5.1神经元模型
神经网络的研究由来已久,关于其研究历史我将在本篇末进行介绍。
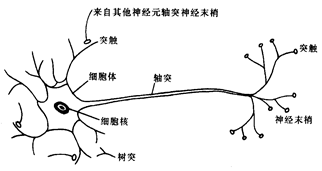
关于神经网络的定义,西瓜书采用的是:“神经网络是由具有适应性的简单单元组成的广泛并行互联的网络, 它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应”。我们在机器学习谈论神经网络时通常指的是“神经网络学习”,或者说是机器学习与神经网络这两个学科领域交叉部分。神经元模型即定义中提及的简单单元,是神经网络的基本组成。在生物中,生物神经网络是指:每个神经元与其他神经元相连, 当它“兴奋”时, 就会向相连的神经云发送化学物质, 从而改变这些神经元内的电位;如果某神经元的电位超过一个“阈值”, 那么它就会被激活, 即“兴奋”起来, 向其它神经元发送化学物质分。如下图所示:
在1943年,[McCulloch and Pitts, 1943]将上述情形抽象为下图所示的模型,也就是M-P模型:
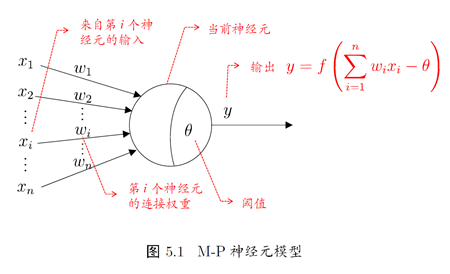
输入:来自其他n个神经云传递过来的输入信号
处理:输入信号通过带权重的连接进行传递, 神经元接受到总输入值将与神经元的阈值进行比较
输出:通过激活函数的处理以得到输出
5.2感知机与多层网络
在这里西瓜书给出的定义是:由两层神经元组成的如图 5.3 所示的输入层与输出层 M-P 神经元组成的一个网络。M-P 神经元亦称为“阈值逻辑单元”。 但是呢我觉得西瓜书说得不是很好,在此借用清华大学张学工老师出版的《模式识别》里的定义:感知机就是一种直接得到完整的线性判别函数 g(x) = w'x + b 的方法;(w和b都可以通过学习得到,下面将具体阐述:西瓜书只提了但是没有写的哦!)

两种定义有异曲同工之妙,都是对线性判别函数进行一种阈值的选择。但在非线性可分问题(逻辑异或)上无法求得合适解,对于非线性问题我在博客中也会进行扩充。在我看来西瓜书上说的感知机可以进行逻辑运算不过是代数的一种特殊值的方法,整出三种符合条件的逻辑来就可以印证了,这个没必要在博客里说明,如果想看到可以去看西瓜书P99。
西瓜书迭代方法介绍
我们想要得到这个线性函数,在神经网络这章肯定是利用训练的方法不断迭代,训练就必须要有损失函数,我们定义损失函数为误分类点数的总数。

神经网络的核心就是这,不断迭代更新参数一直到我们得到核心的符合要求的向量 W 。 若感知机对训练样例预测正确, 则感知机不发生变化;否则根据错误程度进行权重的调整.
模式识别迭代方法介绍
上面是W的迭代更新过程,下面我结合我自己在上的模式识别课程补充一下西瓜书不一样的内容:关于b 的更新确定,我们知道分类正确的例子定义为 w'x > 0 , 但是某些样本判别函数可能刚刚大于零,考虑到噪声、数值计算等误差我们有必要引入余量 b 也就是要求解向量w: w'x > b.

迭代修正公式的意思就是把错分的样本按照某个系数加到上一个权向量上去。 通常一次性将所有错误样本都进行修正的做法并不是效率最高的,更常用的是一次只修正一个样本的固定增量算法,算法步骤是:
- 任意选择初始权向量 w(0),置 t = 0
- 考察样本xi,若w(t)T xi <= b,则 w(t+1) = w(t) + xi (步长为1), 否则继续。
- 考察另一样本,重复2,直至所有样本w(t)T xi > b,即损失函数为0
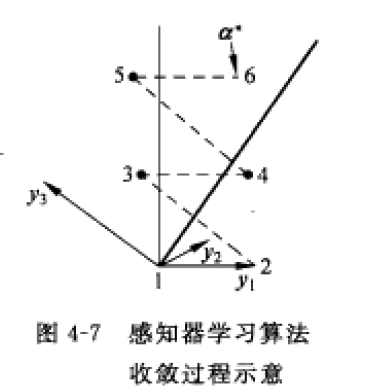
如图4-7位感知机的收敛学习算法过程,y1,y2,y3其实就是前面提到的x1,x2,x3。一直向量迭代相加即可。这里补充一下,前面收敛算法中步长定义为1,实际上为了减少迭代次数,科学家提出了使用可变的步长比如:
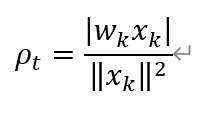
感知机算法是最简单并且可以学习的机器,只能解决线性可分的问题,感知机只有输出层神经元进行激活函数处理,即只拥有一层功能神经元,学习能力有限,只能去处理与、或、非之类的线性可分模型。若模型并不能线性分割,则感知机的学习过程会产生震荡,不能求得合适解,例如感知机不能求解“异或”这种非线性问题,利用多层感知机可以解决非线性问题。输入层与输出层之间有一个隐含层。

更一般的,常见的神经网络是形如下图的层级结构,这种结构也成位多层前馈神经网络:
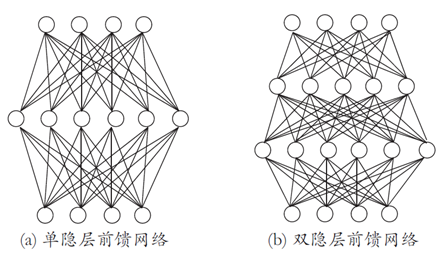
定义:每层神经元与下一层神经元全互联, 神经元之间不存在同层连接也不存在跨层连接
前馈:输入层接受外界输入, 隐含层与输出层神经元对信号进行加工, 最终结果由输出层神经元输出
学习:根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的“阈值”
多层网络:包含隐层的网络
5.3误差逆传播算法
多层网络的学习能力比单层感知机强得多,想训练多层网络,感知机的学习规则是不够的,需要更强大的学习算法。其中误差逆传播算法(BP)是其中最杰出的代表。


下面给出参数的优化手动推导全过程:


结合上述的参数给出下面BP算法流程:

下面是一个简单的示例:
一般来说,BP算法有两种:标准BP和累计BP算法。
标准BP:
- 每次针对单个训练样例更新权值与阈值.
- 参数更新频繁, 不同样例可能抵消, 需要多次迭代.
累计BP算法:
- 其优化的目标是最小化整个训练集上的累计误差
- 读取整个训练集一遍才对参数进行更新, 参数更新频率较低.
但在很多任务中, 累计误差下降到一定程度后, 进一步下降会非常缓慢, 这时标准BP算法往往会获得较好的解, 尤其当训练集非常大时效果更明显。
在多层前馈网络表达能力上,只需要一个包含足够多神经元的隐层, 多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数。[Hornik et al. , 1989] 但是也有其局限的地方:1.神经网络由于强大的表示能力, 经常遭遇过拟合. 表现为:训练误差持续降低, 但测试误差却可能上升 2. 如何设置隐层神经元的个数仍然是个未决问题. 实际应用中通常使用“试错法”调整 。我们对过拟合也有针对的方法:1. 早停:在训练过程中, 若训练误差降低, 但验证误差升高, 则停止训练 2.正则化:在误差目标函数中增加一项描述网络复杂程度的部分, 例如连接权值与阈值的平方和
5.4全局最小与局部极小
利用前馈计算得到的E作为表示神经网络在训练集上的整体误差,显然其是关于连接权值w和阈值θ的函数。而反向传播计算的过程则是一个寻优过程,旨在寻找一组最优参数使E最小。
该过程自然就涉及到最优、局部极小和全局最小的求解问题。
局部极小:在某个指定邻域范围内,存在任意E(w,θ)>E(w*,θ*),则称w* 和θ*是局部极小值。
全局最小:在整个样本空间中,最小误差E对应的w和θ值。
显然如果样本空间中,梯度为零,只要其误差函数值小于所有相邻点的值,那么其对应的w和θ必然为局部最小点。因此可能存在多个局部最小点,但全局最小点却唯一。
梯度下降法:利用负梯度方向下降速度最快的特点,对整个函数空间进行搜索求最优解。当剃度为零时,则找到一个局部最优点,根据该局部最优点是否唯一,确定其是否为全局最小。
为了避免求得多个局部极小点,从而导致陷入局部极小而无法找到全局最小点的问题,在现实任务中, 通常采用以下策略“跳出”局部极小, 从而进一步达到全局最小采用如下的启发式策略来应对:
1、采用多组参数值同时初始化神经网络(等于在开局的时候选择不同的参数值来进行模型训练,等于在同一个区域内沿不同方向进行搜索,最终都能找到各自方向上的最优点)
2、模拟退火技术。所谓的退火机制,就是指每一步允许出现比当前解更差的结果,接受次优解从而保证算法的稳定。(类似于悔棋,每次将处理步骤退回至前一步,然后沿另一个方向重新搜索)
3、使用随机梯度下降。即便到达局部极小点,其也可能因为计算的参数设定、步长等因素,让深陷极小点的函数继续计算,从而从极小点中”爬“出来。
4、遗传算法 [Goldberg, 1989]. 遗传算法也常用来训练神经网络以更好地逼近全局极小.
5.5 其他常见的神经网络
RBF(Radial Basis Function径向基函数) 网络是一种单隐层前馈神经网络, 它使用径向基函数作为隐层神经元激活函数, 而输出层则是隐层神经元输出的线性组合。值得注意的是具有足够多隐层神经元RBF 神经网络能以任意精度逼近任意连续函数.
模型简述:

训练步骤:Step1:确定神经元中心,常用的方式包括随机采样、聚类等 Step2:利用BP算法等确定参数
ART(Adaptive Resonance Theory,自适应谐振理论)网络是神经网络中一种常用的无监督学习策略。在使用该策略时, 网络的输出神经元相互竞争, 每一时刻仅有一个神经元被激活, 其他神经元的状态被抑制。总结一下特性:

ART 网络性能依赖于识别阈值 识别阈值高时, 输入样本将会分成比较多、得到较精细分类 识别阈值低时, 输入样本将会分成比较少、产生较粗略分类.其优势为:ART较好的解决了竞争学习中的“可塑性-稳定性窘境”, 可塑性是指神经网络要有学习新知识的能力;稳定性是指神经网络在学习新知识时要保持对旧知识的记忆. ART 网络可以增量学习或在线学习
SOM(Self-Organization Map,自组织映射)网络是一种竞争型的无监督神经网络, 它能将高维数据映射到低维空间(通常为2维), 同时保持输入数据在高维空间的拓扑结构, 即将高维空间中相似的样本点映射到网络输出层中邻近神经元. 如下图,SOM 网络中的输出层神经元以矩阵方式排列在二维空间中, 每个神经元都拥有一个权值向量, 网络在接收输入向量后, 将会确定输出层获胜神经元, 它决定了该输入向量在低维空间中的位置.
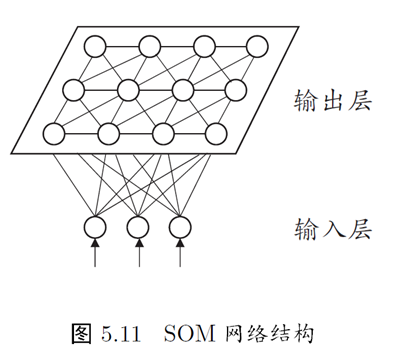
SOM 网络训练 :
- Step1:接受到一个训练样本后, 每个输出层神经元计算该样本与自身携带的权向量之间的距离, 距离最近的神经元成为竞争获胜者
- Step2:最佳匹配单元及其近邻神经元的权值将被调整, 使得这些权向量与当前输入样本的距离缩小
级联相关网络

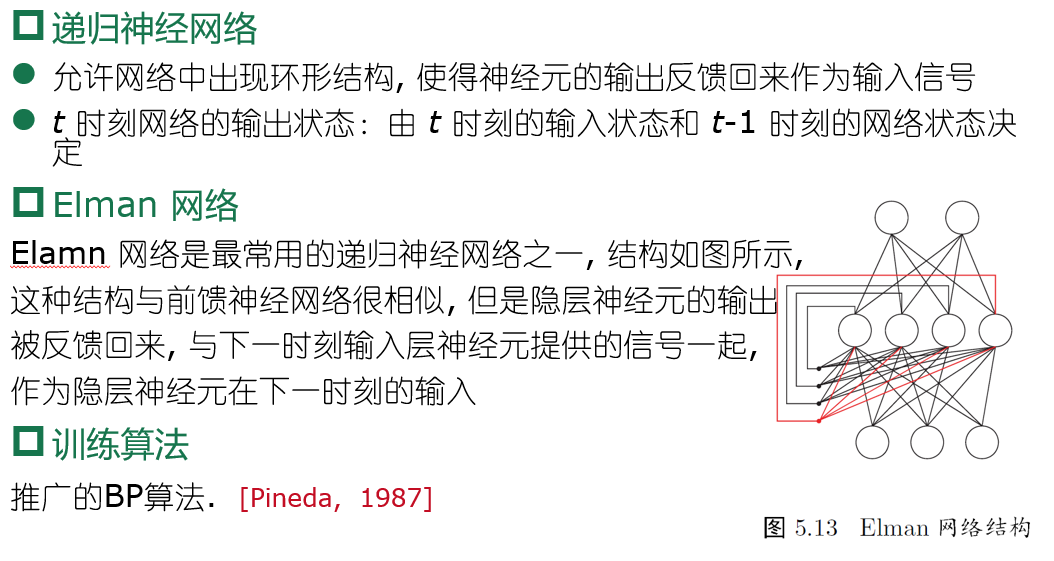
Elman(recursive neural networks)递归神经网络
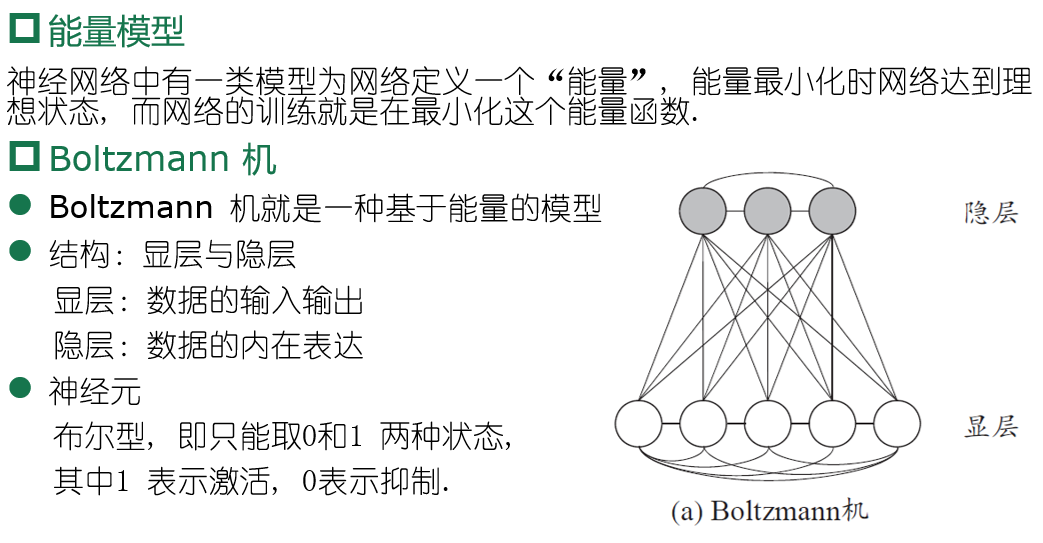
Bolzmann机

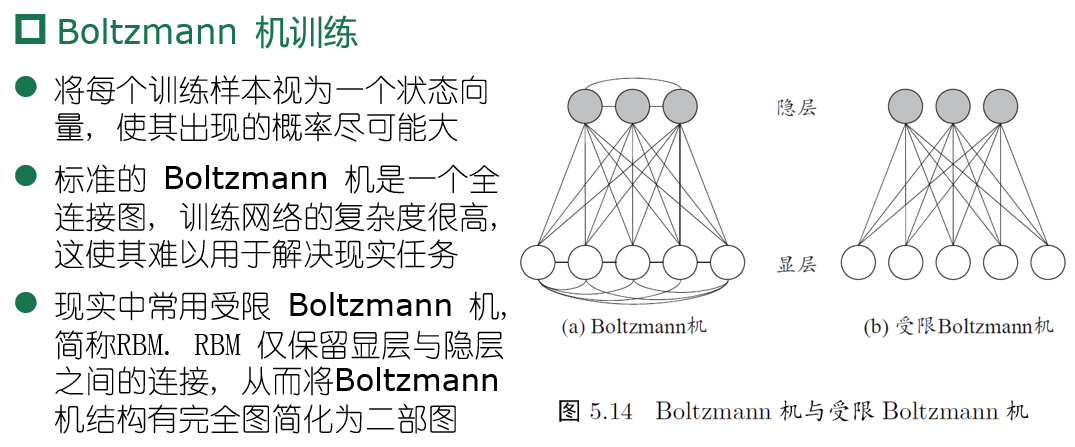
受限的 Bolzmann机

5.6 深度学习
典型的深度学习模型就是很深层的神经网络.
模型的复杂度方面总结为:
- 增加隐层神经元的数目 (模型宽度)
- 增加隐层数目(模型深度)
- 从增加模型复杂度的角度看, 增加隐层的数目比增加隐层神经元的数目更有效. 这是因为增加隐层数不仅增加额拥有激活函数的神经元数目, 还增加了激活函数嵌套的层数.
- 多隐层网络难以直接用经典算法(例如标准BP算法)进行训练, 因为误差在多隐层内逆传播时, 往往会”发散”而不能收敛到稳定状态.
复杂模型训练方法



卷积神经网络简述:




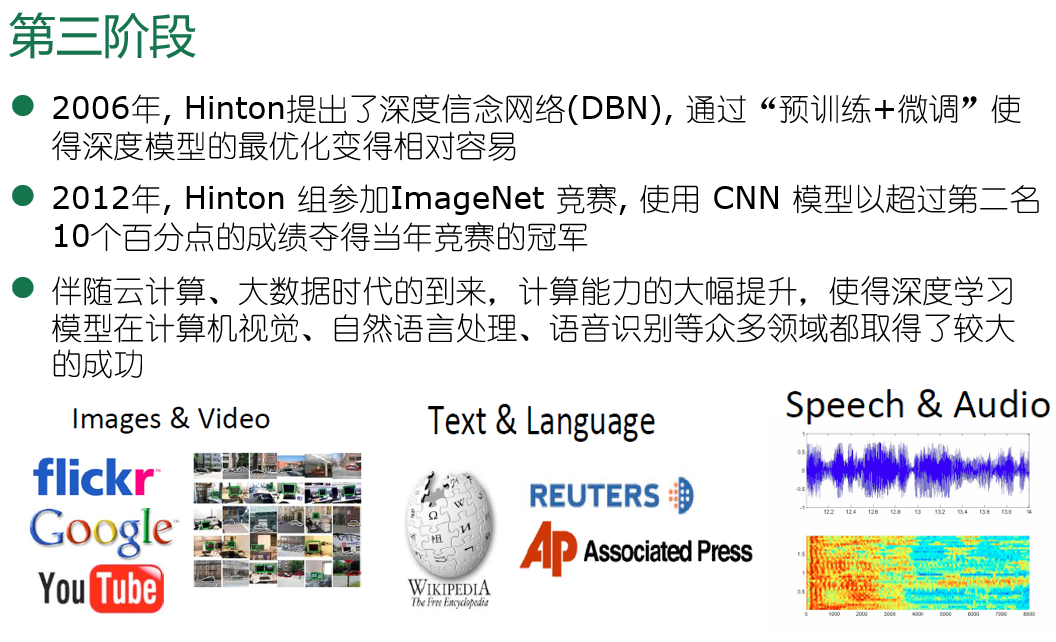
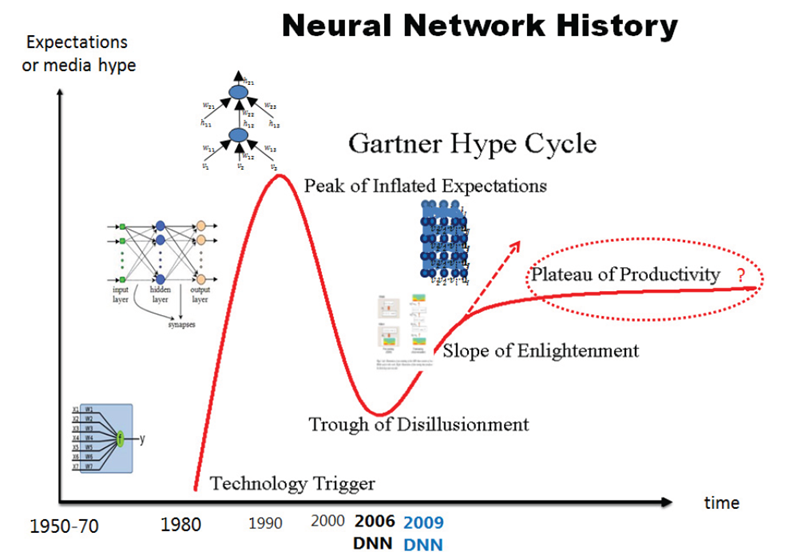
结束语--神经网络发展史