Solr 是基于lucene的检索服务器。能够很快的搭建检索服务,并且提供的很多实用的组件。例如高亮(highlight)、拼写检查(spellCheck)和匹配相位(moreLikeThis)。下面我将在我工作中接触到的一些实践与大家分享。(我当前使用的solr 版本是 3.4,使用tomcat 7.0.21)
(如果你也使用的是 tomcat 服务器,而且查询请求包含中文的话,还需要修改 TOMCAT_HOME/conf/server.xml 的 <Connector ... URIEncoding="UTF-8"/> 使用 UTF-8 编码,详见 URI_Charset_Config 和 http)
高亮(highlight)
我们经常使用搜索引擎,比如在google 搜索 java ,会出现如下结果,结果中与关键字匹配的地方是红色显示与其他内容区别开来。 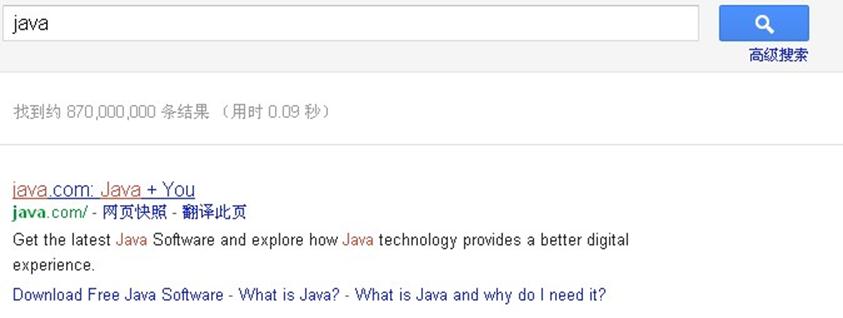
solr 默认已经配置了highlight 组件(详见 SOLR_HOME/conf/sorlconfig.xml)。通常我出只需要这样请求http://localhost:8080/solr/select?q=name:王麻子&start=0&rows=10&hl=true&hl.fl=name ,可以看到与比一般的请求多了两个参数 "hl=true" 和 "hl.fl=name" 。"hl=true" 则是开启高亮,"hl.fl=name" 则告诉solr 对 name 字段进行高亮(如果你想对多个字段进行高亮,可以继续添加字段,字段间用逗号隔开,如 "hl.fl=name,name2,name3")。
查询结果如下:
Xml代码
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">15</int>
<lst name="params">
<str name="hl">true</str>
<str name="hl.fl">name</str>
<str name="q">name:王麻子</str>
<str name="start">0</str>
<str name="rows">10</str>
</lst>
</lst>
<!--此处是一般的返回结果-->
<result name="response" numFound="1" start="0">
<doc>
<str name="id">4</str>
<str name="name">王麻子勤劳朴实</str>
</doc>
</result>
<!--此处是高亮的返回结果-->
<lst name="highlighting">
<!--id=4-->
<lst name="4">
<!--字段name 的高亮内容-->
<arr name="name">
<!--下面是经过xml转义,其实内容是 "<em>王麻子</em>勤劳朴实"-->
<str><em>王麻子</em>勤劳朴实</str>
</arr>
</lst>
</lst>
</response>
高亮内容与关键匹配的地方,默认将会被 "<em>" 和 "</em>" 包围。如果用户想自定义高亮地方的前后标签,可以在请求中再加两个参数 "hl.simple.pre" 和 "hl.simple.post" 来分别指定前后标签,如 http://localhost:8080/solr/select?q=name:王麻子&start=0&rows=10&hl=true&hl.fl=name&hl.simple.pre=<b>&hl.simple.post=</b>。或者修改 solrconfig.xml 配置文件中的 highligh searchComponent 来实现。
(highlight 更多请求参数可以参考HighlightingParameters)
拼写检查(spellCheck)
首页配置 solrconfig.xml,文件可能已经有这两个元素(如果没有添加即可),需要根据我们自己的系统环境做些适当的修改。
Xml代码
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="name">default</str>
<!--这里指明需要根据哪个字段的索引为依据进行拼写检查。现配置 名为 name 的字段-->
<str name="field">name</str>
<!--拼写检查索引的目录-->
<str name="spellcheckIndexDir">spellchecker</str>
<!--当commit的时候,对拼写检查索引进行构建。(只有构建后,拼写检查才有效果)-->
<!--当然,也可以选择在optimize的时候,进行构建。那么只需要将"buildOnCommint"换为 "buildOnOptimize"-->
<str name="buildOnCommit">true</str>
</lst>
</searchComponent>
<requestHandler name="/spell" class="solr.SearchHandler" startup="lazy">
<!--默认参数-->
<lst name="defaults">
<str name="spellcheck.onlyMorePopular">false</str>
<str name="spellcheck.extendedResults">false</str>
<!--配置拼写检查提示结果的个数(可以根据需要适当加大)-->
<str name="spellcheck.count">1</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
配置完之后,需要重新建遍索引才能失效。然后我们这以请求 http://localhost:8080/solr/spell?q=name:王麻字&spellcheck=true
查询如果如下:
Xml代码
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response" numFound="0" start="0"/>
<lst name="spellcheck">
<lst name="suggestions">
<lst name="王麻字">
<int name="numFound">1</int>
<int name="startOffset">0</int>
<int name="endOffset">3</int>
<arr name="suggestion">
<str>王麻子</str>
</arr>
</lst>
</lst>
</lst>
</response>
有时候我们需要以多个字段为依据进行拼写检查,但上面的配置只能设一个字段。为了达到同样的效果,我能只能另行其道了。需要用到 coptyField 技术。比如我们在 schema.xml 中定义了
Xml代码
<field name="a" .../>
<field name="b" .../>
想对字段 a 和 b 同时为依据进行拼写检查,我们可能再加一个 field
Xml代码
<field name="ab" multiValued="true" .../>
然后再加两个 copyField
Xml代码
<copyField source="a" dest="ab"/>
<copyField source="b" dest="ab"/>
完整的配置如下:
Xml代码
<field name="a" .../>
<field name="b" .../>
<field name="ab" multiValued="true" .../>
<copyField source="a" dest="ab"/>
<copyField source="b" dest="ab"/>
(更详细的内容可以参考 SpellCheckComponent)
匹配相似(moreLikeThis)
他的作用是查找相似的document。
首先在 solrconfig.xml 中配置 MoreLikeThisHandler
Xml代码
<requestHandler name="/mlt" class="solr.MoreLikeThisHandler">
</requestHandler>
然后我就可以请求 http://localhost:8080/solr/mlt?q=id:7&mlt.true&mlt.fl=name&mlt.mintf=1&mlt.mindf=1
上面请求的意思查找 id 为 7 的 document ,然后返回与此 document 在 name 字段上相似的其他 document。需要注意的是 mlt.fl 中的 field 的 termVector=true 才有效果
Xml代码
<field name="name" termVector="true" .../>
当然 mlt.fl 也可以添加多个field ,用逗号隔开就行了
(详细说明可参考 MoreLikeThis MoreLikeThisHandler)