2018年学习总结博客总目录:[第一周](http://www.cnblogs.com/hzy0628/p/8539037.html) [第二周](http://www.cnblogs.com/hzy0628/p/8584976.html) [第三周](http://www.cnblogs.com/hzy0628/p/8642935.html) [第四周](http://www.cnblogs.com/hzy0628/p/8671888.html) [第五周](http://www.cnblogs.com/hzy0628/p/8746606.html) [第六周](http://www.cnblogs.com/hzy0628/p/8830819.html) [第七周](http://www.cnblogs.com/hzy0628/p/8870071.html) [第八周](http://www.cnblogs.com/hzy0628/p/8940111.html) [第九周](http://www.cnblogs.com/hzy0628/p/9027708.html)
教材学习内容总结
第11章 异常
1.一个异常是指一个定义非正常情况或错误的对象,由程序或运行时环境抛出,可以根据需要进行相应的捕获和处理。而错误类似于异常,但是错误代表不可恢复的问题并且必须捕获处理。
2.一个异常确实代表了一个错误,但是异常只是代表了一种意外的情况,即一种在正常条件下不会发生的情况,异常处理提供了一种处理异常的有效方式。
3.程序设计中异常处理有以下三种选择:
· 根本不处理异常
· 当异常发生时处理异常
· 在程序某个位置集中处理异常
4.对于未进行捕获的异常,当异常发生时,程序会立即结束执行,并输出与异常有关的信息,第一行输出信息表明抛出异常类型及原因,其他行为方法调用堆栈踪迹信息(call stack trace),指明异常发生位置。其中第一个踪迹行指出发生异常的方法、文件、代码行号,若有其他行,则指出调用异常方法的其他方法。
5.try-catch语句:用于定义如何处理一种指定的异常。try语句块可以有多个相关联的catch子句,每个catch子句称为一个异常处理器。执行try语句块中语句,若没有抛出异常,将继续执行try语句后语句,如果其中某处发生了异常,并存在该catch子句,则立即转移到相应的catch子句处理异常,执行以后再转移到整个try-catch语句后的语句继续执行。一个try-catch语句可以有一个可选的finally子句,用于定于一段无论是否有异常发生都将执行的代码语句。
6.异常的传递:如果一个异常的发生处没有捕获和处理该异常,则该异常将会传递给上级调用方法(外层调用),异常也可以在外层调用中使用try-catch语句块进行处理和解决。
7.异常的层次结构:Throwable是Error类和Exception类的父类,许多类型的异常类都由Exception类派生。自定义异常:可由Exception类或它的后代派生一个新类来定义的一个新的异常。
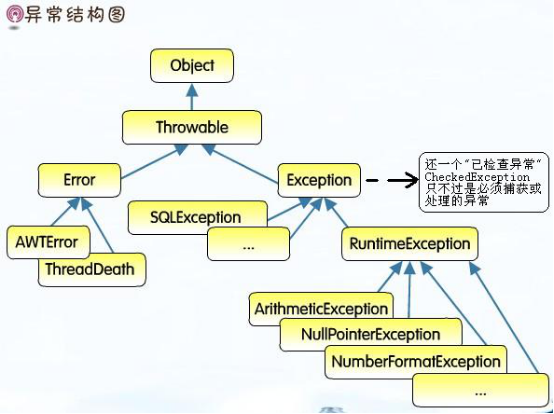
8.可检测异常和不可检测异常
-
可检测异常必须由方法进行捕获,或者必须在可能抛出或传递异常方法的throws子句中列出来。在方法头中追加一条throws子句,就明确承诺了该方法在异常发生时将抛出或传递异常。对于可检测异常,如果发生该异常的方法不捕获和处理这个异常,则必须在该方法定义的声明头中包含throws子句。
-
不可检测异常是RuntimeException类的对象或该类的后代类对象,其他异常均为可检测异常。
第12章 递归
1.递归是一种编程技术,允许一个方法调用自己以达到最终的目的,递归是一种以自身定义自身的过程。
2.列表的定义包含了非递归定义和递归定义两部分,非递归定义又称作基本情况。如果只有递归的那部分,则递归将会永无终止,这种情况被称为无穷递归。
3.递归编程,递归编程利用递归思想,一个简单的例子(求n的阶乘)。递归方法必定有一条if-else语句,其中一个分支为检测基本情况的值,另一分支作为递归部分使用。
factorial(n){
if(n == 1) return 1;
else return factorial(n-1)*n;
}
4.递归与迭代的比较:迭代与递归其实都可以解决同一个问题,重点在于哪个方法更方便,对于有些问题,递归可能用起来很精炼简单,但对于迭代则比较复杂;相反地,有些问题则是使用迭代更为简单。
5.直接递归与间接递归:一个方法调用自己的递归,称为直接递归。如果一个方法调用其他方法,最终导致再次调用自己,这称为间接递归。间接递归可以有若干层间接调用的深度,下面是间接递归的一个调用过程图。

6.递归的应用:(1)迷宫问题(2)汉诺塔问题
迷宫:
从起始位置(0,0)到终点位置(7,12)搜索
traverse(row,column){
if(出口(7,12)且值为1)true;3
else {
done=traverse(row+1,column)
if(!done)traverse(row,column+1)
if(!done)traverse(row-1,column)
if(!done)traverse(row,column-1)
}
if(done)(row,column)=7;
}
汉诺塔问题:
将最顶上的N-1个圆盘从原始塔座移到附加塔座
将最大的圆盘从原始塔座移到目标塔座
将N-1个圆盘从附加塔座移到目标塔座
教材学习中的问题和解决过程
-
问题1:首先就是关于堆栈踪迹这里,主要是做蓝墨云题目时就混淆了,不理解堆栈踪迹的使用和产生。
-
问题1解决方案:看课本的讲解始终就是不能理解,于是看到有书上【例11.3】,就把它敲了一遍,做完之后,理解了蓝墨云的那道题目。
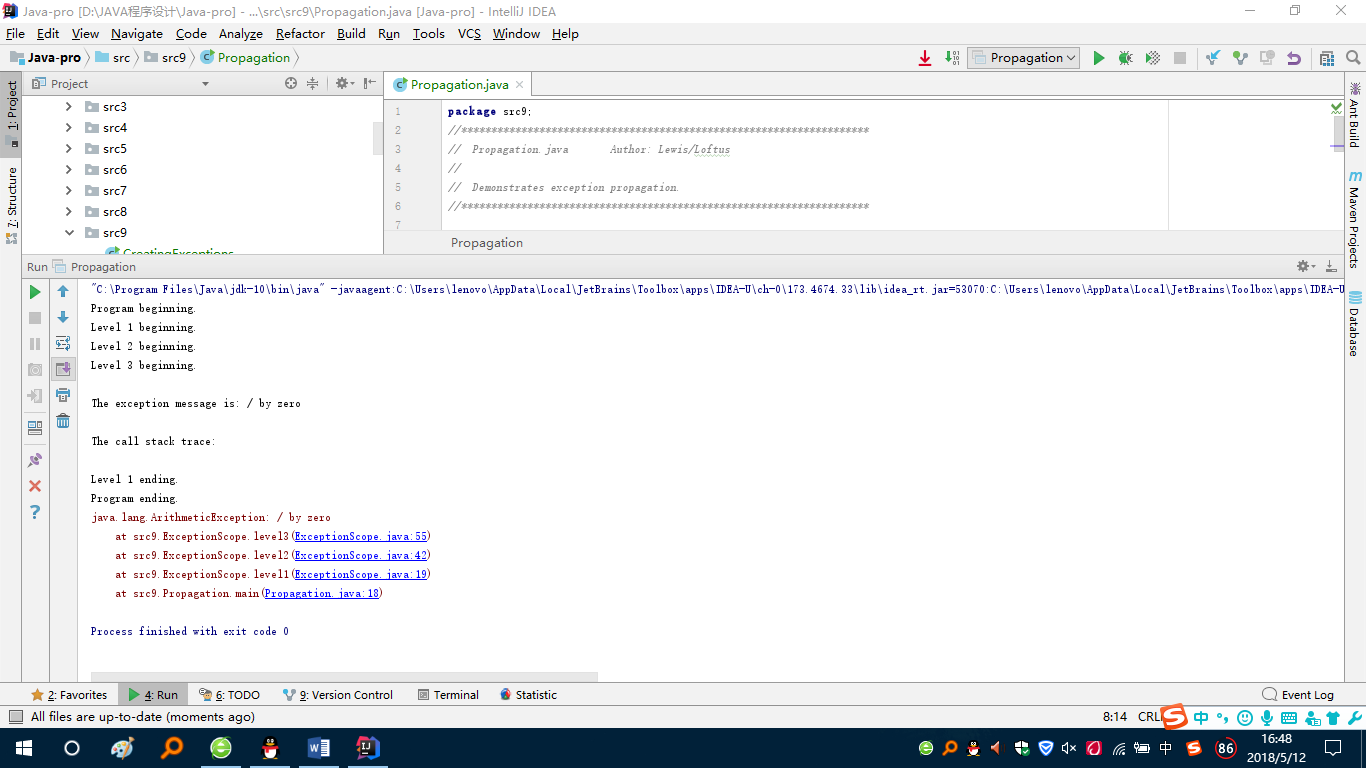
观察这个,我们可以看到它的异常其实最先发生的地方应该是在Level1处,其次是Level2,最后才是Level3,然后main函数中没有try语句块,就会直接抛出异常结束程序运行,然后在堆栈踪迹中可以看到显示的从上到下依次是Level3、Level2、Level1的异常,这其实符合栈的入栈和出栈的规则,先放的会在最里面,也就会后弹出,也就是会显示在下面。
-
问题2:关于书上的可检测异常和不可检测异常,这里自己也是不明白,还有throws子句到底是应该怎么去使用?
-
问题2解决方案:这里是有王志伟同学分享给我的一些资料,然后结合书上的理解,总的来说,就是可检测异常方法定义的声明头中要追加throws子句,在方法中我们要添加throw语句,抛出问题。 同时对于可检测异常,如果发生异常的方法不捕获和处理这个异常,字必须在该方法中定义的声明头中包含throws子句,不然异常将不会进行抛出。
对于不可检测异常,它只能是RuntimeException类的对象或该类的后代类对象,不需要throws子句和throw语句,对于它的处理有以下的三种方式。
对于我们自定义的一个异常,目前我使用过的都是可检测的异常,关于不可检测的自定义异常还没有使用过。
对未检查的异常(unchecked exception )的几种处理方式:
1、捕获
2、继续抛出
3、不处理
对检查的异常(checked exception,除了RuntimeException,其他的异常都是checked exception )的几种处理方式:
1、继续抛出,消极的方法,一直可以抛到java虚拟机来处理
2、用try...catch捕获
注意,对于检查的异常必须处理,或者必须捕获或者必须抛出。
参考链接:检查异常和未检查异常的不同之处
-
问题3:续上面的一个小问题,就是错误和异常到底是有什么区别?
-
问题3解决方案:这里找了一份资料,不再重复了,见下。
1).java.lang.Error: Throwable的子类,用于标记严重错误。合理的应用程序不应该去try/catch这种错误。绝大多数的错误都是非正常的,就根本不该出现的。
java.lang.Exception: Throwable的子类,用于指示一种合理的程序想去catch的条件。即它仅仅是一种程序运行条件,而非严重错误,并且鼓励用户程序去catch它。
2).Error和RuntimeException 及其子类都是未检查的异常(unchecked exceptions),而所有其他的Exception类都是检查了的异常(checked exceptions).
checked exceptions: 通常是从一个可以恢复的程序中抛出来的,并且最好能够从这种异常中使用程序恢复。比如FileNotFoundException, ParseException等。检查了的异常发生在编译阶段,必须要使用try…catch(或者throws)否则编译不通过。
unchecked exceptions: 通常是如果一切正常的话本不该发生的异常,但是的确发生了。发生在运行期,具有不确定性,主要是由于程序的逻辑问题所引起的。比如ArrayIndexOutOfBoundException, ClassCastException等。从语言本身的角度讲,程序不该去catch这类异常,虽然能够从诸如RuntimeException这样的异常中catch并恢复,但是并不鼓励终端程序员这么做,因为完全没要必要。因为这类错误本身就是bug,应该被修复,出现此类错误时程序就应该立即停止执行。 因此,面对Errors和unchecked exceptions应该让程序自动终止执行,程序员不该做诸如try/catch这样的事情,而是应该查明原因,修改代码逻辑。
RuntimeException:RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等。
处理RuntimeException的原则是:如果出现 RuntimeException,那么一定是程序员的错误。例如,可以通过检查数组下标和数组边界来避免数组越界访问异常。其他(IOException等等)checked异常一般是外部错误,例如试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
-
问题4:递归和迭代具体应该怎么去区分使用,两者具体的分别在哪些方面,哪些问题使用哪种更加方便?
-
问题4解决方案:这里也是在找资料,从网上找的认为比较好的一份是这样,做成了一个表:
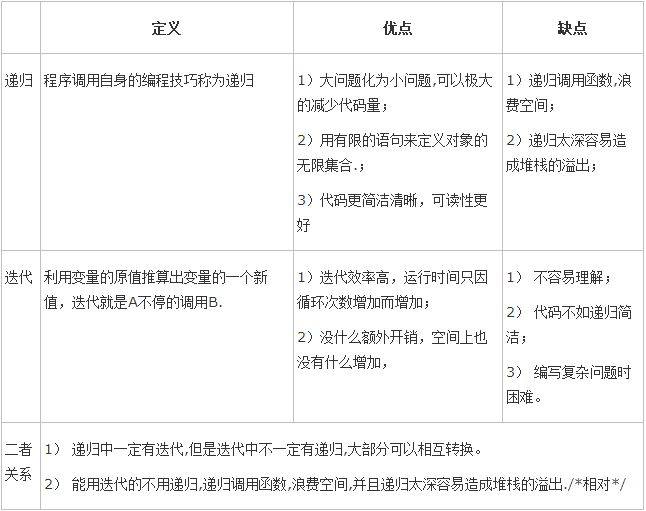
这个会帮助了我的理解,但是还不太明白的地方是“迭代不容易理解”,但现在给我的感觉是递归好像是不容易理解吧,可能后面的迭代会比较复杂不容易理解吧,还看了这么一个答案:
电影故事例证:
迭代——《明日边缘》
递归——《盗梦空间》
代码调试中的问题和解决过程
- 问题1:编程项目PP12.1,这里要对PalindromeTester程序改为递归版本,之前的这个程序忘了,又重新看,重新找思路,方向有了以后还是有一些问题,见图。
先是这样,没有输出,什么都没有。

然后又是这样,抛出异常:
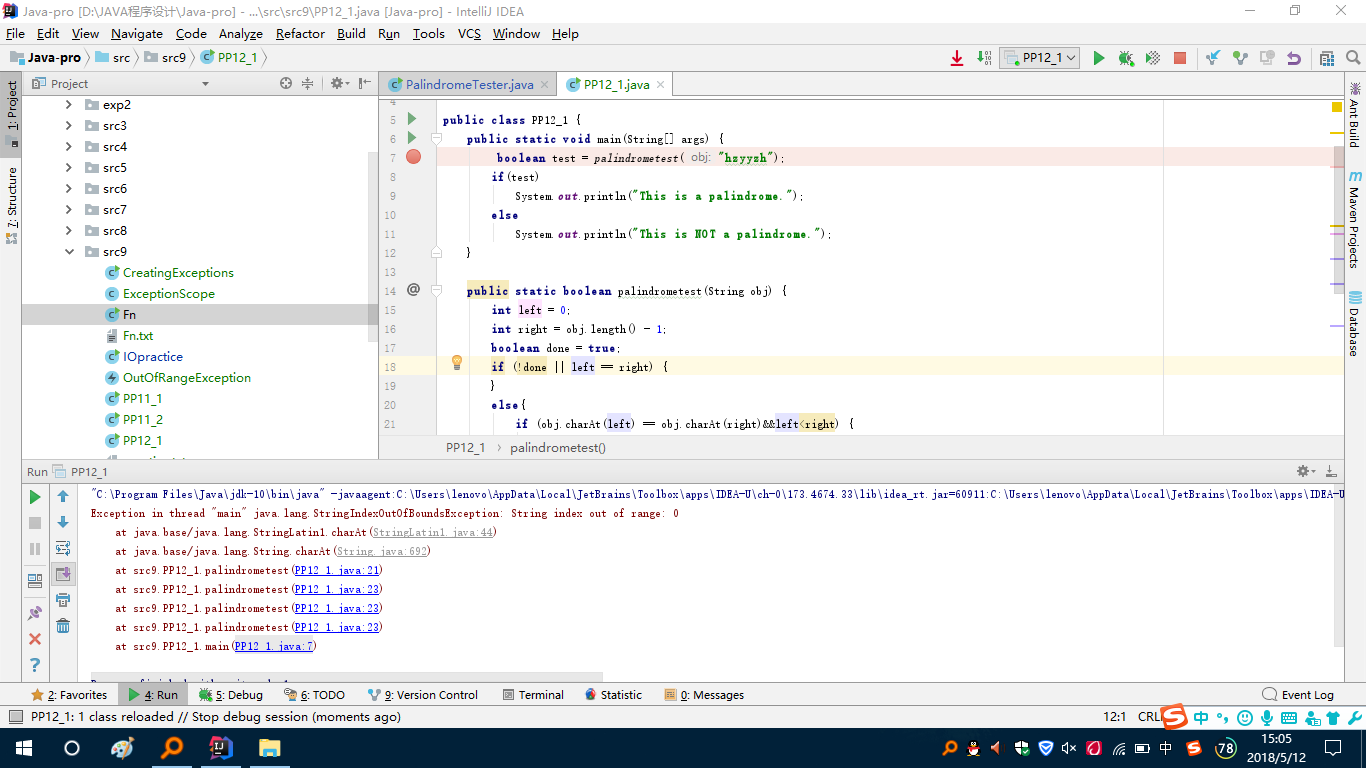
- 问题1解决方案:一开始看递归,比较乱一些,这个题目一开始有的思路就是从两端来开始读取,读取第一个字符和最后一个字符,进行比较,再使用String类的substring方法将去掉首和尾字符的字符串进行递归,这样就可以完成程序编写。但一直卡着的地方是到底要它怎么才能结束递归,也就是基本情况怎么设置,这里想不明白,就导致了第一次的无输出,然后又在草稿纸上重新想了一遍整个程序设计的过程(这个步骤在一开始没有做,因为感觉很复杂,就想在过程遇到了再去重新想),这样就浪费了一些时间,但其实也觉得一开始做整个程序设计又不知道从哪入手。完成之后,再次运行,出现了第二个问题:抛出异常。选择了三个字符最简单的就进入了Debug调试。
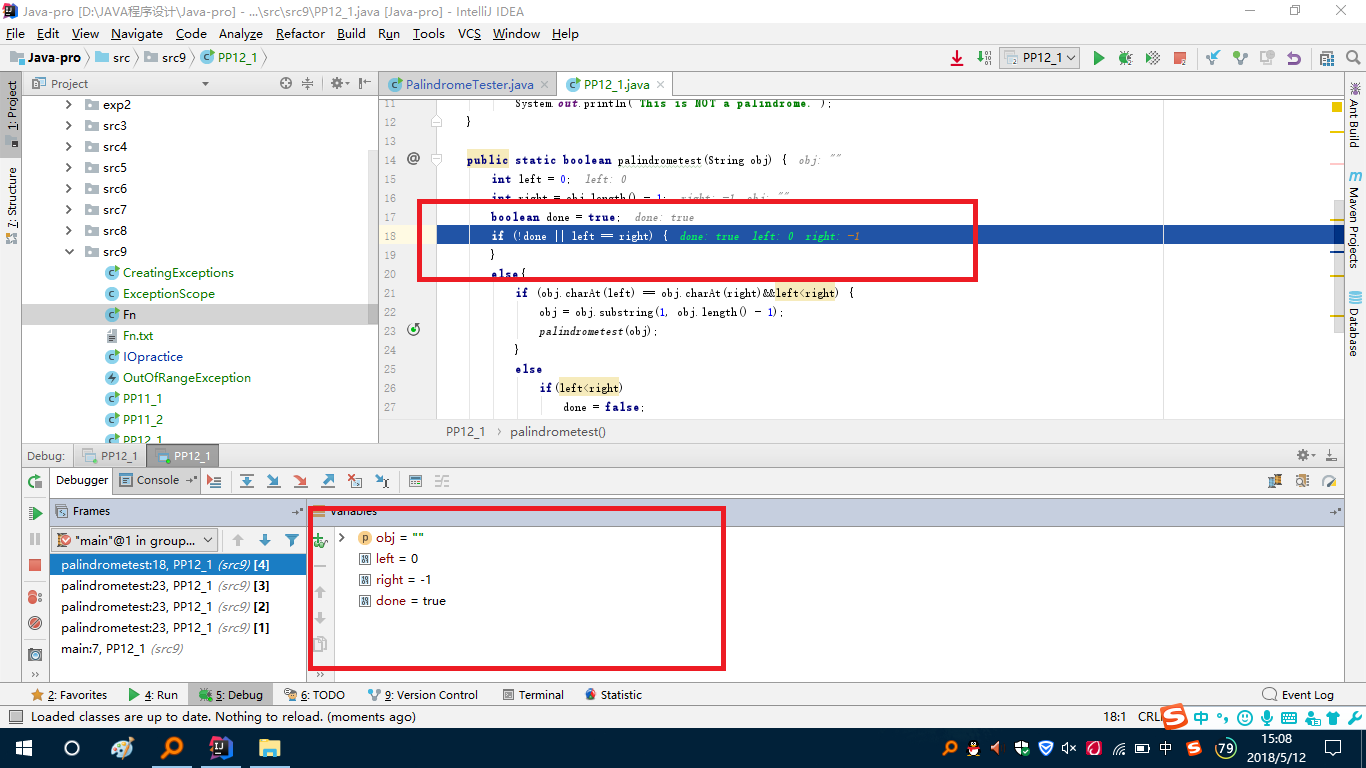
可以看到这里比较到最后,right代表字符串的最后的索引值,right成了-1,这里也就是存在问题的地方,因为我一开始设置的条件是当left>right时程序会进入基本情况,这里就是有问题,当他们两个值相等时就应该进入基本情况,而不是再去进入递归,这样修改一下,就完成了这个方法的编写,这个方法最后的代码见下:
public static boolean palindrometest(String obj) {
int left = 0;
int right = obj.length() - 1;
boolean done = true;
if (!done || left >=right) { }
else{
if (obj.charAt(left) == obj.charAt(right)&&left<right) {
obj = obj.substring(1, obj.length() - 1);
palindrometest(obj);
}
else
if(left<right)
done = false;
}
return done;
}
}
最后又对是回文的奇数个字符的、是回文的偶数个字符的和不是回文的进行了一次测试:
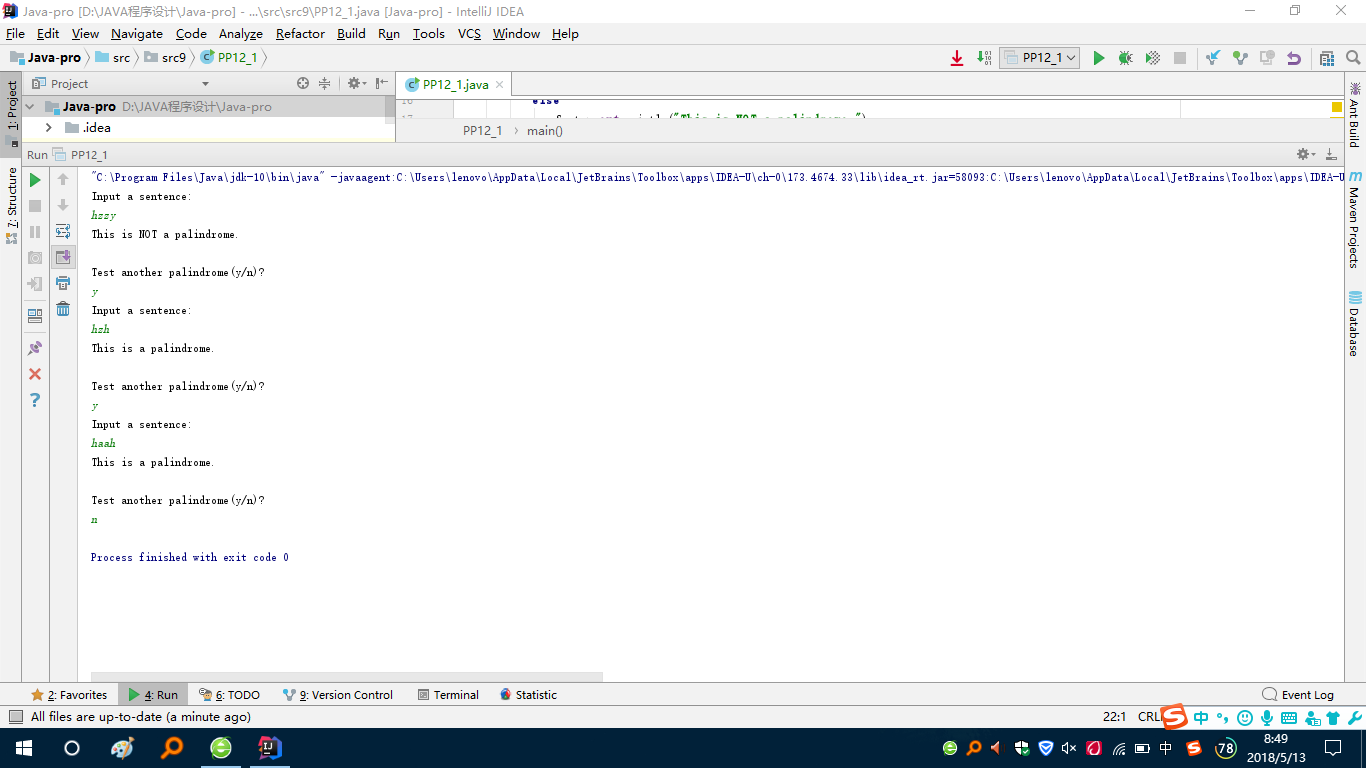
-
问题2:因为对递归的不太熟练,做PP12.9时也遇到了一点小问题,这里也是算是半猜着做完了,具体问题见下面:
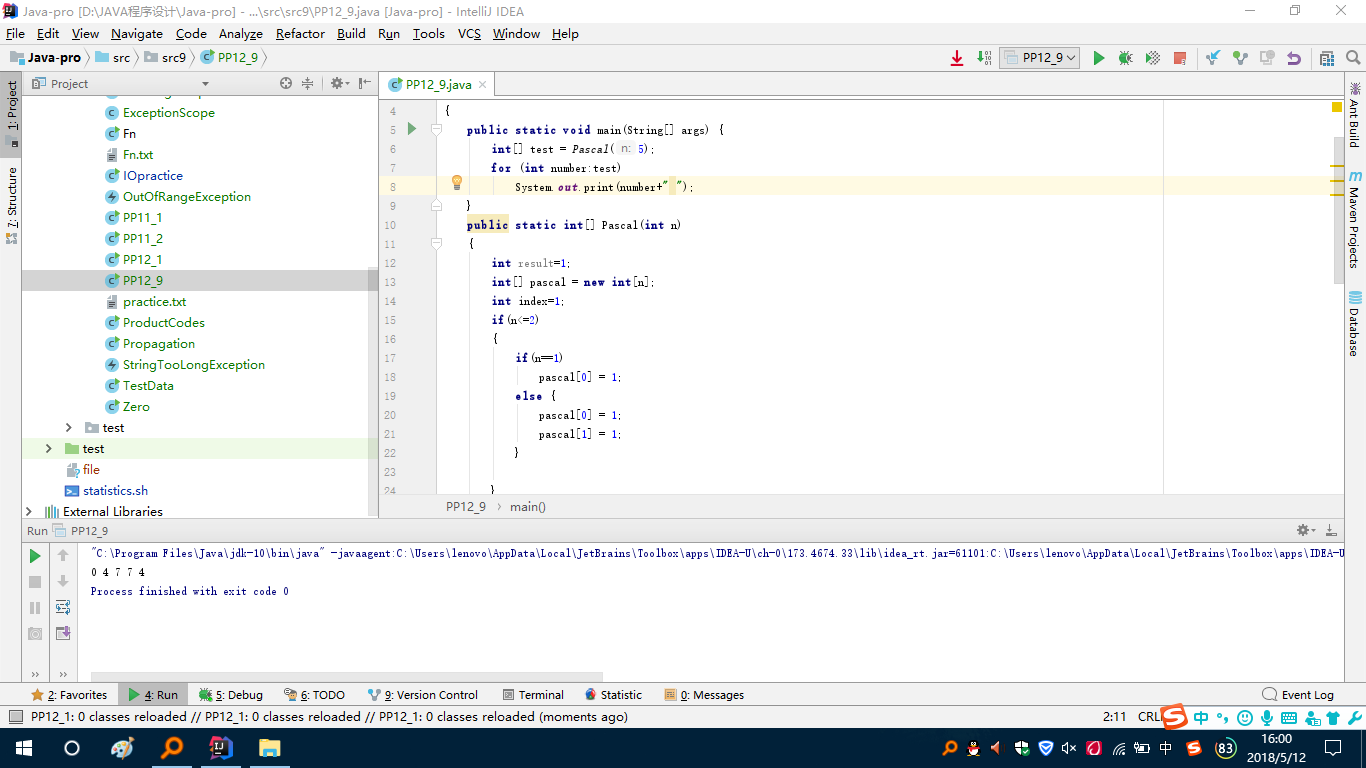
-
问题2解决方案:我要输出那个三角形的第5行时,输出结果与书上的不一致,后来又把自己的代码重新看了一遍,找到了问题,是一开始相加的那个每行的第一个和最后一个数为1这里给漏掉了,加上这个语句后就可以正常输出了,这是加在递归部分中循环之前的地方
pascal[0] = 1; pascal[n-1] = 1;。然后结果如下:
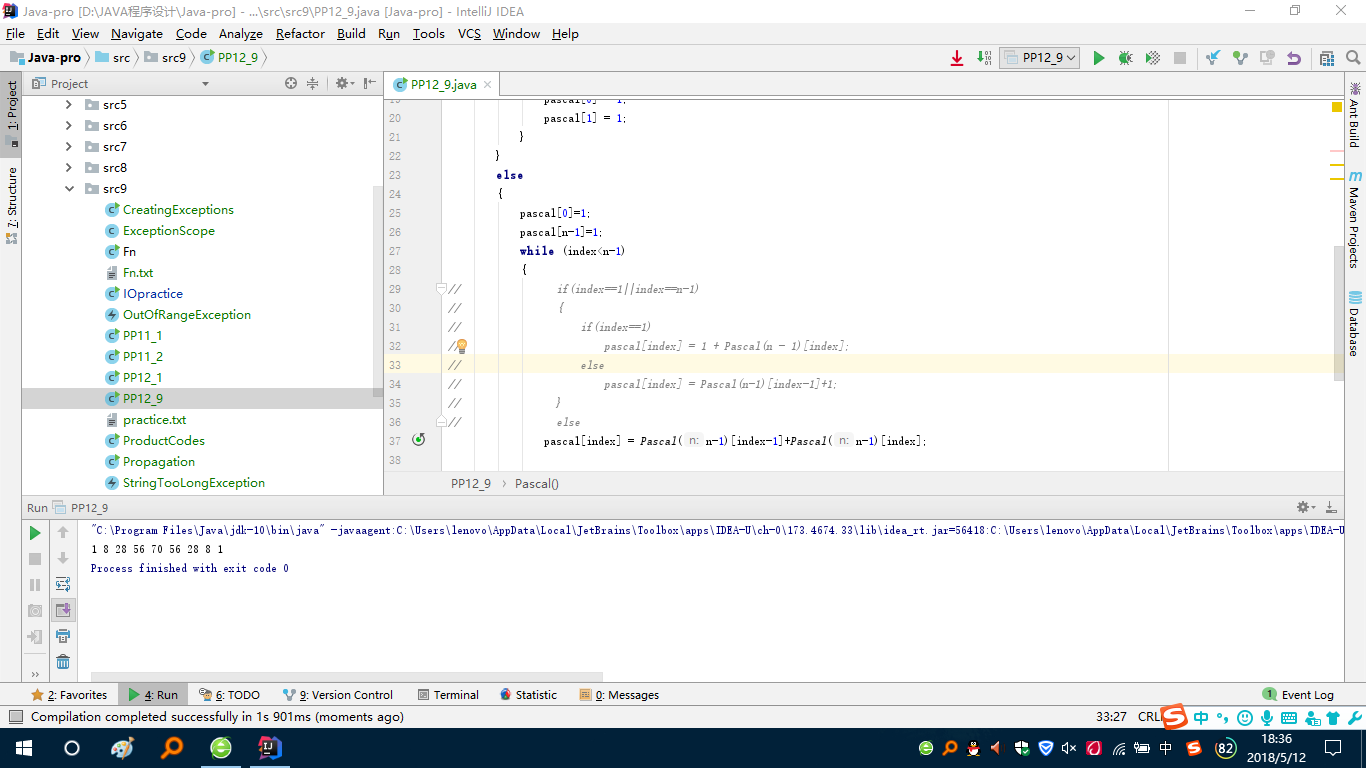
其中注释的部分一开始是有的,但后来又想到这个好像可以不加,我就把它改成了注释,试着运行了一下,发现也可以,就知道了之前的考虑是多余的,在循环之前放上那条语句就已经包含了后面我所考虑的部分,就是想多了,就把那一部分删掉了。后又发现代码多余:

这里n=2时其实是可以记做递归情况中的,基本情况是可以简写的,就把那部分注释掉,运行之后也是正常的,很多时候自己考虑的不清楚,往往就会代码写的很复杂,自己读起来都很吃力,要有一个完整的规划写起来才会简单而且高效。
- 后补:后询问余坤澎同学,这道题目要输出的是整个三角形,而非单行,就又弄了好久,通过一个二维数组,写了好些代码,实现了该功能,程序运行截图:
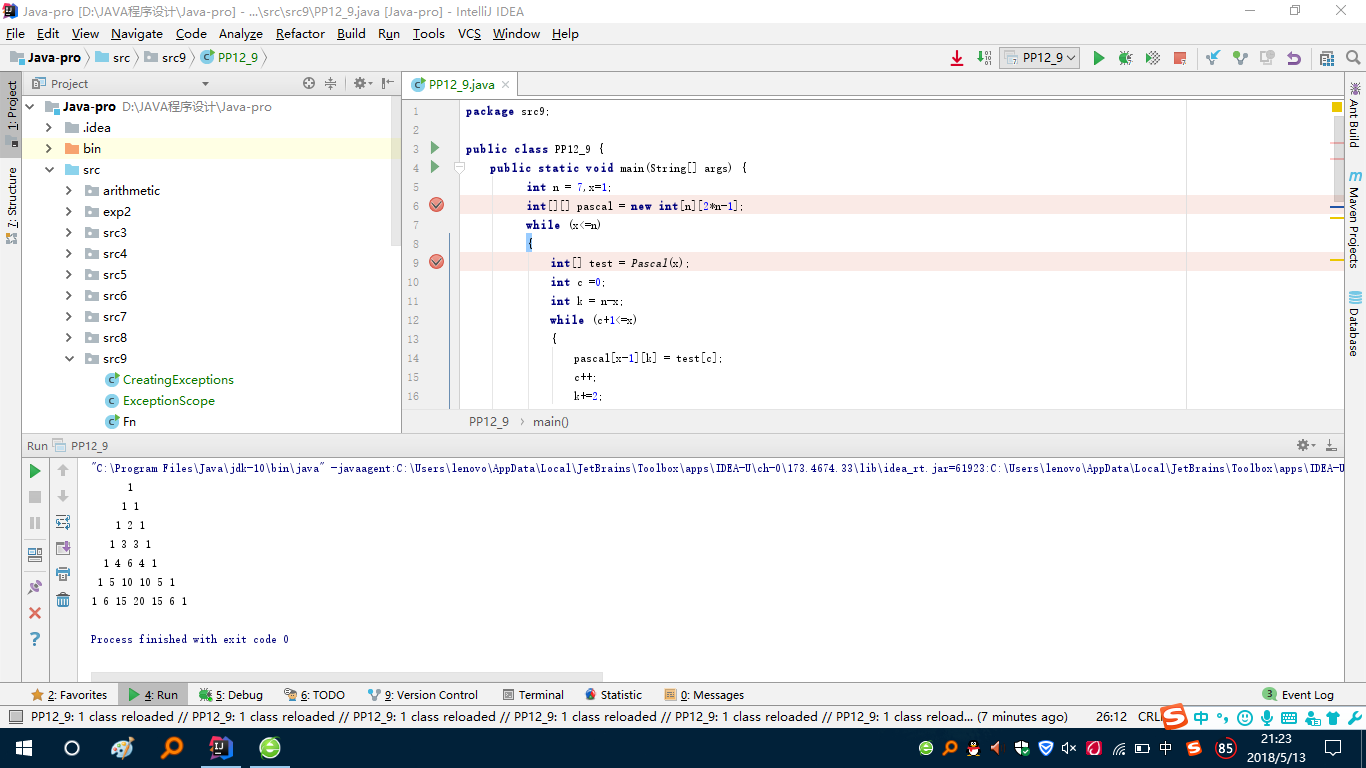
代码托管
上周考试错题总结
-
1.An exception can produce a "call stack trace" which lists
A . the active methods in the order that they were invoked
B . the active methods in the opposite order that they were invoked
C . the values of all instance data of the object where the exception was raised
D . the values of all instance data of the object where the exception was raised and all local variables and parameters of the method where the exception was raised
E . the name of the exception thrown -
解析:堆栈踪迹的显示其实也类似于我们所学的栈的显示,最后调用的方法将会放于栈顶,也就会是先打印出来,最先调用的将会在最后打印在屏幕上,这也就是原来调用顺序的反序。堆栈跟踪提供了储存在运行时堆栈中的方法的名称,方法名称在堆栈中以相反的顺序放置,也就是说,最早的方法是先放在这里,下一个方法其次,等等,所以最近调用的方法是在堆栈上最后一项,这是第一个。堆栈跟踪然后以相反的顺序显示所有活动的方法。
-
2.An exception that could also arise in the try statement that does not have an associated catch statement is
A . ClassNotFoundException
B . IllegalArgumentException
C . NegativeArraySizeException
D . NullPointException
E . OutOfMemoryException -
解析:如果数组还没有被实例化,那么可能就会抛出NullPointerException。ClassNotFoundException、IllegalArgumentException和OutOfMemoryException将不会被抛出,因为try语句中没有任何代码,它们要么引用某个未知的类,要么使用一个参数,要么处理新内存的生成。只有当实例化一个数组时,才有可能会出现NegativeArraySizeException。
-
3.The idea that an object can exist separate from the executing program that creates it is called
A . transience
B . static
C . persistence
D . serialization
E . finality -
解析:对象存储在内存中,当垃圾收集器不再被引用时,它们会被垃圾收集器回收。当Java程序终止时,没有引用对象,因此所有对象都被回收。然而,为了将来的使用,能够保存任何给定的对象是可取的。这种特性称为persistence,它的功能是将对象的实例数据保存到文件中。这可以通过将每个实例数据写入数据文件来完成,但是使用对象序列化简化了。
-
4.Character streams manage
A . byte-sized data
B . binary data
C . Unicode characters
D . ASCII characters
E . compressed data -
解析:字符流用于管理16位Unicode字符。这与用于管理任何字节大小数据的字节流不同,包括ASCII字符和其他类型的二进制数据。
Java中的字符流处理的最基本的单元是Unicode码元(大小2字节),它通常用来处理文本数据。所谓Unicode码元,也就是一个Unicode代码单元,范围是0x0000~0xFFFF。在以上范围内的每个数字都与一个字符相对应,Java中的String类型默认就把字符以Unicode规则编码而后存储在内存中。然而与存储在内存中不同,存储在磁盘上的数据通常有着各种各样的编码方式。使用不同的编码方式,相同的字符会有不同的二进制表示。
-
5.The term "exception propagation" means
A . an exception is caught by the first catch clause
B . an exception not caught by the first catch clause is caught by an outer (enclosing) catch clause
C . exceptions are caught, sequentially, by catch clauses in the current try block
D . exceptions always are caught by the outermost try block
E . none of the above -
解析:异常传递意味着一个异常被匹配的catch子句在当前try块级别,如果没有匹配,然后在下一个封闭try块级别,依次进行,直到异常已经被匹配的try语句或异常的main函数和被Java虚拟机捕获。
-
6.Assume infile is a BufferedReader for a textfile and that the textfile is empty. What is returned from the message infile.readLine( ); ?
A . 0
B . null
C . a special character known as the End-of-file marker (EOF)
D . none of the above, the message causes a NullPointerException to be thrown
E . none of the above, the message causes a EndOfFileException to be thrown -
解析:readLine()方法返回一个字符串,等于文件中的下一个文本项。如果文件为空文件的,则返回null。
-
7.A method that uses the Scanner class to obtain input does not require either catching or throwing an IOException. This is because
A . the Scanner class does not call upon any classes that throw checked exceptions
B . the Scanner class' methods call input methods in try statements and catch IOExceptions so that they are handled directly in the Scanner class
C . the Scanner class uses JOptionPane dialog boxes instead of java.io classes so that it does not have to deal with IOExceptions
D . the Scanner class overrides the class IOException making it an unchecked exception
E . none of the above, methods do require handling IOException even if thrown by a method in a Scanner class -
解析:通过拥有自己的catch(IOException.)catch语句,Scanner类中的任何代码都会被自己所捕获,这样一来,可以使用自己的异常处理,而不用处理这个可检测异常。
-
8.PrintWriter is a better output stream class that PrintStream because PrintWriter
A . has both print and println methods and PrintStream only has print
B . can output both byte and character streams and PrintStream can only output byte streams
C . has error checking mechanisms as part of the class and PrintStream does not
D . will not throw checked exceptions and PrintStream will
E . all of the above -
解析:PrintWriter类是一个Writer类,而PrintStream类是一个流类。主要的区别在于PrintWriter类是专门为文件读写而设计的,因此PrintWriter类有错误检查机制,而PrintStream则没有这个错误的检查机制。
-
9.Which statement is true about BufferedWriters
A . BufferedWriters are used because they improve runtime efficiency
B . BufferedWriters are used because they improve compile time efficiency
C . BufferedWriters can be used with input streams as well as with output streams
D . using a BufferedWriter obviates the necessity for catching IOExceptions
E . none of the above -
解析:作为提高程序执行效率的一种方法,BufferedWriters类允许累积输出,直到缓冲区达到满值,再去启动输出操作变得“有价值”,可以减少输出的次数,提高程序执行效率。
结对及互评
- 本周结对学习情况
-
博客中值得学习的或问题: 代码中遇到的问题记录的非常详细,而且这周也在向他学习着图片中使用红框标明错误出现地方,这里看起来很快能够抓到重点,不足的地方在于书上内容的总结还是不够详细。
-
结对学习内容:继续共同学习四则运算的编写。
点评过的同学博客和代码
其他(感悟、思考等)
感悟
- 本周学习了异常和递归两章内容,突然发现这本书就剩下一章了,学的速度好快,再往回想,感觉好多东西都还掌握的并不那么牢靠,仍然需要去练习实践。本周我觉得很有意思的内容是那个汉诺塔问题,高中时数学老师提过这个题目,没想到它是递归编程中经典的递归算法实例,这个很有意思,但是对于代码就没那么有意思了,看着看着就睡了,课下看了两遍才算是有些明白。还有就是本周编写的代码行数比较少一些,编程过程中遇到的问题并不多,还算顺利。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 157/157 | 1/1 | 15/15 | |
| 第二周 | 382/539 | 1/2 | 16/31 | |
| 第三周 | 317/856 | 2/4 | 15/46 | |
| 第四周 | 996/1852 | 1/5 | 24/70 | |
| 第五周 | 578/2330 | 1/6 | 16/86 | 这周对上周第七章的学习有了更深的理解 |
| 第六周 | 475/2805 | 1/7 | 14/100 | 学习了数组方面的相关知识 |
| 第七周 | 629/3434 | 1/8 | 14/114 | 关于继承有一定认识 |
| 第八周 | 1567/5001 | 3/11 | 25/141 | |
| 第九周 | 428/5429 | 2/13 | 17/158 | 了解了递归内容并学习了IO流相关知识 |