2018年学习总结博客总目录:[第一周](https://www.cnblogs.com/hzy0628/p/9606767.html) [第二周](https://www.cnblogs.com/hzy0628/p/9655903.html) [第三周](https://www.cnblogs.com/hzy0628/p/9700082.html) [第四周](https://www.cnblogs.com/hzy0628/p/9737321.html) [第五周](https://www.cnblogs.com/hzy0628/p/9786586.html) [第六周](https://www.cnblogs.com/hzy0628/p/9825081.html) [第七周](https://www.cnblogs.com/hzy0628/p/9873230.html) [第八周](https://www.cnblogs.com/hzy0628/p/9929202.html) [第九周](https://www.cnblogs.com/hzy0628/p/9966165.html)
教材学习内容总结
第十五章 图
1.图:图(graph)是由一些点(vertex)和这些点之间的连线(edge)所组成的;其中,点通常被成为"顶点(vertex)",而点与点之间的连线则被成为"边"(edge)。
2.图的分类:根据边是否有方向,将图可以划分为:无向图和有向图。
无向图是一种边为无序结点对的图。

有序图是一种边为有序结点对的图。

3.图的一些基本概念
- 无向图
(1)如果图中的两个顶点之间有一条连通边,则称这两个顶点是邻接的。
(2)邻接的顶点有时也互称为邻居。
(3)连通一个顶点及其自身的边称为自循环(self-loop)。
(4)如果无向图拥有最大数目的连通顶点的边,则认为这个无向图是完全的。对n个顶点的无向图,要使该该图为完全的,要有n*(n-1)/2条边。(假设没有边是自循环的。)
(5)路径是图的一系列边,每条边连通两个顶点。路径的长度是该路径中边的条数(顶点数减1)。
(6)如果无向图的任意两个顶点之间都存在一条路径,则认为这个无向图是连通的。
(7)环路是一种首顶点和末顶点相同且没有重边的路径。
(8)无向树是一种连通的无环无向图,其中一个元素被指定为树根。 - 有向图
(1)如果有向图中的任意两个顶点之间都存在一条路径,则认为该有向图是连通的。
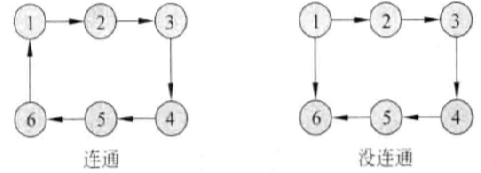
(2)如果有向图中没有环路,且有一条从A到B的边,则可以把顶点A排在B的边之前。这种排列得到的顶点次序称为拓排序。
(3)有向树是一种指定了一个元素作为树根的有向图,该图具有如下属性:
①不存在其它顶点到树根的连接
②每个非树根元素恰好有一个连接
③树根到每个其它顶点都有一条路径
4.网络(Network)
网络,或称加权图(weighted graph),是一种每条边都带有权重或代价的图。
网络可以使无向的,也可以是有向的。
对于网络,我们采用一个三元组来表示每条边。这个三元组包括起始顶点,终止顶点和权重。对无向网络来说,起始顶点与终止顶点可以互换,但对于有向网络来说,起始顶点与终止顶点不可以互换,因为每个有向连接上的权重不一定相等。
5.图算法
(一)遍历
分两种:广度优先遍历和深度优先遍历
(1)广度优先遍历

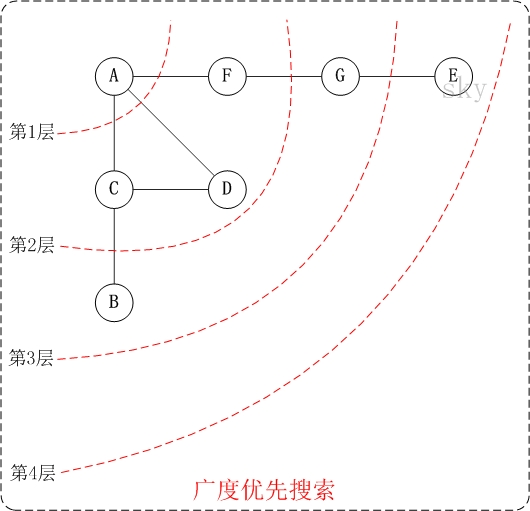
第1步:访问A。
第2步:依次访问C,D,F。
在访问了A之后,接下来访问A的邻接点。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,C在"D和F"的前面,因此,先访问C。再访问完C之后,再依次访问D,F。
第3步:依次访问B,G。
在第2步访问完C,D,F之后,再依次访问它们的邻接点。首先访问C的邻接点B,再访问F的邻接点G。
第4步:访问E。
在第3步访问完B,G之后,再依次访问它们的邻接点。只有G有邻接点E,因此访问G的邻接点E。
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
(2)深度优先遍历

第1步:访问A。
第2步:访问(A的邻接点)C。
在第1步访问A之后,接下来应该访问的是A的邻接点,即"C,D,F"中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在"D和F"的前面,因此,先访问C。
第3步:访问(C的邻接点)B。
在第2步访问C之后,接下来应该访问C的邻接点,即"B和D"中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。
第4步:访问(C的邻接点)D。
在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。
第5步:访问(A的邻接点)F。
前面已经访问了A,并且访问完了"A的邻接点B的所有邻接点(包括递归的邻接点在内)";因此,此时返回到访问A的另一个邻接点F。
第6步:访问(F的邻接点)G。
第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
(二)测试连通性
在一个含n个顶点的图中,当且仅当对每个顶点v,从v开始的广度优先遍历的resultList大小都是n,则该图是连通的。
代码如下:
public boolean isConnected()
{
boolean result = true;
for(int i=0;i<numVertices;i++){
int temp=0;
temp=getSizeOfIterator(this.iteratorBFS(vertices[i]));
if(temp!=numVertices)
{
result = false;
break;
}
}
return result;
}
private int getSizeOfIterator(Iterator iterator) {
int size = 0;
while(iterator.hasNext()){
size++;
iterator.next();
}
return size;
}
(三)最小生成树
生成树是一棵含有图中所有顶点和部分边(但可能不是所有边)的树。
最小生成树:其边的权重总和小于或等于同一个图中其他任何一棵生成树的权重总和。
算法:任取一个起始结点,将它添加到最小生成树中。然后,按照权重次序添加到minheap中,接着从minheap中取出最小边,并将这个边和那个新顶点添加到最小生成树中,下一步,我们往minheap中添加所有含该新顶点且另一顶点尚不在最小生成树中的边。继续这一过程,直到最小生成树含有原始图中的所有顶点(或minheap为空)时结束。
(四)判定最短路径
两种:两个顶点之间的最小边数;两个顶点之间的最小权重路
(1)最小边数:利用广度优先遍历,遍历期间对每个顶点存储另外两个记录:从起始顶点到本顶点的路径长度,以及在路径中作为本结点前驱的那个结点。修改循环:抵达目标顶点时循环即可终止。
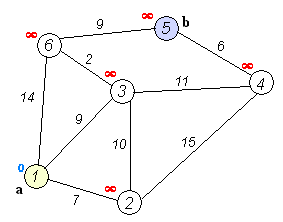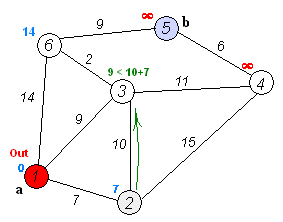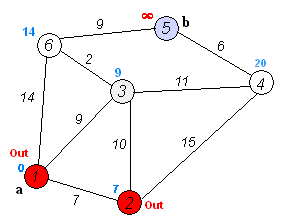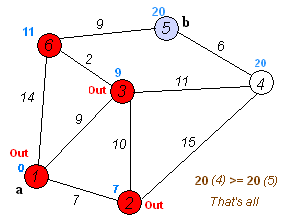
(2)最小权重路径:Dijkstra算法
基本思想
通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。
此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离)。
初始时,S中只有起点s;U中是除s之外的顶点,并且U中顶点的路径是"起点s到该顶点的路径"。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 ... 重复该操作,直到遍历完所有顶点。
操作步骤
(1) 初始时,S只包含起点s;U包含除s外的其他顶点,且U中顶点的距离为"起点s到该顶点的距离"[例如,U中顶点v的距离为(s,v)的长度,然后s和v不相邻,则v的距离为∞]。
(2) 从U中选出"距离最短的顶点k",并将顶点k加入到S中;同时,从U中移除顶点k。
(3) 更新U中各个顶点到起点s的距离。之所以更新U中顶点的距离,是由于上一步中确定了k是求出最短路径的顶点,从而可以利用k来更新其它顶点的距离;例如,(s,v)的距离可能大于(s,k)+(k,v)的距离。
(4) 重复步骤(2)和(3),直到遍历完所有顶点。
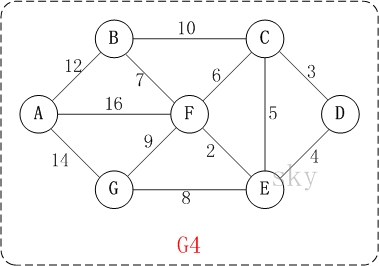
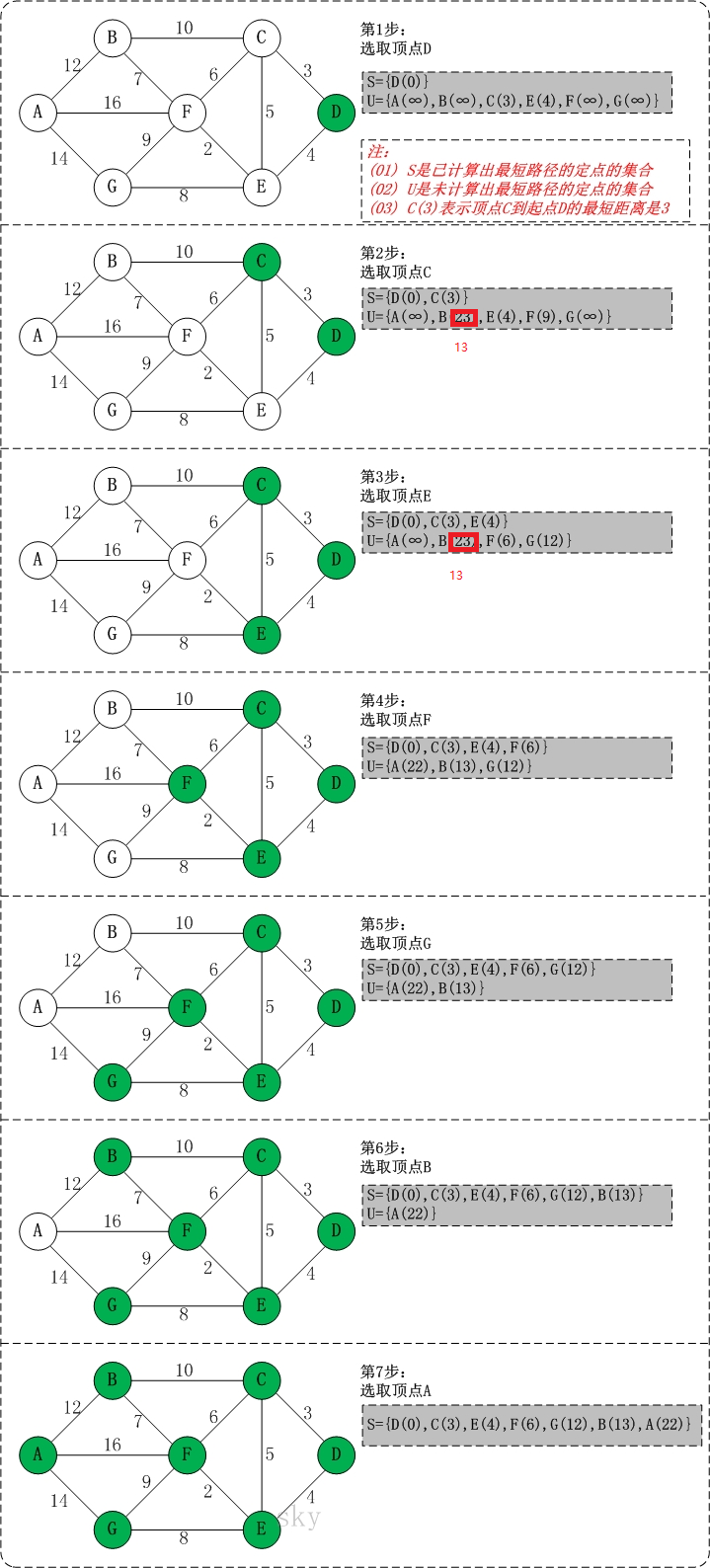
初始状态:S是已计算出最短路径的顶点集合,U是未计算除最短路径的顶点的集合!
第1步:将顶点D加入到S中。
此时,S={D(0)}, U={A(∞),B(∞),C(3),E(4),F(∞),G(∞)}。 注:C(3)表示C到起点D的距离是3。
第2步:将顶点C加入到S中。
上一步操作之后,U中顶点C到起点D的距离最短;因此,将C加入到S中,同时更新U中顶点的距离。以顶点F为例,之前F到D的距离为∞;但是将C加入到S之后,F到D的距离为9=(F,C)+(C,D)。
此时,S={D(0),C(3)}, U={A(∞),B(13),E(4),F(9),G(∞)}。
第3步:将顶点E加入到S中。
上一步操作之后,U中顶点E到起点D的距离最短;因此,将E加入到S中,同时更新U中顶点的距离。还是以顶点F为例,之前F到D的距离为9;但是将E加入到S之后,F到D的距离为6=(F,E)+(E,D)。
此时,S={D(0),C(3),E(4)}, U={A(∞),B(13),F(6),G(12)}。
第4步:将顶点F加入到S中。
此时,S={D(0),C(3),E(4),F(6)}, U={A(22),B(13),G(12)}。
第5步:将顶点G加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12)}, U={A(22),B(13)}。
第6步:将顶点B加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12),B(13)}, U={A(22)}。
第7步:将顶点A加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12),B(13),A(22)}。
此时,起点D到各个顶点的最短距离就计算出来了:A(22) B(13) C(3) D(0) E(4) F(6) G(12)。
参考链接:Dijkstra算法之Java详解
还有一个动图,也比较形象
6.图的实现策略
邻接列表和邻接矩阵:第一种是一个列表中元素为列表,这样构成的其实也是一个矩阵;第二种是直接用一个二元数组,直接就是一个矩阵。以实现无向图为例
(一)邻接列表
邻接表,存储方法跟树的孩子链表示法相类似,是一种顺序分配和链式分配相结合的存储结构。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。
(二)邻接矩阵
逻辑结构分为两部分:V和E集合。因此,用一个一维数组存放图中所有顶点数据;用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组称为邻接矩阵。邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵。
教材学习中的问题和解决过程
-
问题1:关于拓扑序,书上的叙述很难理解,同时也不清楚它的用处。

-
问题1解决方案:首先来看拓扑排序定义:
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
注意
①若将图中顶点按拓扑次序排成一行,则图中所有的有向边均是从左指向右的。
②若图中存在有向环,则不可能使顶点满足拓扑次序。
③一个DAG的拓扑序列通常表示某种方案切实可行。
【例】一本书的作者将书本中的各章节学习作为顶点,各章节的先学后修关系作为边,构成一个有向图。按有向图的拓扑次序安排章节,才能保证读者在学习某章节时,其预备知识已在前面的章节里介绍过。
④一个DAG可能有多个拓扑序列。
⑤当有向图中存在有向环时,拓扑序列不存在。
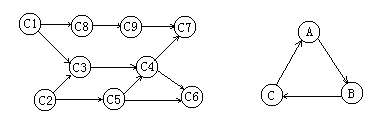
图1 图2
例如,下面的三个序列都是图1 的拓扑序列,当然还可以写出许多。而图2中则不会存在拓扑序列。
(1) C1,C8,C9,C2,C3,C5,C4,C7,C6
(2) C2,C1,C3,C5,C4,C6,C8,C9,C7
(3) C1,C2,C3,C8,C9,C5,C4,C6,C7
课程代号 课程名称 先修课程
C1 高等数学 无
C2 程序设计基础 无
C3 离散数学 C1,C2
C4 数据结构 C3,C5
C5 算法语言 C2
C6 编译技术 C4,C5
C7 操作系统 C4,C9
C8 普通物理 C1
C9 计算机原理 C8
例如,假定一个计算机专业的学生必须完成图3-4所列出的全部课程。在这里,课程代表活动,学习一门课程就表示进行一项活动,学习每门课程的先决条件是学完它的全部先修课程。如学习《数据结构》课程就必须安排在学完它的两门先修课程《离散数学》和《算法语言》之后。学习《高等数学》课程则可以随时安排,因为它是基础课程,没有先修课。若用AOV网来表示这种课程安排的先后关系,则如图3-5所示。图中的每个顶点代表一门课程,每条有向边代表起点对应的课程是终点对应课程的先修课。图中的每个顶点代表一从图中可以清楚地看出各课程之间的先修和后续的关系。如课程C5的先修课为C2,后续课程为C4和C6。
拓扑序列的实际意义是:如果按照拓扑序列中的顶点次序,在开始每一项活动时,能够保证它的所有前驱活动都已完成,从而使整个工程顺序进行,不会出现冲突的情况。
拓扑排序算法
拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之;
(2) 从网中删除此顶点及所有出边。
循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。
代码调试中的问题和解决过程
-
问题1:在做作业PP15.1时,即用邻接表构建图时,addVertex方法遇到空指针错误。

-
问题1解决方案:一开始构建邻接表是使用的是两个列表,顶点元素存于一个列表中,而边又存于另外一个列表中,这样做后来才知道其实是做麻烦了,一开始就对邻接表理解错了。
邻接表,存储方法跟树的孩子链表示法相类似,是一种顺序分配和链式分配相结合的存储结构。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。
上面的错误是通过构建一个新的列表,列表当中存储当前的元素,这样做完就不会出现空指针错误。
vertices.add(vertex);
List list = new ArrayList();
list.add(vertex);
adjMatrix.add(list);
numVertices++;
modCount++;
一直到了周五,老师讲完邻接表后,才知道自己这样做其实是做麻烦了,完全没有必要再去使用存储顶点的列表了。
代码托管

上周代码行数为15816行,现在为18065行,本周2249行。
上周考试错题总结
未进行考试
结对及互评
- 本周结对学习情况
- 20172308
- 博客中值得学习的或问题:博客中教材问题写得比较充实。
- 结对学习内容:第十五章——图
其他(感悟、思考等)
感悟
- 本周学习过程中比较难的是Dijkstara算法,这里仅靠书上的几行描述是不大好理解的,从网上查阅了一些资料,同时又询问了王老师,才在资料的基础上用两个集合实现了最小权重路径的查找,而没有使用最小堆,用最小堆去实现查找最小权重路线我还没有理解,实现起来可能也比较复杂。
- 这周还看了一些暑假做了App的同学的博客,感觉大家做的都挺好的。自己暑假时候偷懒,没有动手去实践一次,有点后悔了。望下周开始的APP小组开发自己多投入一些,尽力做的好一些,能够追上来。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 15/15 | |
| 第二周 | 572/572 | 1/2 | 16/31 | |
| 第三周 | 612/1184 | 1/3 | 13/44 | |
| 第四周 | 1468/2652 | 2/5 | 13/57 | |
| 第五周 | 1077/3729 | 1/6 | 14/71 | 初步理解各个排序算法 |
| 第六周 | 1087/4816 | 1/7 | 17/88 | 认识树结构 |
| 第七周 | 1252/6068 | 1/8 | 19/107 | 平衡二叉树、AVL树、红黑树 |
| 第八周 | 2065/8133 | 2/10 | 17/124 | 堆、最小堆 |
| 第九周 | 2249/10382 | 1/11 | 18/142 | 图及其实现 |