Qt版本有用4的版本的也有用5的版本,并且还有windows与linux跨平台的需求。
经常出现个问题是windows的解决了,源代码放到linux上编译不通过或者中文会乱码,本文主要是得出一个解决方案能解决Qt的中文问题,并支持不同平台与不同版本。
测试:
#include <QtGui/QApplication> #include <QtGui/QLabel> int main(int argc, char **argv) { QApplication app(argc, argv); QString a= "我是汉字"; QLabel label(a); label.show(); return app.exec(); }
编码,保存,编译,运行,一切都很顺利,可是结果呢:
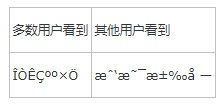
出现乱码!!!
1. 使用场景
Qt版本: Qt5.1.0_VS2012
操作系统: win7
CPP文件编码: UTF8—无BOM格式
CPP部分代码如下:
QTextCodec::setCodecForLocale(QTextCodec::codecForName("UTF8")); QString strMessage = QString::fromLocal8Bit("我是UTF8编码的文件:")); qDebug() << strMessage;
试着编译下你会发现编译出错:error C2001: newline in constant
为什么呢?因为UTF8分为UTF8-无BOM和UTF8-BOM
UTF8-BOM其实就是比UTF8-无BOM多了几个字节的文件头,用于和UTF-16与UTF-32区分的。
而:windows识别的UTF8是指UTF-BOM(你可以使用记事本另存为UTF8格式后查看)。
因为有中文冒号:的存在故此UTF8-无BOM文件格式使用VS的Cl编译器是无法识别为UTF8的格式,只能当成ANSI来读取解析编译,故编译出错。
那就有人会说那我就把CPP的文件格式改为:UTF8—BOM格式。
因此对于源码文件.cpp,.h 文件,如果用NodePad++ 打开。(1)如果用UTF-8无BOM格式编码打开保存,则导致再VS2013中编译后的Q他程序,通过:QString::fromLocal8Bit(“中国人民”),则会出现乱码。(2)如果通过UTF-8格式编码,则,可以顺利通过编译QString::fromLocal8Bit(“中国人民”), 没有乱码。

2. 编译器对不同编码的处理
我们只列举大家最常用的3个编译器(微软VS的中的cl,Mingw中的g++,Linux下的g++),源代码分别采用GBK 和不带BOM的UTF-8 以及 带BOM的UTF-8 这3中编码进行保存。

3种不同编码保存的源代码文件,分别用3种不同的编译器编译,形成9种组合,除掉一种不能工作的情况,两种乱码出现的情况各占一半。
从中我们也可以看出,乱码和操作系统原本是没有关系的。
注意:
Windows 一般用的GBK
linux一般用的是不带BOM的UTF-8。如果我们只考虑带*的情况,也可以说两种乱码和系统有关。
3. 深层次理解
QString 为什么会乱码呢?我们可以问问自己,我们抱怨的对象是不是搞错了?
(1)明确概念1:
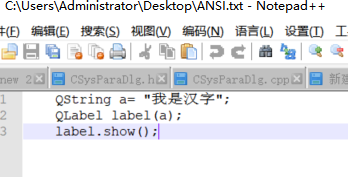
"我是汉字" 是C语言中的字符串,它是char型的窄字符串。上面的例子可写为
const char * str = "我是汉字"; QString a= str; 或者 char str[] = "我是汉字"; QString a= str;
(2)明确概念2
源文件是有编码的,但是这种纯文本文件却不会记录自己采用的编码
实验验证:
这个是问题的根源,不妨做个试验,将前面的源代码保存成GBK编码,用16进制编辑器能看到引号内是ce d2 ca c7 ba ba d7 d6这样8个字节。
用文本工具,另存为:UTF-8格式另存:
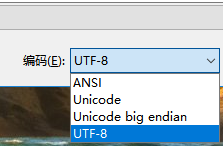
将该文件在: 欧洲人的Windows系统中的记事本打开;则显示:
... QString a= "ÎÒÊǺº×Ö"; QLabel label(a); label.show(); ...
将该文件在: 繁体字的的Windows系统中的记事本打开;则显
... QString a= "扂岆犖趼"; QLabel label(a); label.show(); ...
同一个文件,未做任何修改,但其中的8个字节ce d2 ca c7 ba ba d7 d6,对用GBK的大陆人,用BIG5的港澳台同胞,以及用Latin-1的欧洲人看来,看到的却是完全不同的文字。
UTF-8(含有BOM)以及(没有BOM)显示图下:
BIG5显示,如下图:
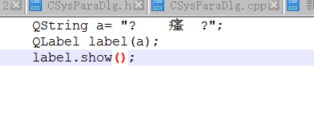
ANSI编码格式打开:

明确概念3:
GBK编码下的 const char * str = "我是汉字" 等价于 const char * str = "xcexd2xcaxc7xbaxbaxd7xd6"; 当用UTF-8编码时,等价于 const char * str = "xe6x88x91xe6x98xafxe6xb1x89xe5xadx97";
注意:这个说法不全对,比如保存成带BOM的UTF-8,用cl编译器时,汉字本身是UTF-8编码,但程序内保存时却是对应的GBK编码。
明确概念4:QString 内部采用的是Unicode。
QString内部采用的是 Unicode,它可以同时存放GBK中的字符"我是汉字",BIG5中的字符"扂岆犖趼" 以及Latin-1中的字符"ÎÒÊǺº×Ö"。
一个问题是,源代码中的这8个字节"xcexd2xcaxc7xbaxbaxd7xd6",该怎么转换成Unicode并存到 QString 内?按照GBK、BIG5、Latin-1还是其他方式...???
在你不告诉它的情况下,它默认选择了Latin-1,于是8个字符"ÎÒÊǺº×Ö"的unicode码被存进了QString中。最终,8个Latin字符出现在你期盼看到4中文字符的地方,所谓的乱码出现了!!!
乱码的产生!!!
4. QString 工作方式
const char * str = "我是汉字"; QString a= str;
其实很简单的一个问题,当你需要从窄字符串 char* 转成Unicode的QString字符串的,你需要告诉QString你的这串char* 中究竟是什么编码?GBK、BIG5、Latin-1
理想情况就是:将char* 传给QString时,同时告诉QString自己的编码是什么
就像下面的函数一样,QString的成员函数知道按照何种编码来处理 C 字符串
QString QString::fromAscii ( const char * str, int size = -1 ) QString QString::fromLatin1 ( const char * str, int size = -1 ) QString QString::fromLocal8Bit ( const char * str, int size = -1 ) QString QString::fromUtf8 ( const char * str, int size = -1 )
单QString 只提供了这几个成员函数,远远满足不了大家的需求,比如,在简体中文Windows下,local8Bit是GBK,可是有一个char串是 BIG5 或 Latin-2怎么办?
那就动用强大的QTextCodec吧,首先QTextCodec肯定知道自己所负责的编码的,然后你把一个char串送给它,它就能正确将其转成Unicode了。
QString QTextCodec::toUnicode ( const char * chars ) const
可是这个调用太麻烦了,我就想直接
QString a= str;
或
QString a(str);
这样用怎么办?
这样一来肯定没办法同时告诉 QString 你的str是何种编码了,只能通过其他方式了。这也就是开头提到的
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GBK")); QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8"));
设置QString默认采用的编码。而究竟采用哪一个,一般来说就是源代码是GBK,就用GBK,源代码是UTF-8就用UTF-8。但有一个例外,如果你保存成了带BOM的UTF-8而且用的微软的cl编译器,此时仍是GBK。
endl;