流
比如有一份菜单,我们需要从菜单中挑选热量低于400的菜组成健康菜单,在sql语句中是这样实现的select name from dishes where calorie < 400
在java8之前的版本,我们可能会这么做,便利菜单,一道菜一道菜去筛选,刷选完之后再新建一个列表保存筛选过后菜的名字。这样做很繁琐,我们也想像SQL一样,只需要表达你想要什么就能达到目的。
这就是流能办到的。
1.引入流
1.流的简介
流是java api的新成员,它允许你能以声明式的方式处理数据集合(通过查询语句来表达,而不是临时写一个实现)。流还可以透明的进行并行处理。
需求:从菜单中挑选热量低于400的菜组成健康菜单,健康菜单按照calories排序
java8之前的做法:
public void getLowCaloriesByJava7(List<Dish> dishList){
ArrayList<Dish> lowCaloriesDishes = new ArrayList<>();
//迭代排序
for (Dish dish : dishList) {
if (dish.getCalories() < 400){
lowCaloriesDishes.add(dish);
}
}
//使用匿名内部类排序
Collections.sort(lowCaloriesDishes, new Comparator<Dish>() {
@Override
public int compare(Dish o1, Dish o2) {
return new Integer(o1.getCalories()).compareTo(o2.getCalories());
}
});
//转成另一个集合
ArrayList<String> healthyMenu = new ArrayList<>();
for (Dish lowCaloriesDish : lowCaloriesDishes) {
healthyMenu.add(lowCaloriesDish.getName());
}
printMenu(healthyMenu);
}
上面的变量lowCaloriesDishes只用过一次,只作为中介,是个“垃圾变量”
java8版本
private void getLowCaloriesByJava8(List<Dish> menu) {
List<String> healthMenu = menu.stream()
.filter((dish) -> dish.getCalories() < 400)
.sorted(Comparator.comparingInt(Dish::getCalories))
.map(Dish::getName)
.collect(Collectors.toList());
printMenu(healthMenu);
}
这样声明式代码,更容易懂且更加简洁和容易维护升级。
2. 流和集合
流和集合最大的不同就是:集合的元素都保存在内存中,集合中的每个元素都得先算出来才能添加到集合中。
流则是固定的数据结构(不能删除和添加元素???)元素是按需求计算的。
java8中的集合就好比DVD上存在的电影,所有元素都准备好了。而流就好比在线流媒体看的电影,每次只会缓存一些元素。
2.1 流只能消费一次。
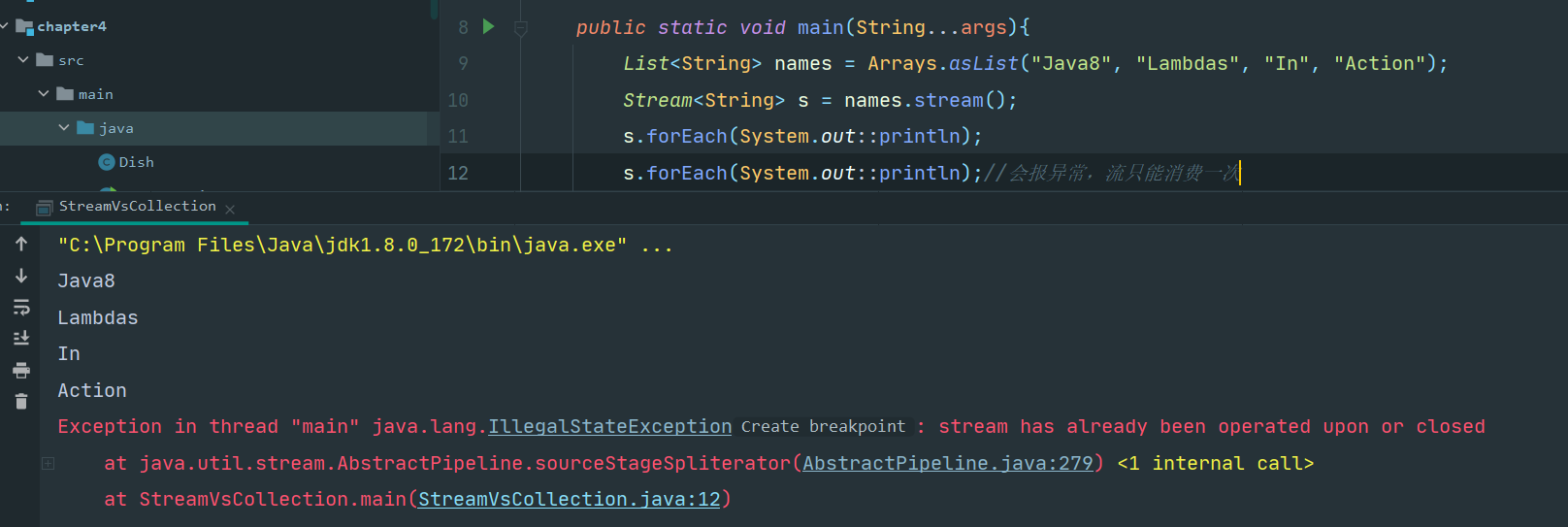
哲学中的流和集合
对于喜欢哲学的读者,你可以把流看作在时间中分布的一组值。相反,集合则是空间(这里就是计算机内存)中分布的一组值,在一个时间点上全体存在--你可以使用选代器来访问for-each循环中的内部成员
2.2 内部迭代
流是使用内部迭代,这就意味着Stream可以自动选择一种合适的并行方式,可以跟优化的进行处理。
外部迭代就只能自己去实现并行处理了。
3. 流操作
3.1 中间操作
private void getThreeHighCalories(List<Dish> menu){
List<String> healthMenu = menu.stream()
.filter((dish) -> {
System.out.println("filter -> " + dish.getName());
return dish.getCalories() > 300;
})
.limit(3)
.map((dish -> {
System.out.println("map -> "+dish.getName());
return dish.getName();
}))
.collect(Collectors.toList());
System.out.println(healthMenu);
}
流的操作可以分为两个部分。一个是中间操作,中间操作都会返回一个流对象。 如:filter limit map都是中间操作。一个是终端操作。如 collect
中间操作连接起来就形成了一种流水线,而终端操作是触发流水线产生结果的并关闭流水线。
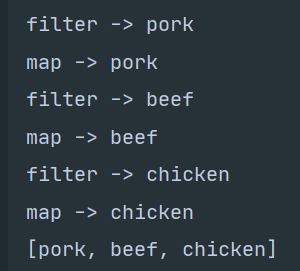
测试结果:
note :
诸如filter或 sorted等中间操作会返回另一个流。这让多个操作可以连接起来形成一个査询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理它们很懒这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。而且你会发现,有好几种优化利用了流的延退性质。第一,尽管很多菜的热量都高于300卡路里, 但只选出了前三个!这是因为limit操作和一种称为短路的技巧,我们会在下一章中解释。第尽管fi1ter和map是两个独立的操作,但它们合并到同一次遍历中了(我们把这种技术叫作循环合并)。
3.2 终端操作
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如ist、 Integer,甚至void。
3.3 使用流
使用流的三个步骤:
- 数据源(如 集合)来执行一个查询
- 一条中间操作链 来形成一条流水线
- 一个终端操作来执行流水线,得到结果
2. 使用流
2.1 筛选和切片
-
使用谓词筛选
filterList<Dish> vegetarianMenu = Dish.menu.stream() .filter(Dish::isVegetarian) .collect(toList()); -
筛选各异元素
distinctList<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4); numbers.stream() .filter(i -> i % 2 == 0) .distinct() .forEach(System.out::println); -
截短流
limitList<Dish> dishesLimit3 = Dish.menu.stream() .filter(d -> d.getCalories() > 300) .limit(3) .collect(toList()); -
跳过元素
skipList<Dish> dishesSkip2 = Dish.menu.stream() .filter(d -> d.getCalories() > 300) .skip(2) .collect(toList());
2.2 映射
2.2.1 对流中每一个元素应用函数
流支持map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素
List<String> dishNames = menu.stream()
.map(Dish::getName)
.collect(toList());
System.out.println(dishNames);
2.2.2 流的扁平化
给定一张单词列表。怎么获取这张单词列表出现的所有不同字母。
初始想法:
List<String> words = Arrays.asList("Hello", "World");
List<String[]> collect = words.stream()
//把每个单词映射成了字符串数组 String -> String[] 如 "word" -> {"w","o","r","d"}
.map(word -> word.split(""))
//两个数组之间自然是不同的
.distinct()
//收集起来后自然是一个List<String[]>
.collect(Collectors.toList());
所以问题没有得到解决,问题就出在映射上面,它把每个单词映射成了数组流,而我们需要字符流
Arrays.stream()方法可以接受一个数组返回一个流
第二个版本
List<Stream<String>> collect = words.stream()
//把每个单词映射成了字符串数组 String -> String[] 如 "word" -> {"w","o","r","d"}
.map(word -> word.split(""))
//把每一个数组变成单独的流 string[] -> stream<String> => string[],string[],string[] -> stream<stream<String>>
.map(Arrays::stream)
//两个数组之间自然是不同的
.distinct()
//收集起来后自然是一个List<String[]>
.collect(Collectors.toList());
那么使用Arrays.stream()映射之后还是没有得到想要的结果,原因是因为 map(Arrays::stream)把数组变成了一个单独的流,拿两个流之间自然也是不同的。
解决办法就是使用 flatMap(Arrays::stream)将流扁平化,将map(Arrays::stream)生成的独立流合并在一起,形成一条流。
第三个版本
List<String> collect = words.stream()
//把每个单词映射成了字符串数组 String -> String[] 如 "word" -> {"w","o","r","d"}
.map(word -> word.split(""))
//将流扁平化 string[] -> stream<String> => string[],string[],string[] -> stream<String>
.flatMap(Arrays::stream)
//两个数组之间自然是不同的
.distinct()
//收集起来后自然是一个List<String[]>
.collect(Collectors.toList());
flatMap方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
练习:给定两个数字列表,如何返回所有的数对呢?例如,给定列表[1,2,3]和列表[3,4],应该返回[(1,3),(1,4),(2,3),(2,4),(3,3),(3,4)]。为 简单起见,你可以用有两个元素的数组来代表数对。
List<Integer> integers1 = Arrays.asList(1, 2, 3);
List<Integer> integers2 = Arrays.asList(3,4);
List<int[]> collect1 = integers1.stream()
.flatMap(i -> integers2.stream().map(j -> new int[]{i, j}))
.collect(Collectors.toList());
collect1.forEach(pair -> System.out.println("(" + pair[0] + ", " + pair[1] + ")"));
2.3 查找与匹配
2.3.1 匹配
-
anyMatch查找查找流中元素是否有和谓词匹配的List<Dish> dishes = Dish.menu; System.out.println( dishes.stream() .anyMatch(dish -> dish.getCalories() < 1000)); -
allMatch检查流中元素是否全和谓词匹配System.out.println( dishes.stream() .allMatch(dish -> dish.getCalories() < 800)); -
noneMatch和allMatch相反检查流中元素是否全都不符合谓词System.out.println( dishes.stream() .noneMatch(dish -> dish.getCalories() > 800));
这三种操作都是终端操作,且都是用到了短路技巧
2.3.2 查找
-
findAny在流中找一个符合谓词的元素dishes.stream() .filter(dish -> dish.getType().equals(Dish.Type.OTHER)) .findAny().ifPresent(dish -> System.out.println(dish.getName())); -
findFirst在流中找第一个出现符合谓词的元素dishes.stream() .filter(dish -> dish.getType().equals(Dish.Type.OTHER)) .findFirst().ifPresent(dish -> System.out.println(dish.getName()));
findAny 和findFirst 区别在于找第一个符合谓词的元素在并行上受限更多
2.4 归约
把一个流中的元素组合起来,使用 reduce操作来表达更复杂的查询,比如“计算菜单中的总卡路里”或“菜单中卡路里最高的菜是哪一个”。此类查询需要将流中所有元素反复结合起来,得到一个值,比如一个 Integer。这样的查询可以被归类为归约操作(将流归约成一个值)。用函数式编程语言的术语来说,这称为折叠(fold),因为你可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
2.4.1 元素求和
将一个数字列表的数相加
java8之前
List<Integer> numbers = Arrays.asList(3,4,5,1,2);
int result = 0;
for (Integer number : numbers) {
result += number;
}
求和:反复使用+号,把一个数字列表规约成一个数字,两个参数
- 初始值,这里是0
- 将列表中的所有元素结合在一起的操作,这里是 + 号
java8版本
Integer sum = numbers.stream()
.reduce(0, Integer::sum);
reduce有两个参数,一个是初始值,一个是BinaryOperator
public interface BiFunction<T, U, R> {
R apply(T t, U u);
}
reduce操作对流的求和步骤,0作为Lambada第一个参数,从流中取出 3 作为第二个参数,执行Lambada返回的数 作为第一个参数,再从流中取出第二个参数 4 执行Lambda以此类推得到结果。
reduce方法也有重载,不用初始值的
Optional<Integer> sum1 = numbers.stream()
.reduce(Integer::sum);
不用初始值,代表可能numbers没有数从而返回结果为null,所以使用Optional
2.4.2 求最大最小值
numbers.stream()
.reduce(Integer::min)
.ifPresent(System.out::println);
怎样用map和 reducer方法数一数流中有多少个菜呢?
Dish.menu.stream()
.map(dish -> 1)
.reduce(Integer::sum)
.ifPresent(System.out::println);
当然更好是这样使用
Dish.menu.stream().count()
2.5 有状态和无状态
流的操作可分为两大类:一种是无状态操作,一种是有状态操作
无状态操作: 从输入流得到一个元素,并将0或者1个结果给输出流 这些操作大多都是无状态的:他们没有内部状态,就是当前执行的Lambda不需要知道之前步骤的结果,比如 map filter就是无状态操作
有状态操作: 但是诸如 reduce sum max 都需要内部状态来累计结果。上面三种内部状态都很小不管流有多少元素要处理,内部状态都是有界的。但是也有 无界的,如 distinct sort 排序要求所有元素都放入缓冲区后オ能给输出流加入一个项目。要是流比较大或者无限大,就会产生问题,例如:把质数流倒序等
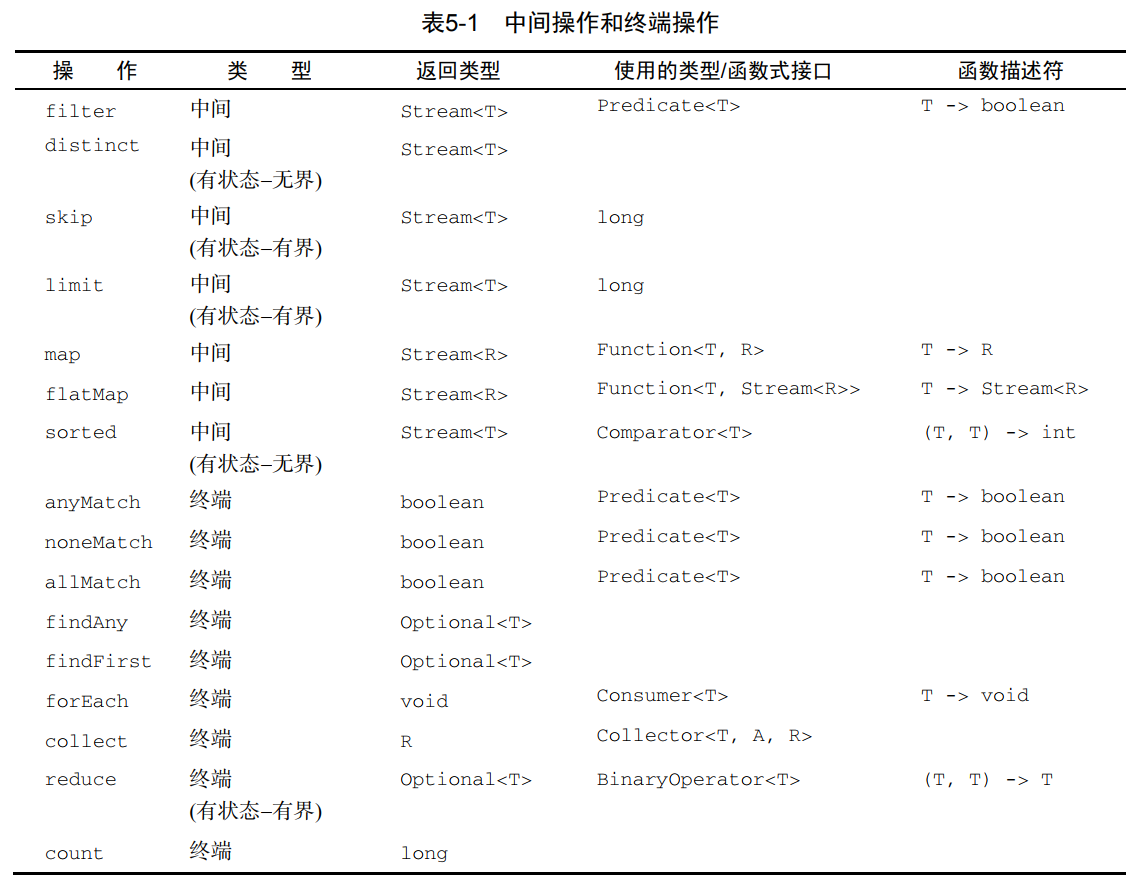
之前的中间操作和终端操作总结:
2.6 流的实践
(1)找出2011年发生的所有交易,并按交易额排序(从低到高)。
(2)交易员都在哪些不同的城市工作过?
(3)查找所有来自于剑桥的交易员,并按姓名排序
(4)返回所有交易员的姓名字符串,按字母顺序排序。
(5)有没有交易员是在米兰工作的?
(6)打印生活在剑桥的交易员的所有交易额
(7)所有交易中,最高的交易额是多少?
(8)找到交易额最小的交易
解答:
//(1)找出2011年发生的所有交易,并按交易额排序(从低到高)。
System.out.println("(1)找出2011年发生的所有交易,并按交易额排序(从低到高)。");
transactions.stream()
.filter(t->t.getYear() == 2011)
.sorted(Comparator.comparingInt(Transaction::getValue))
.forEach(System.out::println);
//(2)交易员都在哪些不同的城市工作过?
System.out.println("(2)交易员都在哪些不同的城市工作过?");
transactions.stream()
.map(t -> t.getTrader().getCity())
.distinct()
.forEach(System.out::println);
//(3)查找所有来自于剑桥的交易员,并按姓名排序
System.out.println("(3)查找所有来自于剑桥的交易员,并按姓名排序");
transactions.stream()
.map(Transaction::getTrader)
.filter(trader -> "Cambridge".equals(trader.getCity()))
.distinct()
.sorted(Comparator.comparing(Trader::getName))
.forEach(System.out::println);
//(4)返回所有交易员的姓名字符串,按字母顺序排序。
System.out.println("(4)返回所有交易员的姓名字符串,按字母顺序排序。");
System.out.println(transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted(String::compareTo)
//这样的拼接是效率低下的,因为每次都要创建一个新字符串
.reduce("", (n1, n2) -> n1 + n2));
System.out.println(transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted(String::compareTo)
//joining 使用了StringBuild对象进行字符串拼接
.collect(Collectors.joining()));
// (5)有没有交易员是在米兰工作的?
System.out.println("(5)有没有交易员是在米兰工作的?");
System.out.println(transactions.stream()
.anyMatch(t -> "Milan".equals(t.getTrader().getCity())));
//(6)打印生活在剑桥的交易员的所有交易额
System.out.println("(6)打印生活在剑桥的交易员的所有交易额");
transactions.stream()
.filter(transaction -> transaction.getTrader().getCity().equals("Cambridge"))
.map(Transaction::getValue)
.forEach(System.out::println);
//(7)所有交易中,最高的交易额是多少?
System.out.println("(7)所有交易中,最高的交易额是多少?");
System.out.println(transactions.stream()
.map(Transaction::getValue)
.reduce(0, Integer::max)
.toString());
//(8)找到交易额最小的交易
System.out.println("(8)找到交易额最小的交易");
transactions.stream()
.reduce((t1,t2)->Integer.max(t1.getValue(),t2.getValue()) > 0 ? t1:t2)
.ifPresent(System.out::println);
transactions.stream()
.min(Comparator.comparing(Transaction::getValue)).ifPresent(System.out::println);
2.7 数值流
1. 原始类型流特化
int sum = Dish.menu.stream()
.map(Dish::getCalories)
.reduce(0, Integer::sum);
上一段代码计算了菜单中卡路里的总数,但是map(Dish::getCalories)映射成的是一个Stream<Integer> 这涉及到了一个装箱成本。所以引入了原始类型流。
并且提供了 sum max min等终端操作
int sum1 = Dish.menu.stream()
.mapToInt(Dish::getCalories)
.sum();
mapToInt(Dish::getCalories)映射成的就是一个IntStream。这样节省了装箱的开销。
除了mapToInt 还有mapToDouble 和 mapToLong。
当然数值流也可以转为普通的流,使用boxed方法
Stream<Integer> boxed = Dish.menu.stream()
.mapToInt(Dish::getCalories)
.boxed();
默认值 OptionalXXX
前面的求和如果流为空,默认值是0,那么 max min 操作默认值就不能设置为0。所以返回值是OptionalInt同意也是Optional类的特化版本。
OptionalInt max = Dish.menu.stream()
.mapToInt(Dish::getCalories)
.max();
//如果没有最大值,则设置最大值为 0
int maxNum = max.orElse(0);
2. 数值范围
//IntStream.range(0, 100)返回[0,100)的IntStream,rangeClosed范围是[0,100]
//生成一个[0,100)数值范围所有偶数的数字列表
List<Integer> collect = IntStream.range(0, 100)
.filter(n -> n % 2 == 0)
.boxed()
.collect(Collectors.toList());
2.8 创建流
-
由值构建流
Stream<String> stream = Stream.of("Java 8", "Lambdas", "In", "Action"); -
由数组构建流
int[] numbers = {2, 3, 5, 7, 11, 13}; System.out.println(Arrays.stream(numbers).sum()); -
由文件生成流,这里使用的是java.nio下的类
// Files.lines 为文件生成一条流,文件中的每一行都是流中的元素 try (Stream<String> linesStream = Files.lines(Paths.get("D:\ForStrong_java\java8\chapter5\target\classes\data.text"))){ //这边使用flatMap和Arrays.stream把许多字符串数组偏平成一条字符流 linesStream.flatMap(line-> Arrays.stream(line.split(" "))) //找出文字出现的所有不同的单词 .distinct() .forEach(System.out::println); } catch (IOException e) { e.printStackTrace(); } -
无限流
-
迭代
//打印斐波那契数列的前十个数 Stream.iterate(new int[]{0, 1}, t -> new int[]{t[1],t[0] + t[1]}) .limit(10) . map(t -> t[0]) .forEach(System.out::println); -
生成
//生成5个0 - 1的随机数 Stream.generate(Math::random) .limit(5) .forEach(System.out::println);
-