主从节点的数据复制是Redis高可用和高负载的重要基础,本篇介绍数据的主从复制流程。
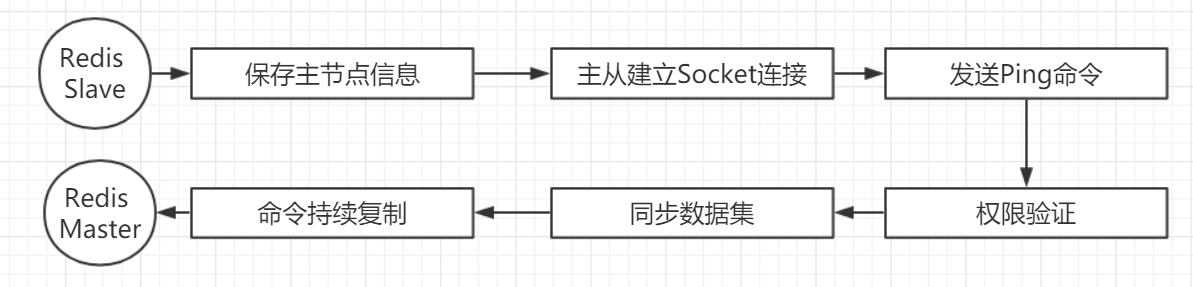
数据复制策略:
全量复制:一般用于初次复制场景,Redis早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
部分复制(2.8开始支持):用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点(补发数据从复制积压缓冲区获取)。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。
参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在info relication中的master_repl_offset指标中,如图:

从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量, 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在info relication中的slave_repl_offset指标中。
通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
复制积压缓冲区:
复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。
主接到操作请求立即返回,将命令写入复制积压缓冲区,异步将命令发送给从机。
当主从节点网络中断后,从节点再次连上主节点时会发送psync{offset}{runId}命令请求部分复制,如果请求的偏移量不在主节点的积压缓冲区内,则无法提供给从节点数据,因此部分复制会退化为全量复制。
下一篇会介绍Redis阻塞的原因分析