2018年学习总结博客总目录:[第一周](https://www.cnblogs.com/hzy0628/p/9606767.html) [第二周]()
教材学习内容总结
第三章 集合概述—栈
-
3.1 集合
(1) 集合是一种聚集,组织了其他对象的对象。它定义一张破那个特定的方式,可以访问、管理所包含的对象。
(2)集合的分类:1)按其元素是否按直线方式组织进行划分,分为线性集合(linear collection)和非线性集合(nonlinear collection);2)按保存类型划分,分为同构集合和异构集合。
(3)抽象数据类型:一个抽象数据类型(ADT)是由数据和在该数据上所实施的操作构成的集合,一个ADT有名称、值域和一组允许执行的操作。
(4)Java集合类API:Java标准类库中定义了几种不同类型集合的类,称为Java集合类API。 -
3.2 栈集合
(1)栈(stack)是一种线性集合,其元素添加和删除都在同一端进行。
(2)栈的元素是按照后进先出(LIFO)(即 Last in ,first out)的方法进行处理的,最后进入栈中的元素最先被移出。
(3) 栈的一些操作:
| 操作 | 描述 |
|---|---|
| push | 把项压入堆栈顶部 |
| pop | 移除堆栈顶部的对象,并作为此函数的值返回该对象 |
| peek | 查看堆栈顶部的对象,但不从堆栈中移除它 |
| isempty | 测试堆栈是否为空 |
| size | 确定栈的元素数目 |
| search | 返回对象在堆栈中的位置,以 1 为基数 |
-
3.3 主要的面向对象的概念
(1)继承:继承的过程是在两个类之间建立一种“是”的关系,即子类是一种更具体的父类版本。
(2)由继承实现多态性:当用类名声明一个引用变量时,这个变量可以指向该类的任何一个对象,同时,它也能引用通过继承与它所声明的类型有关的任何类的对象。
(3)泛型(generic type):一个集合所管理的对象的类型要在实例化该集合对象时才确定。泛型保证了集合中对象类型的兼容性。 -
3.4 异常
(1)异常(exception)就是一种对象,它定义了一种非正常或错误的情况。异常有程序或运行时环境抛出,可以按预期的被捕获或被正确处理。
(2)错误(error)与异常相似,不过异常表示一种无法恢复的情况,且不必去捕获它。
(3)Java有一个预定义的异常和错误集,当程序运行时他们可能会发生。 -
3.5 栈ADT
栈接口类中的各个方法
public interface Stack<T>
{
// Adds the specified element to the top of the stack.
public void push (T element);
// Removes and returns the top element from the stack.
public T pop();
// Returns a reference to the top element of this stack without removing it.
public T peek();
// Returns true if this stack contains no elements and false otherwise.
public boolean isEmpty();
// Returns the number of elements in the stack.
public int size();
// Returns a string representation of the stack.
public String toString();
}
-
3.6 ArrayStack类
- 表头
package jsjf;
import jsjf.exceptions.*;
import java.util.Arrays;
public class ArrayStack<T> implements StackADT<T>
{
private final static int DEFAULT_CAPACITY = 100;
private int top;
private T[] stack;
- 构造函数:两个构造函数,一个使用的为默认容量,一个使用的是指定容量,这里使用了方法重载。
public ArrayStack()
{
this(DEFAULT_CAPACITY);
}
public ArrayStack(int initialCapacity)
{
top = 0;
stack = (T[])(new Object[initialCapacity]);
}
- 实现方法
public void push(T element) {
if (size() == stack.length)
expandCapacity();
stack[top] = element;
top++;
}
private void expandCapacity()
{
stack = Arrays.copyOf(stack, stack.length * 2);
}
@Override
public T pop() {
if (isEmpty())
throw new EmptyCollectionException("stack");
top--;
T result = stack[top];
stack[top] = null;
return result;
}
@Override
public T peek() {
if (isEmpty())
throw new EmptyCollectionException("stack");
return stack[top-1];
}
@Override
public boolean isEmpty() {
if (top==0)
return true;
else
return false;
}
@Override
public int size() {
return top;
}
第四章 链式结构—栈
1.链式结构是一种数据结构,它使用对象引用变量来创建对象之间的链接。
2.使用下面的这个类边可以创建一个链式结构,一个Person对象含有指向两个Person对象的链接,如此类推,这种类型的对象由称为自引用的。
public class Person
{
private String name;
private String address;
private Person next;
}
3.所有动态创建的对象都来自于一个名为系统堆(system heap)或自由存储(free store)的内存区。
4.管理链表包括以下几个方面:
(1)访问元素
要访问其元素,我们必须先访问第一个元素,然后顺着下一个指针从一个元素到另一个元素。同时注意必须要维护指向链表的第一个指针。
(2)插入节点
首先,新添加节点的next引用被设置为指向链表的当前首结点,接着,指向链表前端的引用重新设置为指向这个新添加的节点。
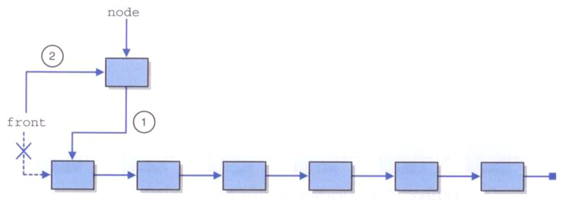
(3)删除节点
要删除链表的首结点,需要重置指向链表前端的引用,使其指向链表当前的次结点。

5.无链接的元素
(1)定义一个单独的结点类,将所有元素链接在一起
(2)双向链表
6.LinkedList类
- 构造函数
//--------------------------------------------------------------------
// Creates an empty stack using the default capacity.
//--------------------------------------------------------------------
public LinkedStack() {
count = 0;
top = null;
}
- 实现方法
//删除并返回栈顶元素
public void push(T element) {
LinearNode<T> eNode = new LinearNode<>(element); //新元素入栈对应新的对象
eNode.setNext(top); //新结点next引用指向栈顶
top = eNode;
count++;
}
//返回当前栈顶所保存元素的引用
public T peek() throws EmptyStackException {
return top.getElement();
}
public boolean isEmpty() {
return count == 0;
}
public int size() {
return count;
}
教材学习中的问题和解决过程
-
问题1:关于泛型的理解,泛型上学期涉及但未使用,这次看书上泛型代码就看不明白,“T”到底是在指什么?
-
问题1解决方案:于是我把书上讲解泛型的部分重新看了一遍,又结合某公众号讲解总结了以下内容。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
- 泛型类
首先定义一个简单的Box类:
public class Box {
private String object;
public void set(String object) { this.object = object; }
public String get() { return object; }
}
这是最常见的做法,这样做的一个坏处是Box里面现在只能装入String类型的元素,如果我们需要装入Int等其他类型的元素,还必须要另外重写一个Box,代码得不到复用,使用泛型可以很好的解决这个问题。
public class Box<T> {
// T stands for "Type"
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
这样我们的Box类便可以得到复用,我们可以将T替换成任何我们想要的类型:
Box<Integer> integerBox = new Box<Integer>();
Box<Double> doubleBox = new Box<Double>();
Box<String> stringBox = new Box<String>();
这样一来,T的含义就很明晰了,T它是可以代指我们所需要的任何类型,用起来也会很方便。
- 泛型的作用
我们可以定义一个类,它存储、操作和管理的对象的数据类型直到该类被实例化时才被指定,这使得结构的创建不仅可以操作“泛型”元素,而且还可以提供类型检查。
-
问题2:java.util.Stack的实现有哪些优点,又存在哪些潜在的问题?
-
问题2解决方案:我们首先了解到java.util.Stack类是从Vector类派生而来,而Vector本身是一个可增长的对象数组( a growable array of objects)
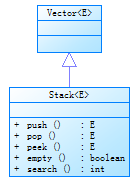
然后再去查找到Stack类的源码
public class Stack<E> extends Vector<E> {
/**
* Creates an empty Stack.
*/
public Stack() {
}
/**
* Pushes an item onto the top of this stack. This has exactly
* the same effect as:
* <blockquote><pre>
* addElement(item)</pre></blockquote>
*
* @param item the item to be pushed onto this stack.
* @return the <code>item</code> argument.
* @see java.util.Vector#addElement
*/
public E push(E item) {
addElement(item);
return item;
}
/**
* Removes the object at the top of this stack and returns that
* object as the value of this function.
*
* @return The object at the top of this stack (the last item
* of the <tt>Vector</tt> object).
* @exception EmptyStackException if this stack is empty.
*/
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
/**
* Looks at the object at the top of this stack without removing it
* from the stack.
*
* @return the object at the top of this stack (the last item
* of the <tt>Vector</tt> object).
* @exception EmptyStackException if this stack is empty.
*/
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
/**
* Tests if this stack is empty.
*
* @return <code>true</code> if and only if this stack contains
* no items; <code>false</code> otherwise.
*/
public boolean empty() {
return size() == 0;
}
/**
* Returns the 1-based position where an object is on this stack.
* If the object <tt>o</tt> occurs as an item in this stack, this
* method returns the distance from the top of the stack of the
* occurrence nearest the top of the stack; the topmost item on the
* stack is considered to be at distance <tt>1</tt>. The <tt>equals</tt>
* method is used to compare <tt>o</tt> to the
* items in this stack.
*
* @param o the desired object.
* @return the 1-based position from the top of the stack where
* the object is located; the return value <code>-1</code>
* indicates that the object is not on the stack.
*/
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 1224463164541339165L;
}
1.通过源码发现,Vector类在初始化的时候,会构造一个大小为10是空间
2.Stack中的pop、peek、search为线程安全类型
3.时间复杂度:
索引: O(n)
搜索: O(n)
插入: O(1)
移除: O(1)
通过peek()方法注释The object at the top of this stack (the last item of the Vector object,可以发现数组(Vector)的最后一位即为Stack的栈顶
pop、peek以及search方法本身进行了同步
push方法调用了父类的addElement方法
empty方法调用了父类的size方法
由此我们可以了解到Stack类,它通过五个操作对类Vector 进行了扩展 ,允许将向量视为堆栈。它提供了通常的push 和 pop 操作,以及取堆栈顶点的peek 方法、测试堆栈是否为空的 empty 方法、在堆栈中查找项并确定到堆栈顶距离的search 方法。由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的。它可以使用一个索引来跟踪栈中元素的位置。同时,由于它继承自Vector类,它继承了很多与栈的基本假设相互冲突的操作。
- 关于synchronized解释
Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。
一、当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
二、然而,当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
三、尤其关键的是,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将被阻塞。
四、第三个例子同样适用其它同步代码块。也就是说,当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
五、以上规则对其它对象锁同样适用.
代码调试中的问题和解决过程
-
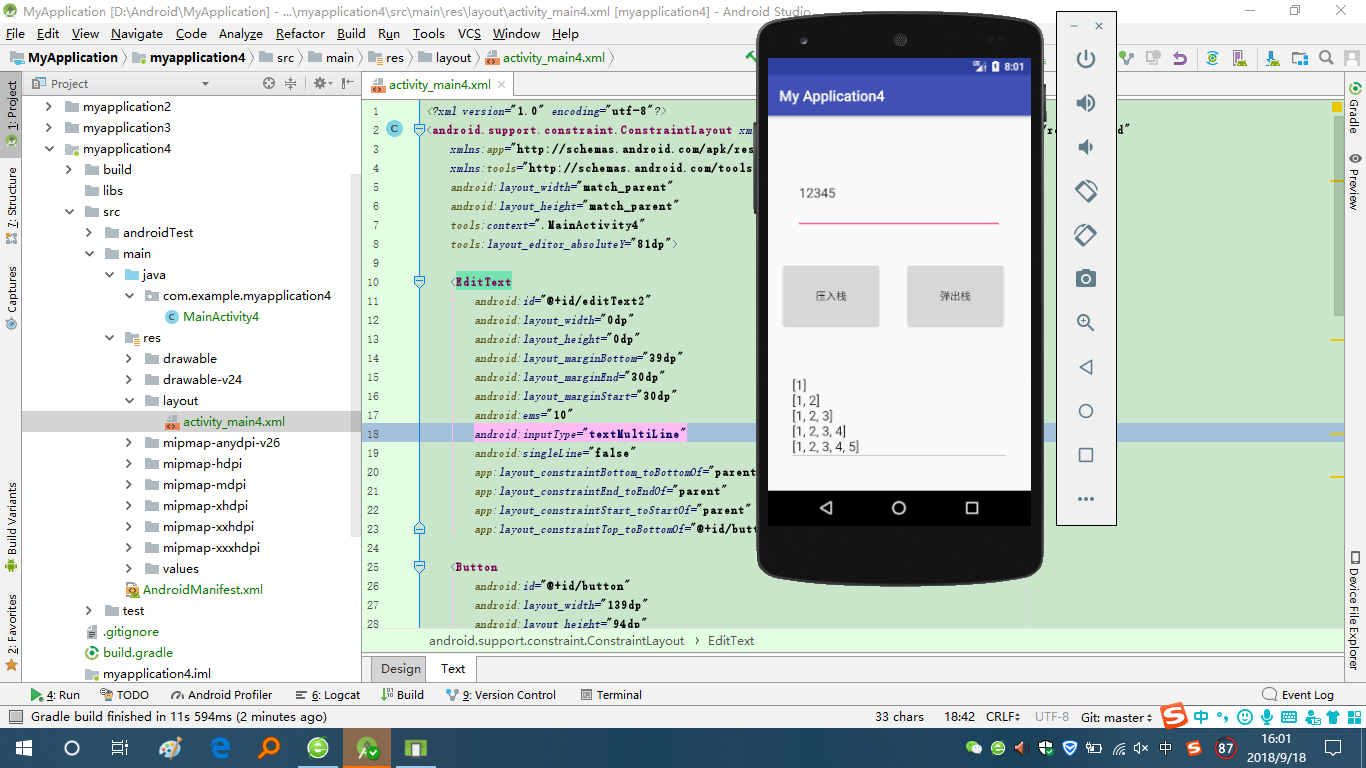
问题1:关于Android Studio中文本显示换行问题,如图

-
问题1解决方案:参考上学期所做app,将layout文件夹下xml文件中text中代码做了这些修改,将
android:singleLine="true"中true改为false,同时添加一行代码android:inputType="textMultiLine",修改完之后程序运行如图:
-
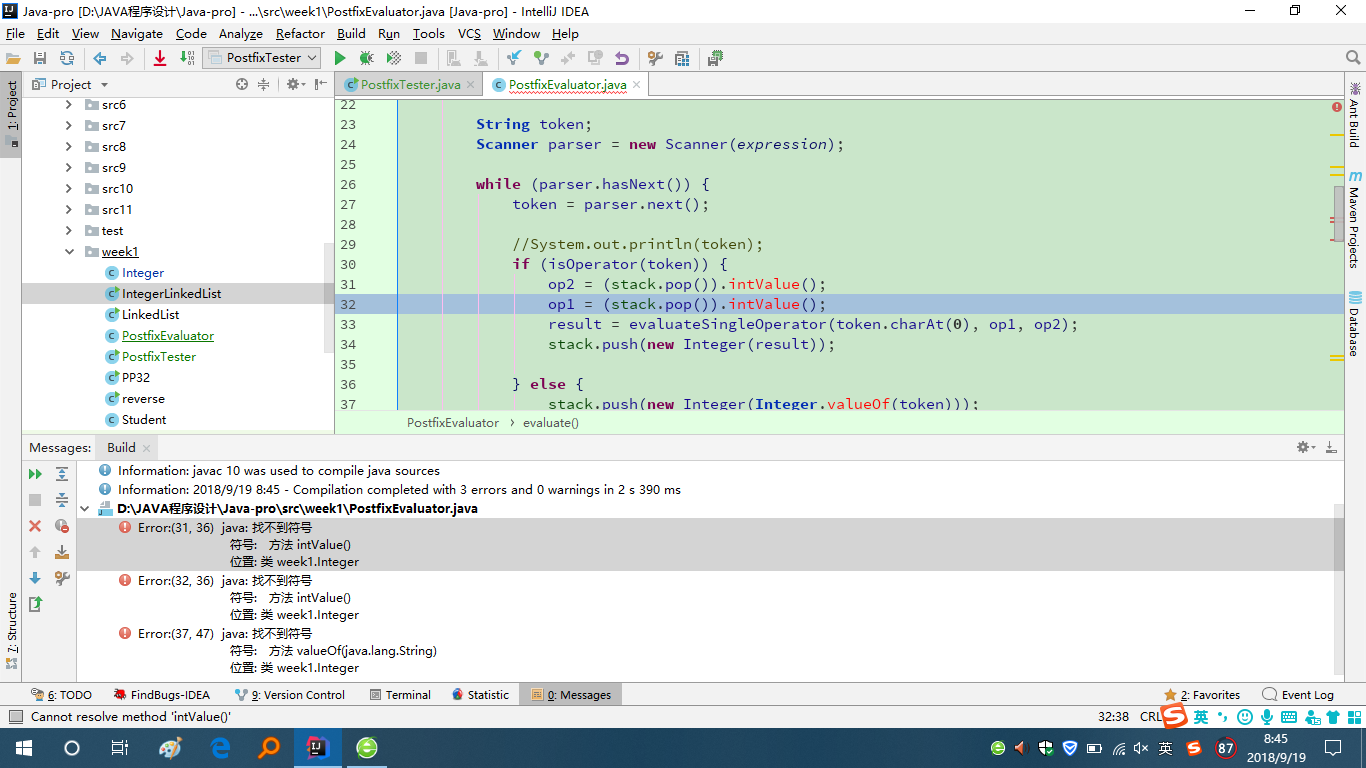
问题2:关于书上intValue方法变红问题:
-
这里是因为我自己创建的一个Integer类与java自定义中的Integer类造成冲突,而这里一开始使用的是自定义类,没有这个方法,造成不能编译运行,将自定义类更名之后即可。
- intValue方法,这是第一次接触这个方法。
intValue()
如Integer类型,就回有intValue()方法意识是说,把Integer类型转化为Int类型。其他类似,都是一个意思
valueOf()
如String就有valueOf()方法,意识是说,要把参数中给的值,转化为String类型,Integer的valueOf()就是把参数给的值,转化为Integer类型。其他类似,都是一个意思。
代码托管
上学期结束时为7683行,现在为8255行,本周共572行
上周考试错题总结
-
1.Software systems need only to work to support the work of developers, maintainers, and users.【×】
-
解析:软件系统不仅仅只需要支持开发人员、维护人员和用户的工作。
-
2.Which Growth function has the highest order?
A .O(n log n)
B .O(n2)
C .O(2n)
D .O(log n) -
解析:这道题目是问哪个增长函数具有最高的阶次,我们知道一个结论
c(常量)<㏒₂n < n < n㏒₂n < n²< n³ < 2ⁿ < 3ⁿ< n!,所以题目中的四个函数显然是2ⁿ的阶次是最高的,这里出错是因为当时把2ⁿ看成了2×n,误选了B。
结对及互评
- 本周结对学习情况
-
博客中值得学习的或问题: 博客中代码问题解决过程记录较详细,可适当添加教材内容总结。
-
结对学习内容:第三章内容:集合概述——栈,第四章内容:链式结构——栈
其他(感悟、思考等)
感悟
- 本周学习内容相较上周增多,同时也开始了写代码的作业,对栈的这部分内容有了进一步认识,不仅要会使用栈,还要会去用数组,链表等去实现一个栈。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 15/15 | |
| 第二周 | 572/572 | 1/2 | 16/31 |