
比如第一个region 代表 0-100
第二个region 代表 101 -200的

分的越多越不好管理,但同时方便了并行化处理,并发度越高,处理的越快。
mapreduce就是按照rowkey的范围进行切分,这一点跟hdfs不一样。

由于不同的同一个表的不同region有可能在不同的节点机器上,这就方便了并发处理。
关于负载均衡:比如一个节点100个region 另外一个节点50个region,我们要做负载均衡,则会把25个region放到另一台机器。region是伏在均衡的最小单位,region不会再被分了。
每个column family存储在HDFS上的一个单独文件中
key和version number在每个column family中均有一份
空值不会被保存
Hbase为每个值维护了一个多级索引,即<key, column family, column name, timestamp>
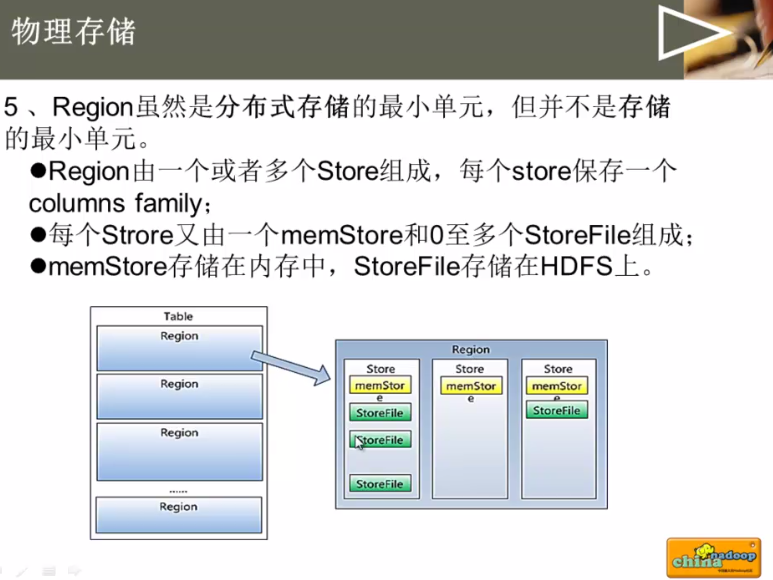
关键点是,一个store对应一个column family
如果一个查询来了,会先查memsotr 再查 storeFile 这里面要io了,当然这里会有一些优化机制。。。。。。hbase牵扯磁盘io的是在region 里的 sotrle