最近在做sparkstreaming整合kafka的时候遇到了一个问题:
可以抽象成这样一个问题:有状态的wordCount,且按照word的第一个字母为key,但是要求输出的格式为(word,1)这样的形式
举例来说:
例如第一批数据为: hello how when hello
则要求输出为:(hello,1) (how,2) (when,1) (hello,3)
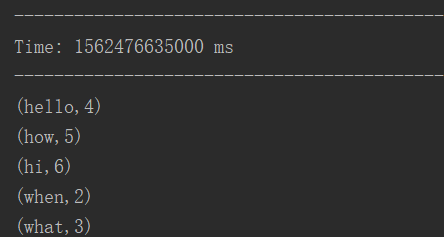
第二批数据为: hello how when what hi
则要求输出为: (hello,4) (how,5) (when,2) (what,3) (hi,6)
首先了解一下mapWithState的常规用法:
ref: https://www.jianshu.com/p/a54b142067e5
http://sharkdtu.com/posts/spark-streaming-state.html
稍微总结一下mapWithState的几个tips:
- mapWithState是1.6版本之后推出的
- 必须设置checkpoint来储存历史数据
- mapWithState和updateStateByKey的区别 : 他们类似,都是有状态DStream操作, 区别在于,updateStateByKey是输出增量数据,随着时间的增加, 输出的数据越来越多,这样会影响计算的效率, 对CPU和内存压力较大.而mapWithState则输出本批次数据,但是也含有状态更新.
- checkpoint的数据会分散存储在不同的分区中, 在进行状态更新时, 首先会对当前 key 做 hash , 再到对应的分区中去更新状态 , 这种方式大大提高了效率.
解决问题的思路:
State中保存状态为(String,Int) 元组类型, 其中String为word的全量, 而Int为word的计数.
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.MapWithStateDStream
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
object MapWithStateApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MapWithStateApp")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("C:\Users\hylz\Desktop\checkpoint")
val lines = ssc.socketTextStream("192.168.100.11",8888)
val words = lines.flatMap(_.split(" "))
def mappingFunc(key: String, value: Option[(String, Int)], state: State[(String, Int)]): (String, Int) = {
val cnt: Int = value.getOrElse((null, 0))._2 + state.getOption.getOrElse((null, 0))._2
val allField: String = value.getOrElse((null, 0))._1
state.update((allField, cnt))
(allField, cnt)
}
val cnt: MapWithStateDStream[String, (String, Int), (String, Int), (String, Int)] = words.map(x => (x.substring(0, 1), (x, 1))).mapWithState(StateSpec.function(mappingFunc _))
cnt.print()
ssc.start()
ssc.awaitTermination()
}
}
测试结果如下

input: hello how when hello

input: hello how when what hi