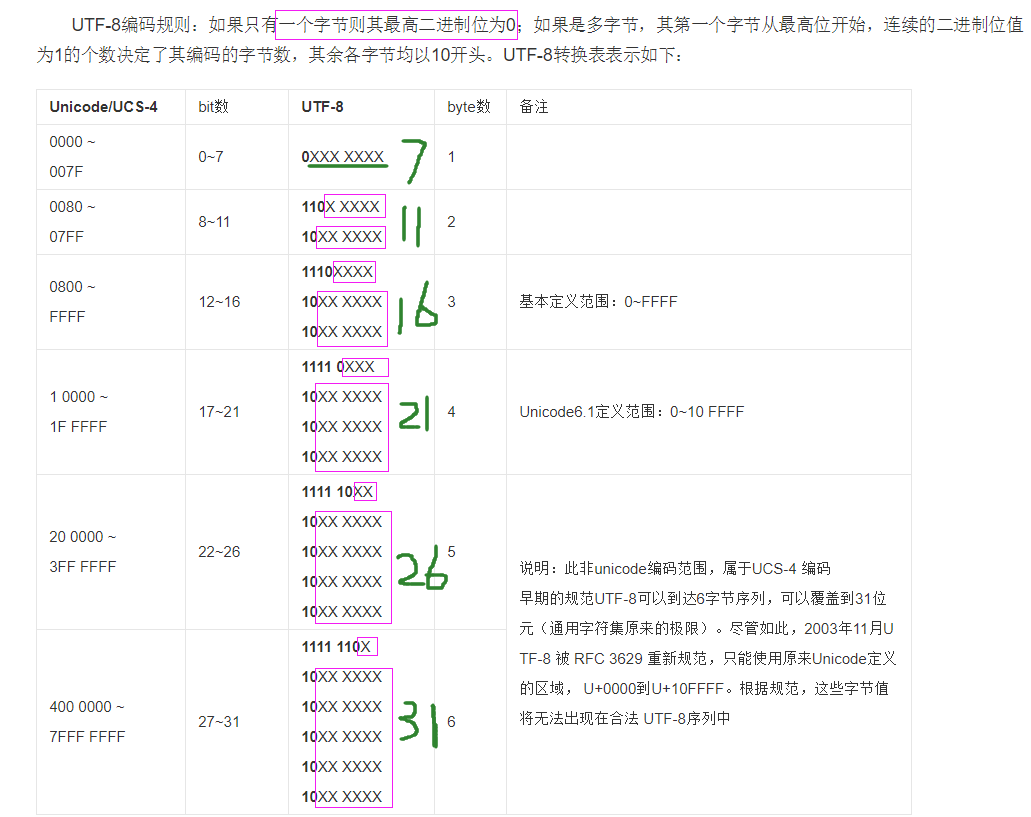
一,UFT-8编码。按照Unicode编码,一个字符对应的Unicode码使用的bit位数,则对应到UTF-8的编码。实际表示ASCII字符的UNICODE字符,将会编码成1个字节,并且UTF-8表示与ASCII字符表示是一样的。所有其他的UNICODE字符转化成UTF-8将需要至少2个字节。每个字节由一个换码序列开始。第一个字节由唯一的换码序列,由n位连续的1加一位0组成, 首字节连续的1的个数表示字符编码所需的字节数。Unicode转换为UTF-8时,可以将Unicode二进制从低位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下示例所示的格式,前面按格式填补,不足8位用0填补。
一,UTF16编码。UTF-16是Unicode的其中一个使用方式。因为Unicode他是由2个byte组成的,但是大多数UTF-16也是2个byte组成的,也有4个byte组成的,如:中国文字大部份是两字节,有的是四字节。UTF-16却无法相容于ASCII编码。
1、Unicode值小于0x10000的用等于该值的16位整数来表示。0x00 00 ~ 0xFF FF 。
2、Unicode值介于0x10000和0x10FFFF之间的,即0x1 00 00 ~ 0x10 FF FF。用一个值介于0xD800和0xDBFF(在所谓的高8位区)的16位整数和值介于0xDC00和0xDFFF(在所谓的低8位区)的16位整数来表示。
3、Unicode值大于0x10FFFF不能按照UTF-16进行编码。


一,UTF32编码。