什么是requests模块
requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。


因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
手动处理url编码
手动处理post请求参数
处理cookie和代理操作繁琐
......
使用requests模块:
自动处理url编码
自动处理post请求参数
简化cookie和代理操作
......
如何使用requests模块
- 安装:
- pip install requests
- 使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
基于如下5点展开requests模块的练习
1.基于requests模块的get请求 2.基于requests模块的post请求 3.基于requests模块ajax的get请求 4.基于requests模块ajax的post请求 5.综合练习
案例演示代码演示:
1.基于requests模块的get请求,需求:
import requests #1.指定url headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' } url = 'https://www.sogou.com/' #2.发起请求:get返回一个响应对象 response = requests.get(url=url,verify=False,headers=headers) #3.获取响应数据:text属性返回的是字符串形式的响应数据 page_text = response.text print(page_text) #4.持久化存储 with open('./sogou.html','w',encoding='utf-8') as fp: fp.write(page_text) print('over!!!')
import requests wd = input('enter a word:') #url携带的参数需要手动处理 url = 'https://www.sogou.com/web' #将参数手动处理成了字典的形式 param = { 'query':wd } #使用params参数处理了请求携带的参数 response = requests.get(url=url,params=param) page_text = response.text fileName = wd+'.html' #文件名 #数据持久化 with open(fileName,'w',encoding='utf-8') as fp: fp.write(page_text) print(fileName,'爬取成功!')
2.基于requests模块的post请求:
import requests url = 'https://fanyi.baidu.com/sug' wd = input('enter something of English:') #这里输入英文翻译成中文 #url携带参数的封装 data = { 'kw':wd } #发起一个post请求 #UA检测这种反爬机制被应用在了大部分的网站中 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' } response = requests.post(url=url,data=data,headers=headers) #获取响应数据 #response.text #获取的是字符串形式的json数据 obj_json = response.json() #json()返回的就是对象类型的响应数据 print(obj_json)
如果是Content-Type:application/json,可以obj_json = response.json() #json()返回的就是对象类型的响应数据

3.基于requests模块ajax的git请求:
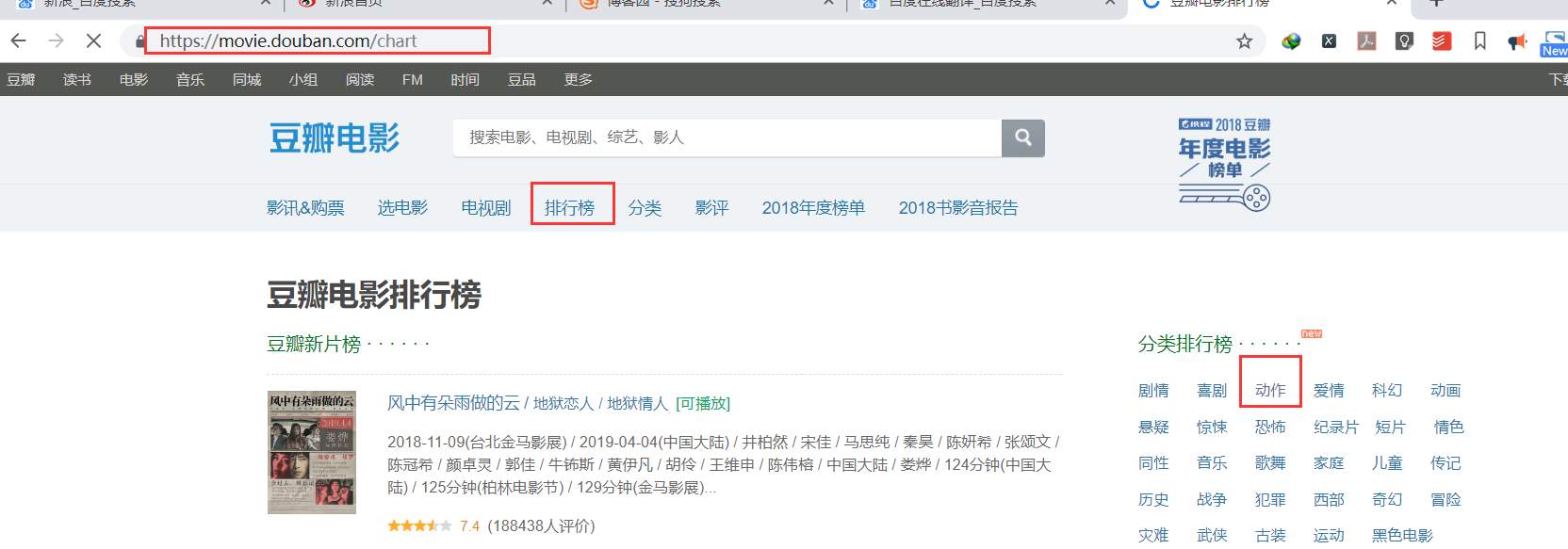
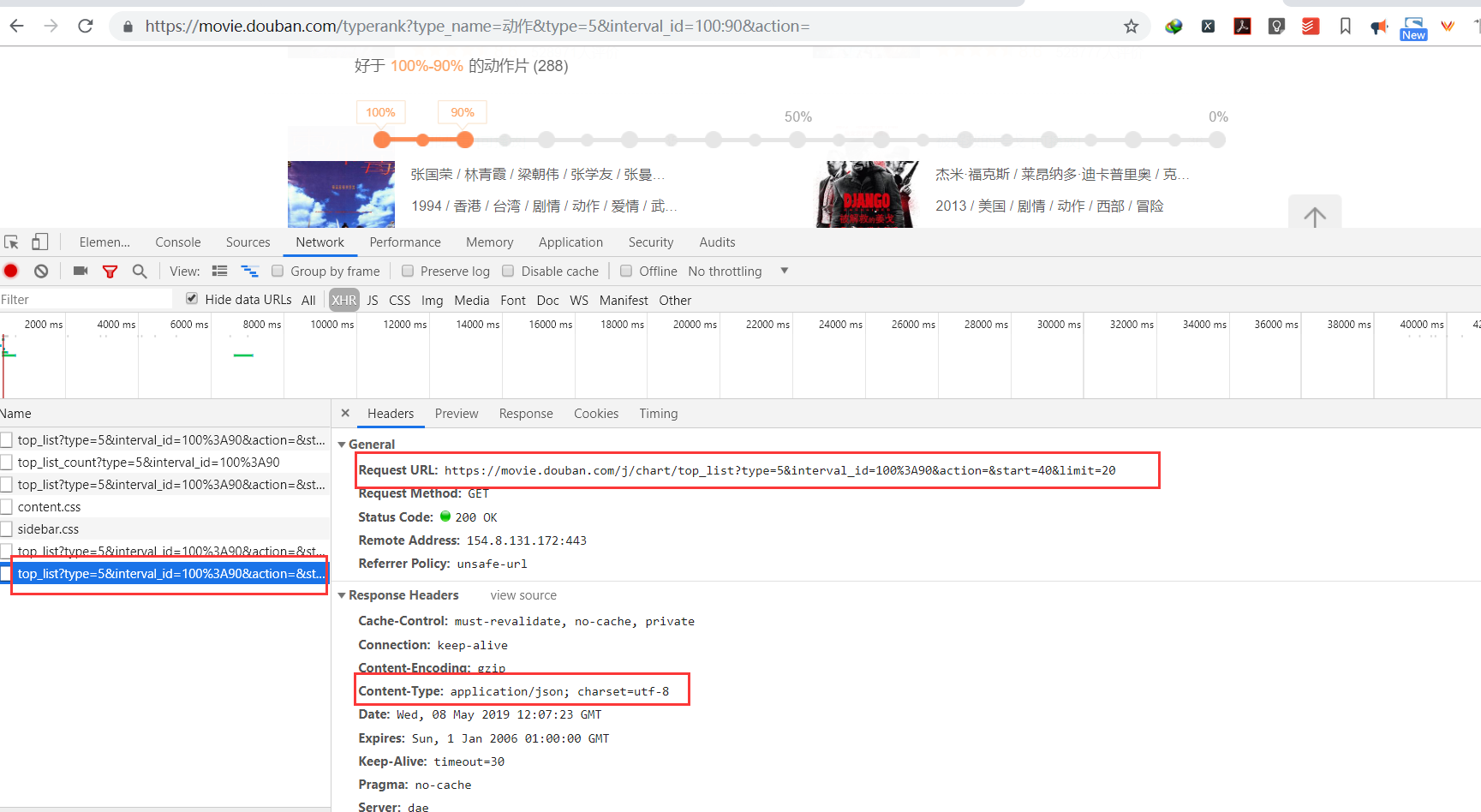
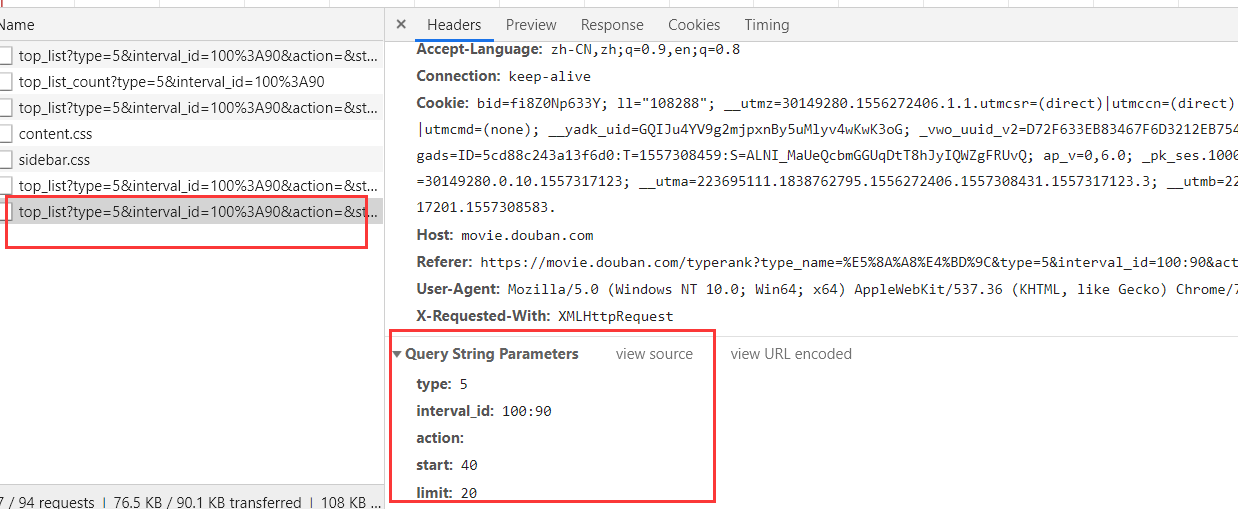
prsponse这里的数据在世我们拿到的数据信息

在线JSON校验格式化工具:http://www.bejson.com/

#!/usr/bin/env python # -*- coding:utf-8 -*- import requests import urllib.request if __name__ == "__main__": #指定ajax-get请求的url(通过抓包进行获取) url = 'https://movie.douban.com/j/chart/top_list?' #定制请求头信息,相关的头信息必须封装在字典结构中 headers = { #定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } #定制get请求携带的参数(从抓包工具中获取) param = { 'type':'5', 'interval_id':'100:90', 'action':'', 'start':'0', 'limit':'20' } #发起get请求,获取响应对象 response = requests.get(url=url,headers=headers,params=param) #获取响应内容:响应内容为json串 print(response.text) movie_list = response.json() print(movie_list) #y以json格式拿取列表里嵌套着字典,每个字典是一电影的详情 all_names = [] for dic in movie_list: print(dic) name = dic['title'] all_names.append(name) print(all_names) 需求:爬取豆瓣电影分类排行榜的电影名称
4.基于requests模块ajax的post请求:
ajax动态加载数据抓包查看方法
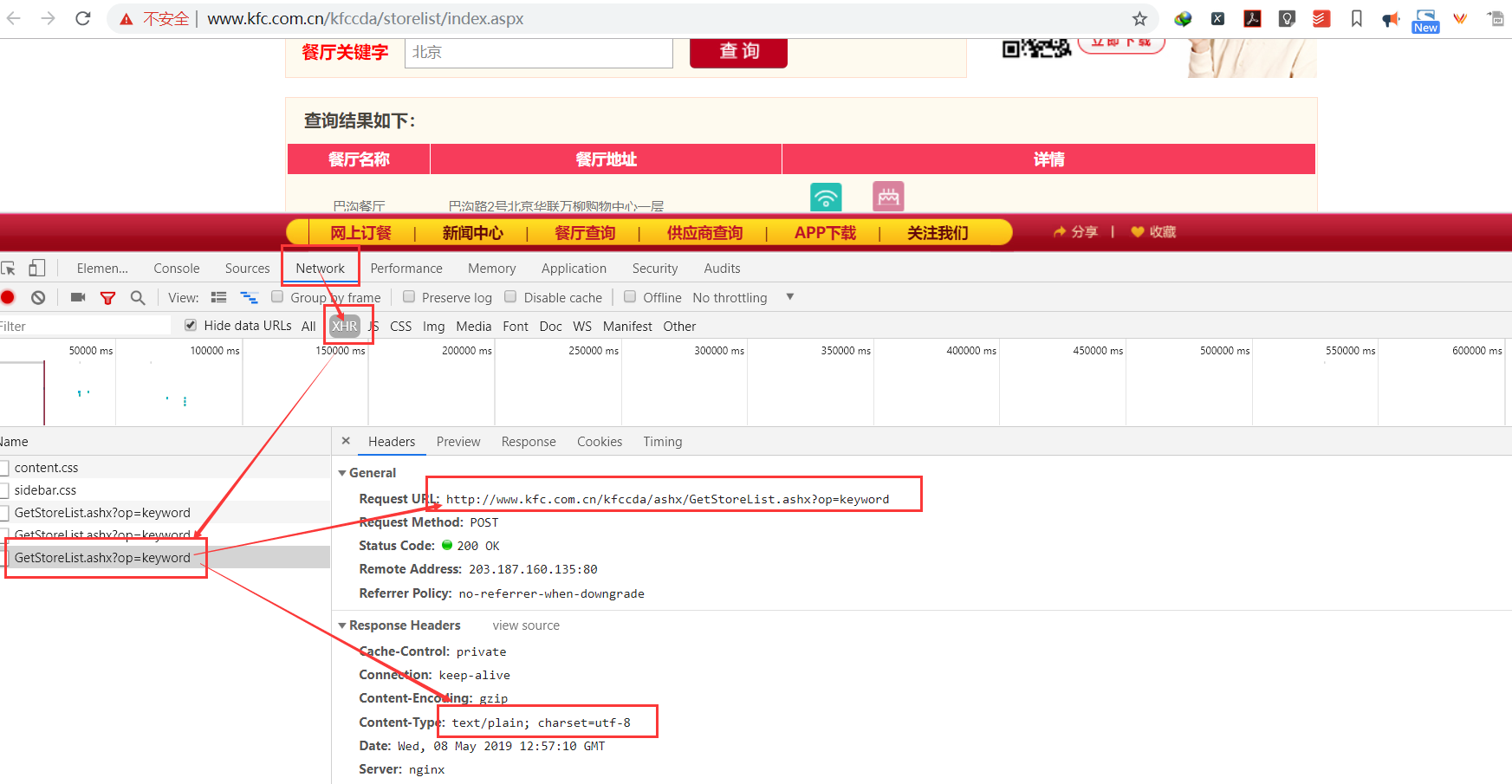

#!/usr/bin/env python # -*- coding:utf-8 -*- import requests import urllib.request if __name__ == "__main__": #指定ajax-post请求的url(通过抓包进行获取) url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' #定制请求头信息,相关的头信息必须封装在字典结构中 headers = { #定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } #定制post请求携带的参数(从抓包工具中获取) data = { 'cname':'', 'pid':'', 'keyword':'北京', 'pageIndex': '1', 'pageSize': '100' } #发起post请求,获取响应对象 response = requests.post(url=url,headers=headers,data=data) #获取响应内容:响应内容为json串 print(response.text)
5.综合练习:
这里引入一个fake_useragent第三方库,随机生成UserAgent请求头设置
安装 :pip3 install fake-useragent 查看安装的版本号:pip3 list 使用: from fake_useragent import UserAgent ua = UserAgent() # 禁用服务器缓存:ua = UserAgent(use_cache_server=False), 不缓存数据:ua = UserAgent(cache=False),忽略ssl验证:ua = UserAgent(verify_ssl=False) print(ua.ie) #随机打印ie浏览器任意版本 print(ua.firefox) #随机打印firefox浏览器任意版本 print(ua.chrome) #随机打印chrome浏览器任意版本 print(ua.random) #随机打印任意厂家的浏览器
需求: 爬取国家药品监督管理局企业许可相关信息:http://125.35.6.84:81/xk/ 问题描述: 获取分页数据,根据不同企业,在二级页面获取许可相关信息 知识点: 1.抓取数据包使用ajax的post请求 2.使用fake_useragent实现动态生成UA 3.该请求响应回来的数据有两个,可以根据content-type,来获取指定的响应数据: 一个是基于text 一个是基于json的
4.json在线格式化效验工具:http://www.bejson.com/
1.抓取ajax数据包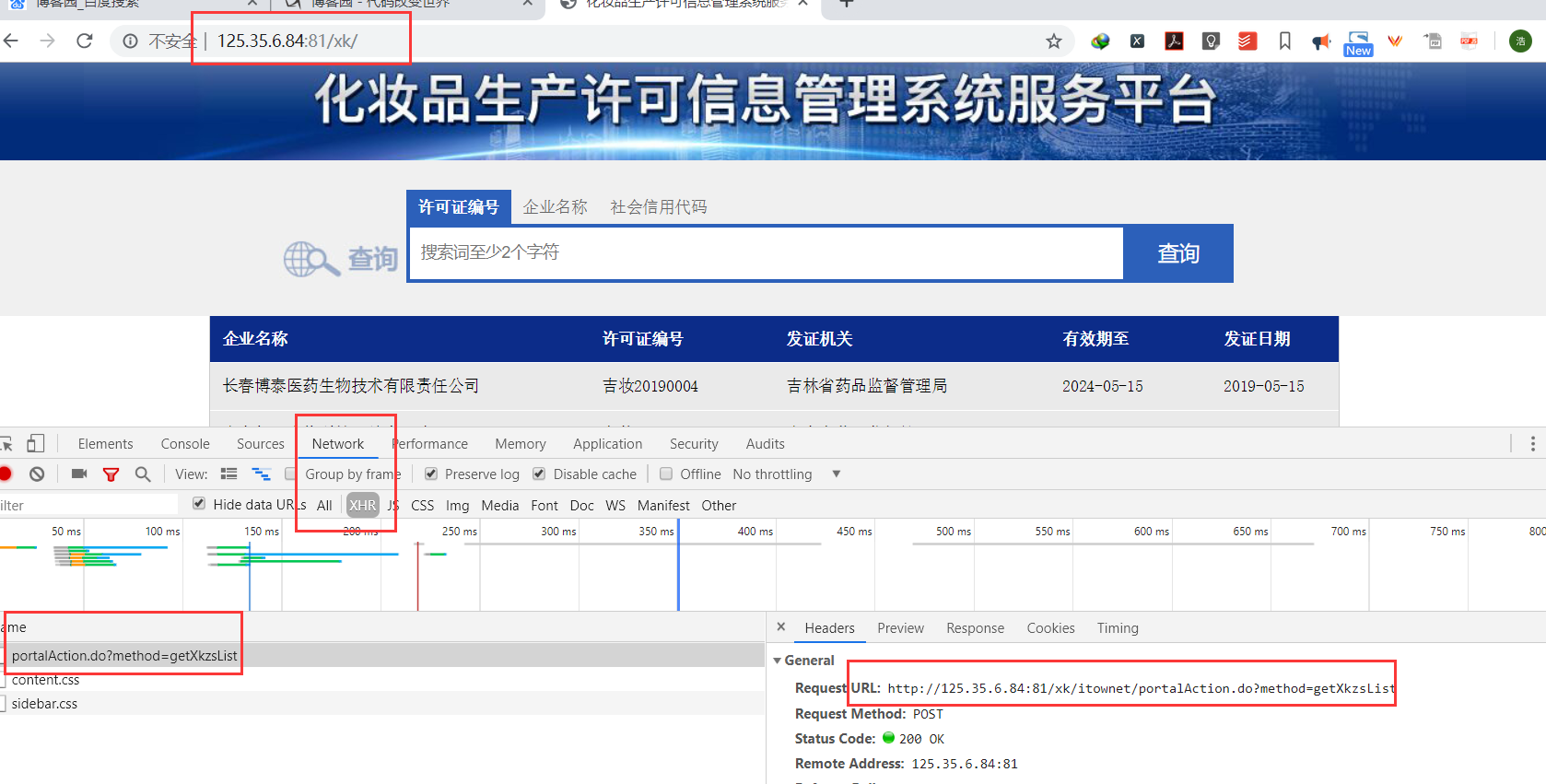
post提交的分页请求数据
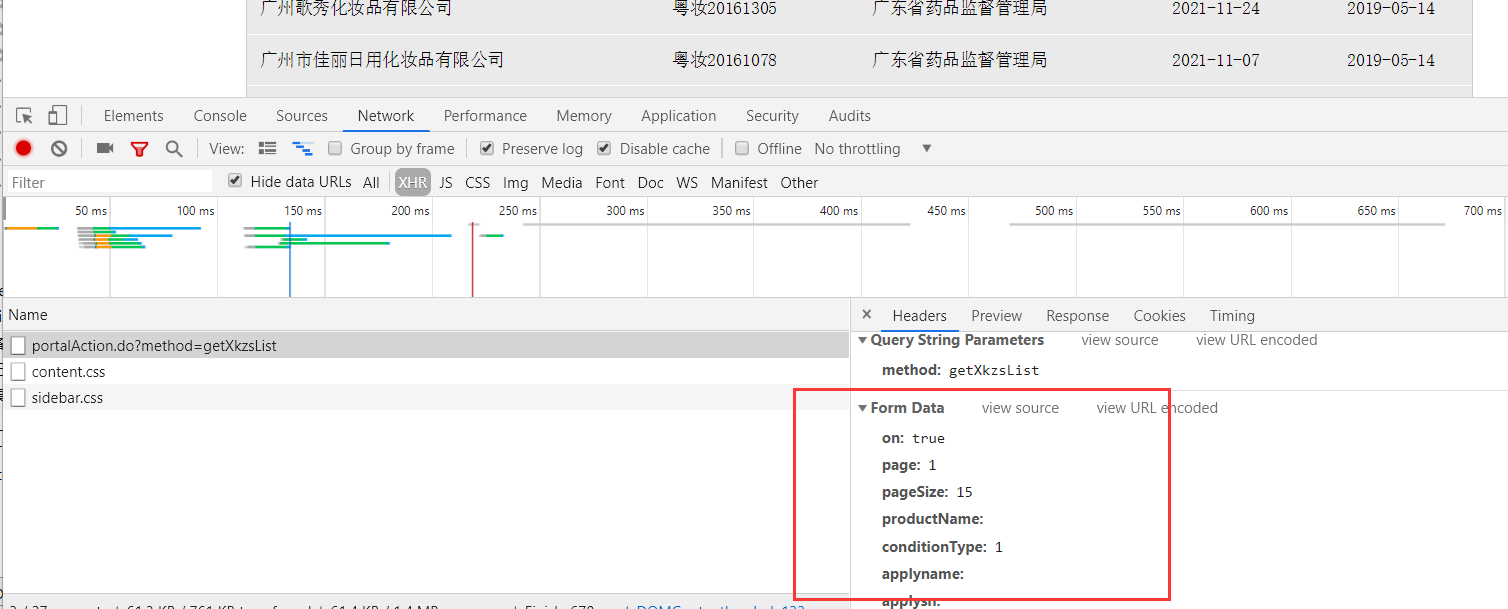
通过抓包工具获得首页li标签公司每条信息,从中提取二级页面跳转地址
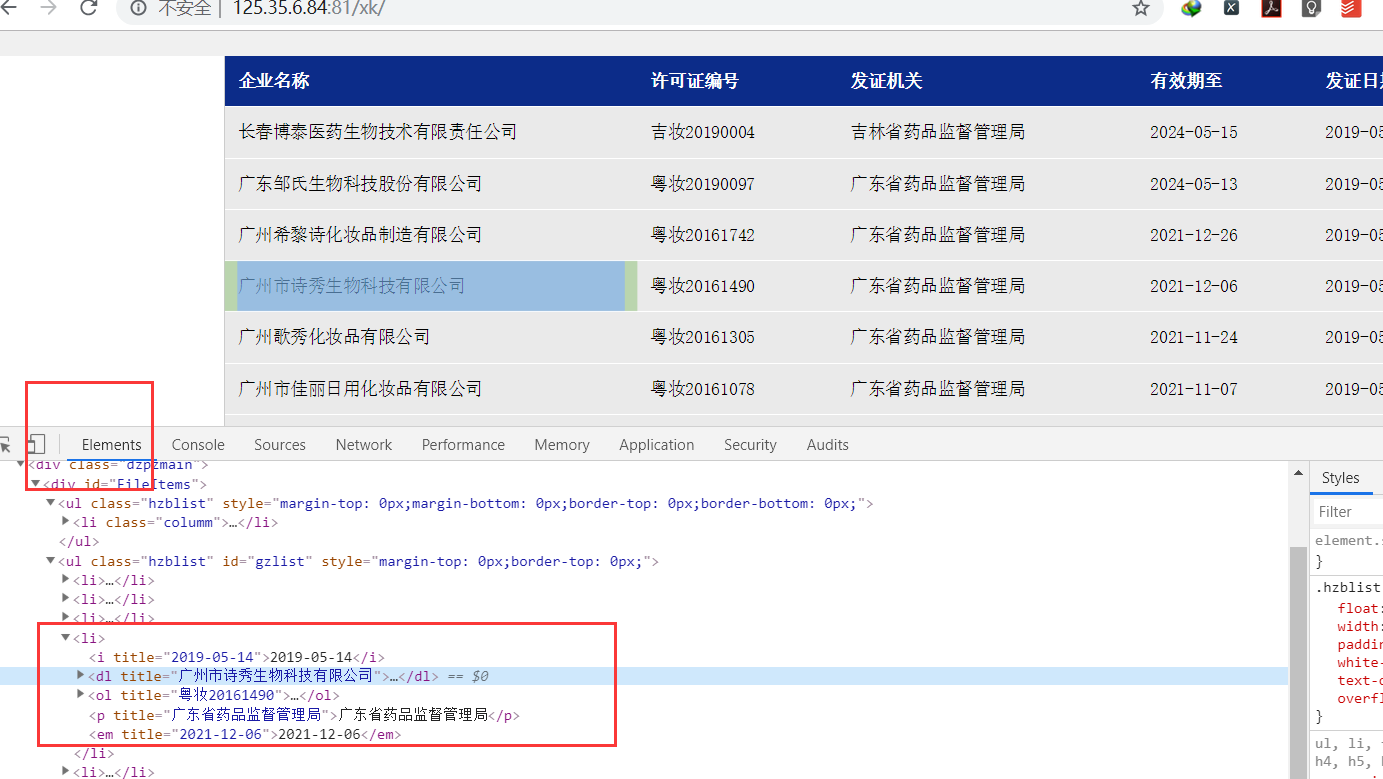
获取二级页面信息:

Response才是我们程序获取的数据
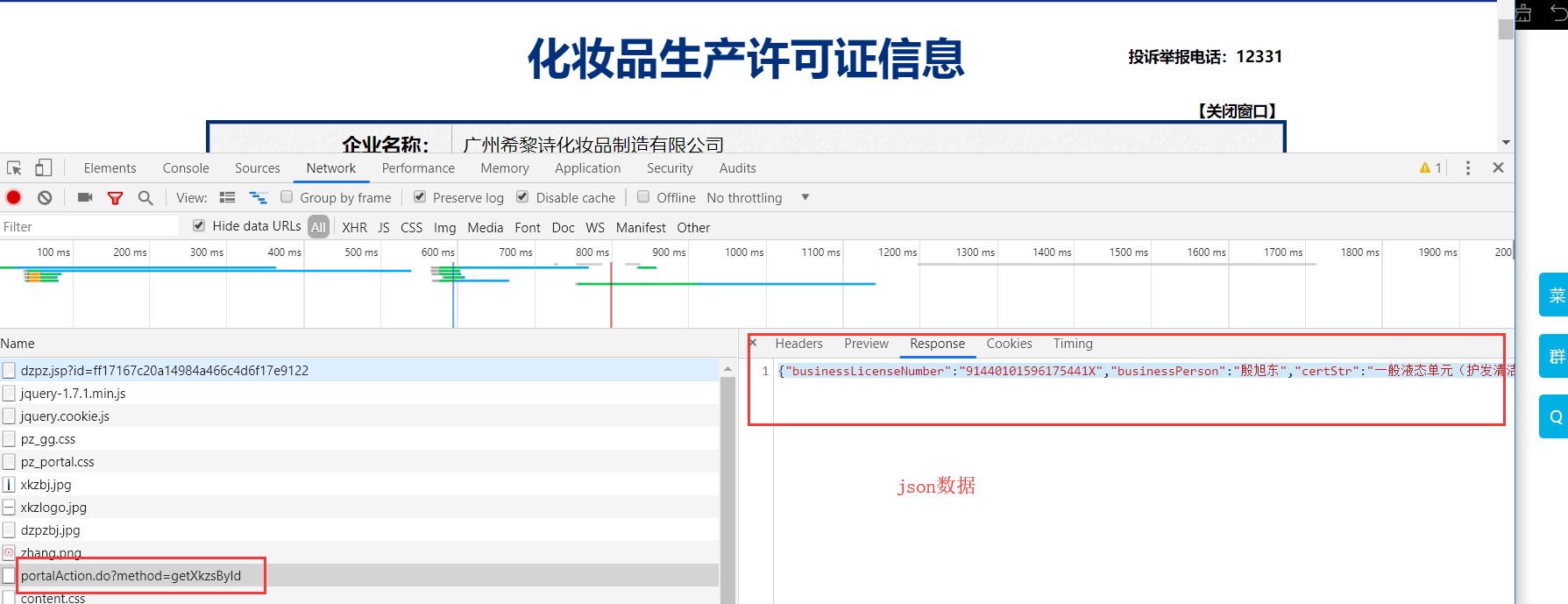
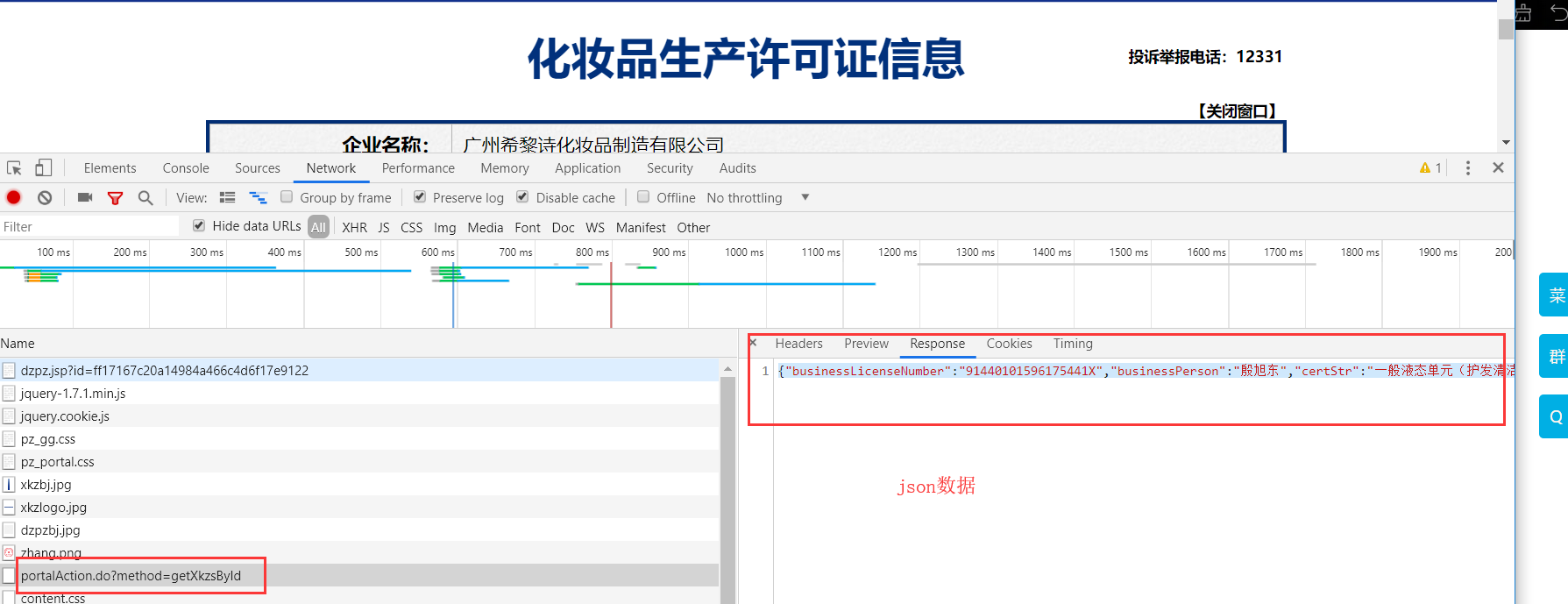
import requests from fake_useragent import UserAgent ua = UserAgent(use_cache_server=False).random headers = { 'User-Agent':ua } url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' for page in range(3,5): data = { 'on': 'true', 'page': str(page), 'pageSize': '15', 'productName':'', 'conditionType': '1', 'applyname':'', 'applysn':'' } json_text = requests.post(url=url,data=data,headers=headers).json() all_id_list = [] for dict in json_text['list']: id = dict['ID']#用于二级页面数据获取 #下列详情信息可以在二级页面中获取 # name = dict['EPS_NAME'] # product = dict['PRODUCT_SN'] # man_name = dict['QF_MANAGER_NAME'] # d1 = dict['XC_DATE'] # d2 = dict['XK_DATE'] all_id_list.append(id) #该url是一个ajax的post请求 post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' for id in all_id_list: post_data = { 'id':id } response = requests.post(url=post_url,data=post_data,headers=headers) #该请求响应回来的数据有两个,一个是基于text,一个是基于json的,所以可以根据content-type,来获取指定的响应数据 if response.headers['Content-Type'] == 'application/json;charset=UTF-8': #print(response.json()) #进行json解析 json_text = response.json() print(json_text['businessPerson'],json_text['productSn'],type(json_text['productSn']))