一、HashMap的概念。
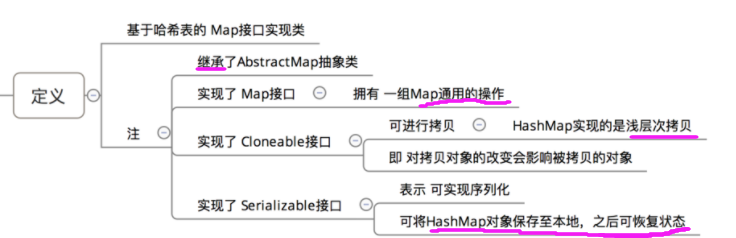
1、HashMap类的继承实现关系如下:因此HashMap的功能有:可序列化、可克隆等功能。

2、HashMap的数据结构:数组+链表+红黑树。
3、键值对的存储方案:第一,无冲突时,则存储在数组;第二,有冲突时,且链表长度小于8,则存放在单链表;第三,有冲突时,且链表长度大于8,则存放在红黑树。

二、HashMap中的内部类。
1、数组元素和单链表节点的数据类型是Node类,而红黑树的节点类是TreeNode类。


三、HashMap中的成员变量。
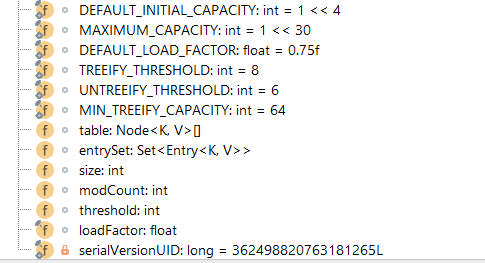
1、容量(capacity),代表该HashMap的数组大小。DEFAULT_INITIAL_CAPACITY表示数组的默认容量,值为16;MAXIMUM_CAPACITY表示容量最大值,值为2的30次方。
2、加载因子(loadFactor),表示数组的使用率。loadFactor表示实际的加载因子;DEFAULT_LOAD_FACTOR表示默认加载因子,值为0.75。
3、扩容阀值(threshold),表示当哈希表的大小大于该扩容阀值时,就会进行扩容,即调用resize方法。扩容阀值 = 实际容量 × 实际加载因子。
4、键值对数量(size),表示实际存储的键值对大小。
5、哈希表(table),代表实际存储的数组。最重要了。
6、树化阀值(TREEIFY_THRESHOLD),表示桶的树化阀值,大小为8,即单链表转换成红黑树的阀值。当单链表长度大于该值8时才会转换。
7、链表还原阀值(UNTREEIFY_THRESHOLD),表示红黑树转换为单链表结构。
8、最小树形化容量阈值(MIN_TREEIFY_CAPACITY)。即当哈希表中的容量 > 该值时,才允许树形化链表 (即将链表转换成红黑树) ,否则,若桶内元素太多时,则直接扩容,而不是树形化 // 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD。转化红黑树的table容量最小容量64(JDK8定义的是64),至少是4*TREEIFY_THRESHOLD(单链表节点个数阀值,用以判断是否需要树形化)=32。用以避免 在扩容和树形结构化的阀值 可能产生的冲突。所以如果小于64必须要扩容。如果在创建HashMap实例时没有给定capacity、loadFactor则默认值分别是16和0.75。
当好多bin被映射到同一个桶时,如果这个桶中bin的数量小于TREEIFY_THRESHOLD当然不会转化成树形结构存储;如果这个桶中bin的数量大于了 TREEIFY_THRESHOLD ,但是capacity小于MIN_TREEIFY_CAPACITY 则依然使用单链表结构进行存储,此时会对HashMap进行扩容;如果capacity大于了MIN_TREEIFY_CAPACITY ,则会进行树化。

public HashMap(int initialCapacity, float loadFactor)
四、HashMap的成员方法。
1、构造方法1。指定容量和加载因子。public HashMap(int initialCapacity, float loadFactor)。先处理入参,后初始化成员变量:加载因子loadFactor和扩容阀值threshold。注意:这里用到了tableSizeFor函数。

2、构造方法2:指定容量。public HashMap(int initialCapacity)。并使用默认加载因子0.75。

3、构造方法3:使用默认容量16和默认加载因子0.75。public HashMap()。

4、构造方法3:public HashMap(Map<? extends K, ? extends V> m)

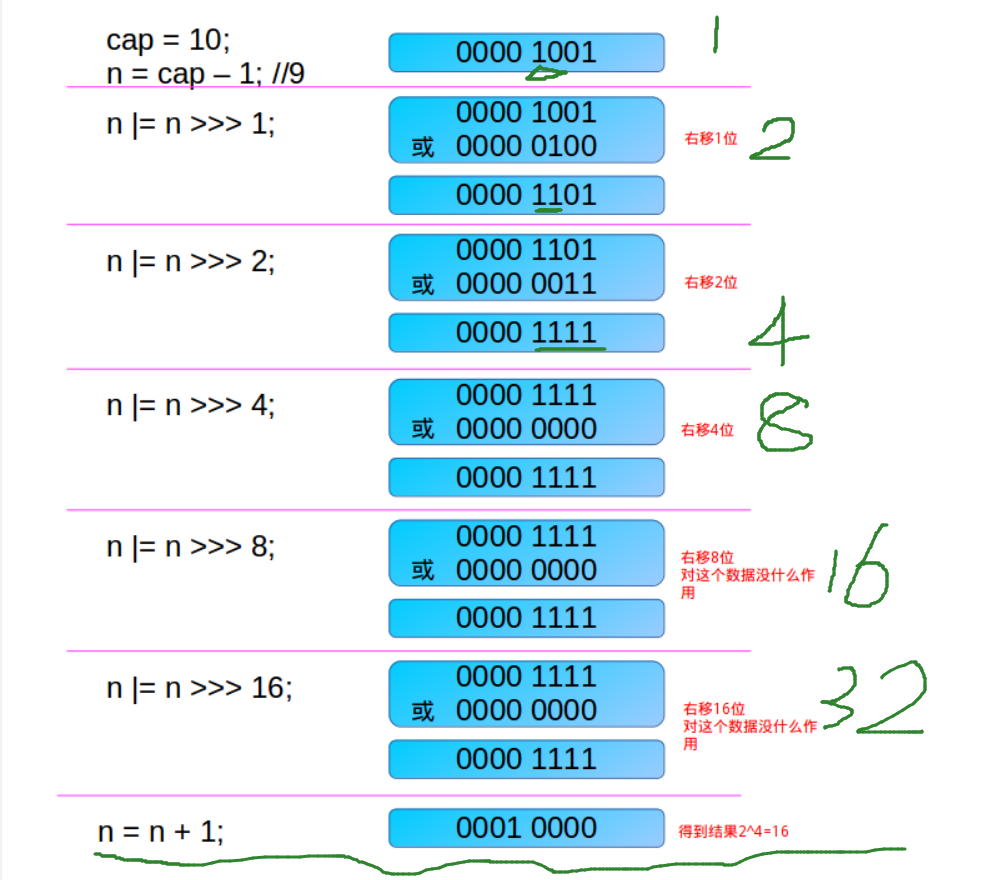
5、tableSizeFor函数。该函数功能是返回一个比给定整数大且最接近的2的幂次方整数int类型,如给定10,返回2的4次方16。该算法实在精巧。
首先,为什么要对cap做减1操作。int n = cap - 1; 这是为了防止,cap已经是2的幂。如果cap已经是2的幂, 又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。
其次,n与n的无符号右移之后再进行位或运算。当n = 0时,其无符号右移操作后还是为0,然后与0进行或运算,结果为0。
当n为一个正整数时,那么由于n不等于0,则n的二进制表示中总会有一位为1,这时考虑最高位的1。通过无符号右移1位,则将最高位的1右移了1位,再做或操作,使得n的二进制表示中与最高位的1紧邻的右边一位也为1,比如n = 0...1XXXXXX,进行后移之后为00...1XXXXX,然后两者进行或运算之后为:00...11XXXXX。即这是 n |= n >>> 1这句表达的含义。最高位和次高位都为1。(2位1)
进行:n |= n >>> 2的作用,则是将上述结果变为:0...1111XXX。由于经过前面一次操作将最高位和次高位都为1,再右移动两位后再或操作,结果是:最高位和最高位后面的三位都是1,即:0...1111XXX。(4位1)
进行:n |= n >>> 4的作用,则是将上述结果变成:0...1111111。(7位1)。
进行:n |= n >>> 8的作用,则是将上述结果变成:0...1111111。(7位1)。
进行:n |= n >>> 16的作用,则是将上述结果变成:0...1111111。(7位1)。
因此分别进行1位、2位、4位、8位、16位无符号右移再或运算,逐步将最高为的1及后面的所有位数都变成1,结果就是将类似0...1XXX ... XXXX的树变成0...1111 ... 1111。即最大能达到32位1。
最后判断n的值:负数/最大值/正常值+1。
顶顶顶顶顶顶顶

6、hash函数。先获取键对象的hashCode,即哈希码,然后将该哈希码与该哈希码无符号右移16位相异或。因为一个int整数无符号右移16位后,高16位全部为0,低16位被高16位替换。那么相与操作时,因为该哈希码的高16位与0异或就是本身,因此该哈希码的高16位运算之后不会改变,这里运用了一个数与0异或后不会改变的性质。而低16位的结果则是该哈希码的低16位与该哈希码的高16位进行异或运算。这就搅动了低16位的hashCode值。
(1)为何不直接使用key的hashCode码作为存储数组table的下标索引?因为key的hashCode码是int型的32位数值,即约有40亿个不同值,如果让其直接作为数组下标索引而不会出现下标索引越界,那么数组下标的范围就必须达到最大值,即2的30次方,然而这会耗费巨大的空间,正常程序是不会需要这么大的空间的,同时设备也不一定能提供这么大的空间。即需要解决hashCode码与数组大小的匹配关系。
(2)为什么在计算数组下标前需要扰动处理?因为实际上只能根据数组长度length的大小来截取hash码的低length - 1位来作为数组下标的索引?如果直接截取hashcode的低位作为数组下标的索引,那么导致冲突的概率较大,因此使用高16位来扰动低16位将会使hash码值分布更加具有均匀性,数组下标位置更加具有随机性。
(3)为什么采用hash码与运算(数组长度 - 1)?因为,经过前面两步获取到了key的hashCode值,其中高16位不变,而低16位是经过高16位与原低16位进行异或运算的扰动结果,但是还是32位,而数组长度不会那么大,因此需要解决数组下标索引与hash值之间的匹配问题。又因为数组长度length是2的N次方。所以length-1就是低位全部是1,高位全部是0。比如length= 0000 1000 0000,那么length-1就是:0000 0111 1111,那么将length-1与hash值进行与运算来截取hash值的低位作为数组下标索引值。这里运用了与运算来截取位的性质。




7、扩容函数。在插入键值对时,且发现容量不足,则执行扩容操作。两种情况:一是初始化哈希表;二是发现当前数组容量不足。
思路:先保存旧的table,旧的table长度,旧的扩容阀值。



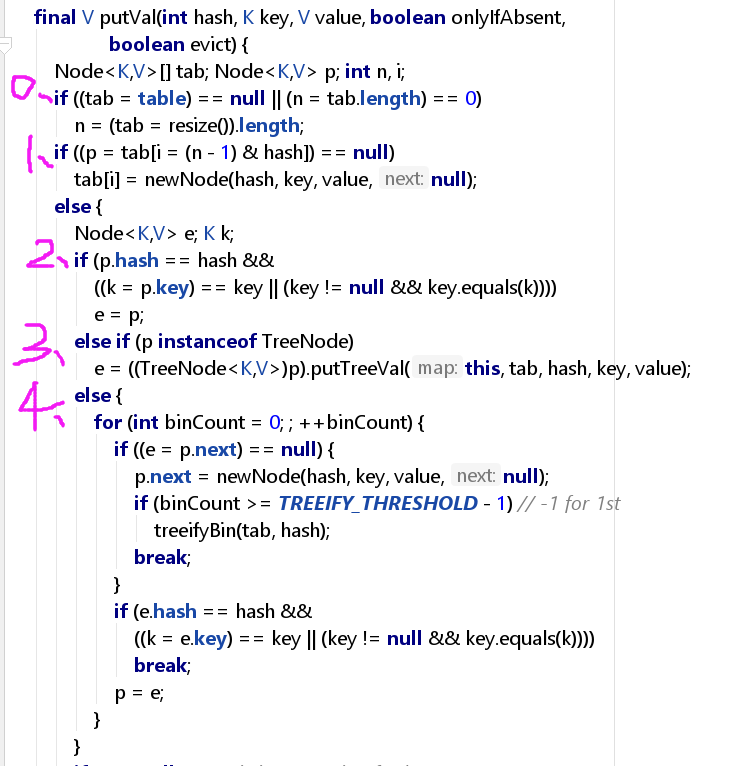
8、put方法。先put,计算出hash,然后调用putVal方法。先判断哈希表为空或长度为0时,则初始化哈希表或更新哈希表容量resize。然后分四种情况插入:
(1)如果该键对象的哈希表索引处为null,则表示该位置没有被使用,即直接插入哈希表数组;
(2)如果哈希表索引处的键对象与插入的键对象相等,则直接更新原来的键对象的值;
(3)如果该键对象的索引处的键的类型为红黑树类型,则插入到红黑树;
(4)如果该键对象的索引处的键的类型为单链表类型,则插入到单链表;
最后更新修改次数modCount,更新键值对数量size,比较size与threshold大小来判断否超过扩容阀值,若超过,则扩容resize。


9、get方法。分四种情况讨论获取的值,一是为null;二是该key对象对应的哈希表索引处就是该键对象,即相等,则直接返回该处的键的值;三是红黑树节点;四是单链表节点。


10、size方法。获取键值对数量。

11、isEmpty方法。判断该hashmap的键值对数量是否为0。

12、containsKey方法。判断该hashmap是否含有该键的键值对。


13、containsValue方法。判断该hashmap是否含有该值的键值对。

14、clear方法。清除哈希表数据。

15、replace方法。替换键值对为新的值,但是键相同。前一个提供原来的键的值,后一个直接用新值替换旧值。


10、remove方法。前一个删除指定键的键值对。后一个删除指定键和值的键值对。


与Hashtable的区别。
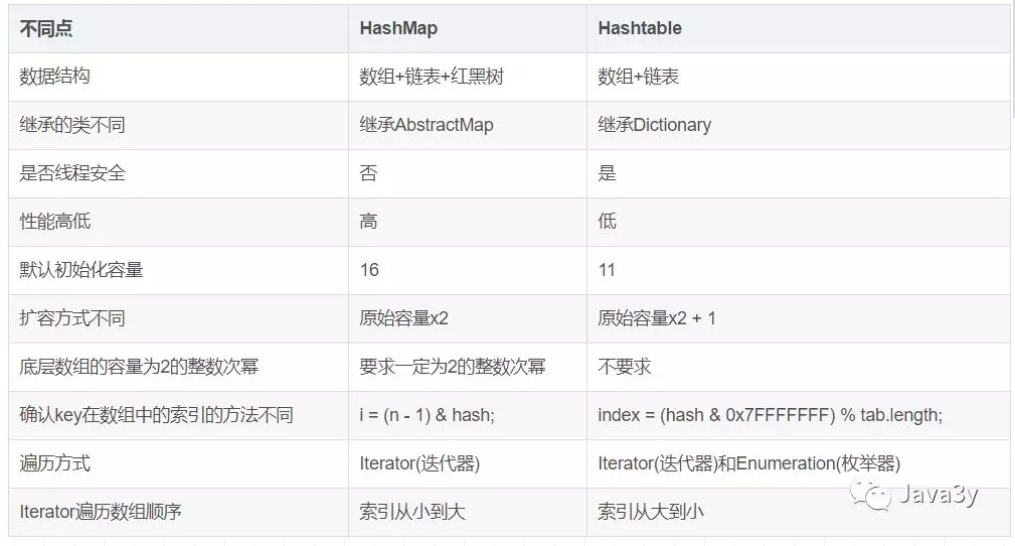
分个分隔符个