Redis高可用
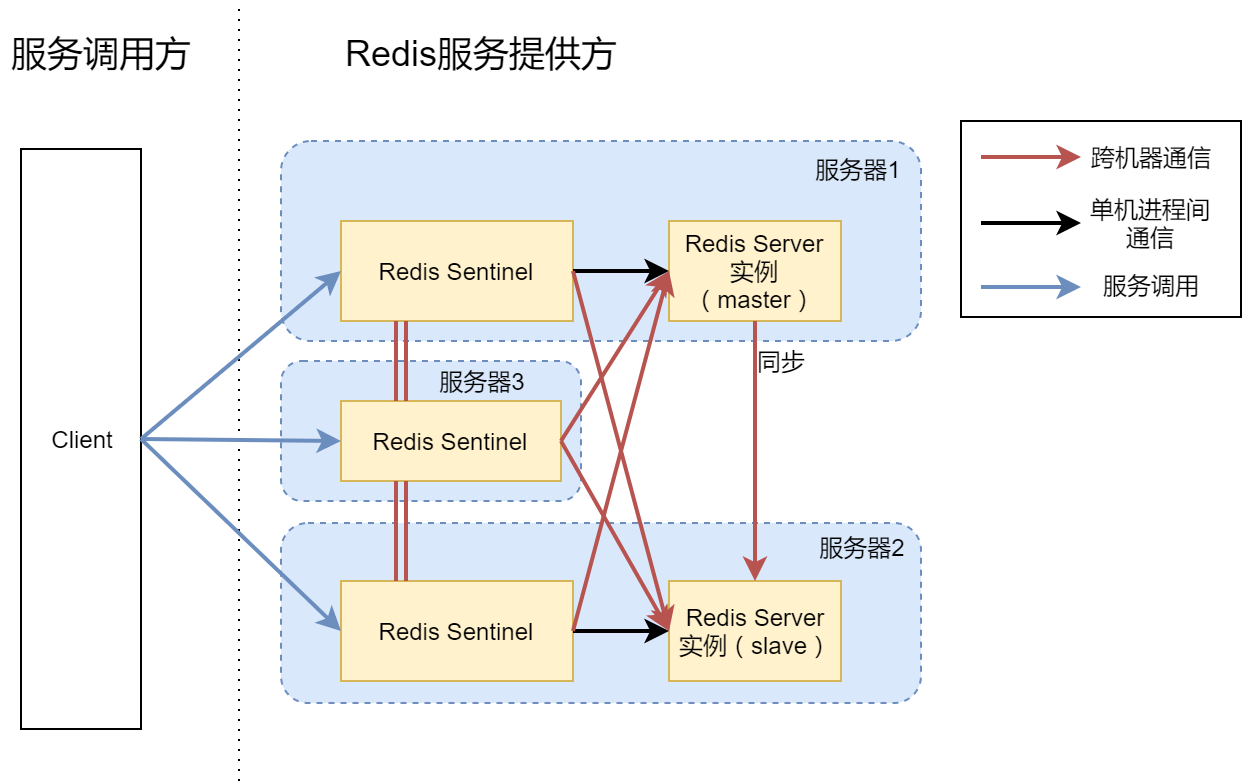
对于搭建高可用Redis服务,网上已有了很多方案,例:Keepalived,Codis,Twemproxy,Redis Sentinel。这里介绍官方的解决方案Redis Sentinel,图片来源:https://www.cnblogs.com/xuning/p/8464625.html
单机自娱版:

上图就是普通的服务,如果实例挂了就无法提供服务,不具有高可用性,一般高可用性是要求有两台以上机器,一主多备,其中主机器挂了,备用机器就会替代主机器提供服务。所以需要一个监控主从健康状态的进程,这里用到了一个解耦的方式,用一个Sentinel集群做这件事,产生高可用版本。
高可用版:
Redis的设定是只有当超过50%的Sentinel进程可以连通并投票选取新的master时,才会真正发生主从切换
Redis主从架构
如果只是缓存几个G的数据,那么单机Redis就足够了,但缓存主要用来读的,单机的QPS有一定的极限,一两万QPS一台应该没什么问题,但如果是几十万的QPS这类场景呢?Redis主从架构就非常合适。
主从架构主要是保证Redis的高并发性的,对于缓存来说,一般也都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。

Redis Replication核心机制:
- redis 采用异步方式复制数据到 slave 节点,不过 redis2.8 开始,slave node 会周期性地确认自己每次复制的数据量;
- 一个 master node 是可以配置多个 slave node 的;
- slave node 也可以连接其他的 slave node;
- slave node 做复制的时候,不会 block master node 的正常工作;
- slave node 在做复制的时候,也不会 block 对自己的查询操作,它会用旧的数据集来提供服务;但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了;
- slave node 主要用来进行横向扩容,做读写分离,扩容的 slave node 可以提高读的吞吐量。
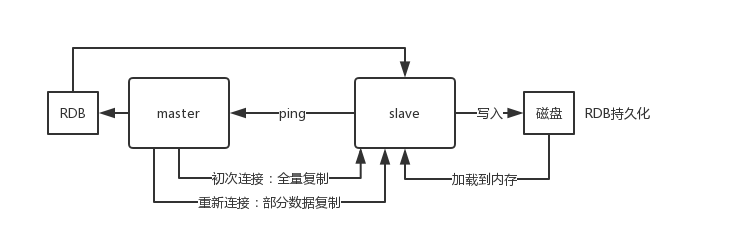
Redis 主从复制的核心原理:
当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node,如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制。此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件,同时还会将从客户端 client 新收到的所有写命令缓存在内存中。RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中,接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
Redis 过期Key处理:
slave 不会过期 key,只会等待 master 过期 key。如果 master 过期了一个 key,或者通过 LRU 淘汰了一个 key,那么会模拟一条 del 命令发送给 slave。
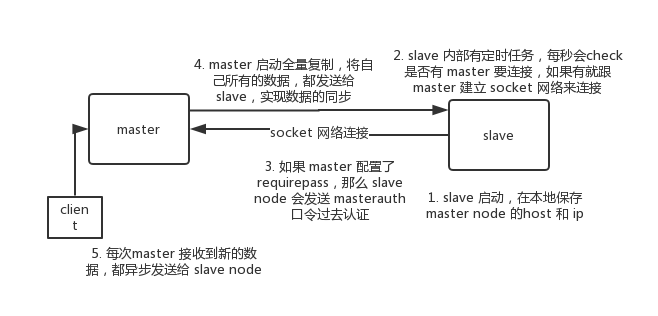
整体复制流程:
slave node 启动时,会在自己本地保存 master node 的信息,包括 master node 的host和ip,但是复制流程没开始。slave node 内部有个定时任务,每秒检查是否有新的 master node 要连接和复制,如果发现,就跟 master node 建立 socket 网络连接。然后 slave node 发送 ping 命令给 master node。如果 master 设置了 requirepass,那么 slave node 必须发送 masterauth 的口令过去进行认证。master node 第一次执行全量复制,将所有数据发给 slave node。而在后续,master node 持续将写命令,异步复制给 slave node。
参考文献:https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-master-slave.md