1.原因:没有控制语句导致的迭代器的越界,使得map中的数据无法传入reduce,从而无法把结果传入目标文件中。
在进行Mapreduce实例——WordCount实验时遇到的错误,开始以为是lib包导入和读取源文件格式的问题,后来无论怎么修改都会报这个错误,报错如下:
java.lang.Exception: java.util.NoSuchElementException
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:491)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:551)
Caused by: java.util.NoSuchElementException
at java.util.StringTokenizer.nextToken(StringTokenizer.java:349)
at mapreduce.WordCount$doMapper.map(WordCount.java:43)
at mapreduce.WordCount$doMapper.map(WordCount.java:1)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:793)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:270)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:473)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1152)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622)
at java.lang.Thread.run(Thread.java:748)
18/11/16 00:25:39 INFO mapreduce.Job: Job job_local1205845239_0001 failed with state FAILED due to: NA
18/11/16 00:25:39 INFO mapreduce.Job: Counters: 0
错误根源:
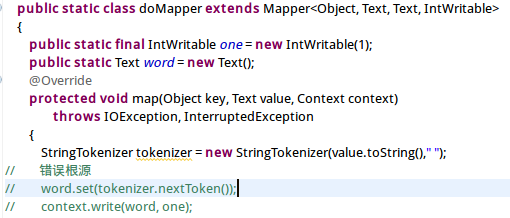
2.解决方案:
解决方案1
if(tokenizer.hasMoreTokens())
{
this.word.set(tokenizer.nextToken());
context.write(this.word, one);
}
解决方案2
if(!value.toString().equals(""))
{
word.set(tokenizer.nextToken());
context.write(word, one);
}