一、打开文件:文件句柄 = open('文件路径', '模式')
python中打开文件有两种方式,即:open(...) 和 file(...),本质上前者在内部会调用后者来进行文件操作,在这里我们推荐使用open,解释
二、操作文件
操作文件包括了文件的读、写和关闭,首先来谈谈打开方式:当我们执行 文件句柄 = open('文件路径', '模式')操作的时候,要传递给open方法一个表示模式的参数:
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,先写再读。【这个方法打开文件会清空原本文件中的所有内容,将新的内容写进去,之后也可读取已经写入的内容】
- a+,同a
"U"表示在读取时,可以将 自动转换成 (注意:只能与 r 或 r+ 模式同使用)
- rU
- r+U
- rbU
- rb+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
以下是file操作的源码解析:
 file Code
file Code针对上面源码中的个方法,可以具体看一下在实际操作中的用例:

obj1 = open('filetest.txt','w+')
obj1.write('I heard the echo, from the valleys and the heart
')
obj1.writelines(['Open to the lonely soul of sickle harvesting
',
'Repeat outrightly, but also repeat the well-being of
',
'Eventually swaying in the desert oasis'])
obj1.seek(0)
print obj1.readline()
print obj1.tell()
print obj1.readlines()
obj1.close()
我们以‘w+’的打开方式为例,write是向文件中写入一个字符串,而writelines是想文件中写入一个字符串数组。seek(0)方法是将指针指向其实位置,因为在写的过程中,指针的标记是随着写入的内容不断后移的,seek方法可以将指针移动到指定位置,而这个时候就指向0位置,从这个位置开始读,就可以读到刚刚写入的所有内容了;readline()是从指针位置读取一行,所以在这里,执行readline会将刚刚写入文件中的第一行读取出来;tell是指出指针当前的位置,这个时候执行tell()方法,指针指向了第二行的起始位置;之后的readlines方法,则会将文件当前指针之后的剩余内容按行读入数组中。下图是程序执行后文件和控制台的结果:
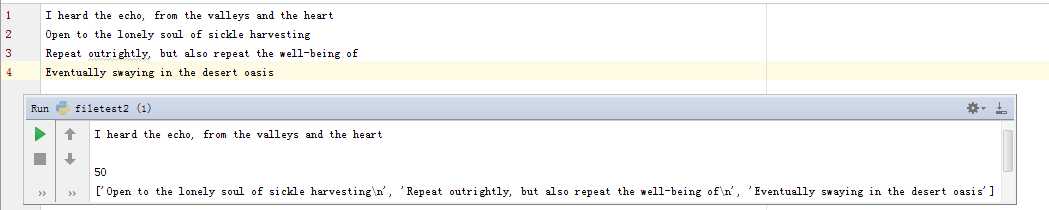
尽管刚刚使用'w+'的方式打开文件,但是事实上这种打开方式在文件处理中并不常用,曾一度被我们老师评为‘无意义’,因为用‘w+’方法会清空原文件里所有的东西~
上面一口气介绍了那么多方法,让我们有了一个笼统的概念,接下来把这些方法们各功能拿出来对比下:
写文件操作
write,writelines,相比于那些五花八门的读方法,写方法就单纯的多了,只有wite和writelines两种。看下面的例子和写入的结果,其实write方法和writelines方法都差不多,只不过一个接受的参数是list格式,一个接受的参数是字符串格式而已。这里使用的时候要注意换行符。
1 obj1 = open('E:PythonL\11-8\filetest.txt','r')
2 obj1 = open('filetest.txt','w+')
3 obj1.write('I heard the echo, from the valleys and the heart
Open to the lonely soul of sickle harvesting
')
4 obj1.writelines([
5 'Repeat outrightly, but also repeat the well-being of
',
6 'Eventually swaying in the desert oasis'
7 ])
刚刚我们使用write和writelines方法向文件里写入了泰戈尔的一段小诗,结果如下:
I heard the echo, from the valleys and the heart Open to the lonely soul of sickle harvesting Repeat outrightly, but also repeat the well-being of Eventually swaying in the desert oasis
读文件操作
我们以上面这个文件为例,来说说读文件:
首先来看一下直接读取文件中所有内容的方法read和readlines,从下面的结果来看就知道这两种方法一个返回列表,一个是返回字符串,和上面的write方法相对应:
1 #readline方法
2 obj1 = open('E:PythonL\11-8\filetest.txt','r')
3 print 'readlines:',obj1.readlines()5 #readline方法
6 print "read:",obj1.read()
readlines result View Codereadlines和read方法虽然简便好用,但是如果这个文件很庞大,那么一次性读入内存就降低了程序的性能,这个时候我们就需要一行一行的读取文件来降低内存的使用率了。
readline,next,xreadlines:用来按行读取文件,其中需要仔细看xreadlines的用法,因为xreadlines返回的是一个迭代器,并不会直接返回某一行的内容
需要注意的是,尽管我把这一大坨代码放在一起展示,但是要是真的把这一大堆东西放在一起执行,就会报错(ValueError: Mixing iteration and read methods would lose data),具体的原因下面会进行解释。
1 obj1 = open('E:PythonL\11-8\filetest.txt','r')
2 #readline方法
3 print "readline:",obj1.readline()
5 #readline方法
6 print "next:",obj1.next()
8 #readline方法
9 r = obj1.xreadlines()
10 print 'xreadlines:',r.next()
12 #readline方法
13 print 'readlines:',obj1.readlines()
15 #readline方法
16 print "read:",obj1.read()
先展示一下执行上面这些程序的结果好了:
左侧是代码,右侧是相应的执行结果。这里先展示readline,next,xreadlines这三个方法。
read result这里要补充一点,xreadlines方法在python3.0以后就被弃用了,它被for语句直接遍历渐渐取代了:
1 obj1 = open('filetest.txt','r')
2 for line in obj1:
3 print line
4
5 运行结果:
6 I heard the echo, from the valleys and the heart
7
8 Open to the lonely soul of sickle harvesting
9
10 Repeat outrightly, but also repeat the well-being of
11
12 Eventually swaying in the desert oasis
文件中的指针
看完了文件的读写,文件的基本操作我们就解决了,下面介绍文件处理中和指针相关的一些方法: seek,tell,truncate
1 obj1 = open('filetest.txt','w+')
2 obj1.write('I heard the echo, from the valleys and the heart
'
3 'Open to the lonely soul of sickle harvesting
')
4 print '1.tell:',obj1.tell()
5 obj1.writelines([
6 'Repeat outrightly, but also repeat the well-being of
',
7 'Eventually swaying in the desert oasis'
8 ])
9 print '2.tell:',obj1.tell()
首先看tell,tell的作用是指出当前指针所在的位置。无论对文件的读或者写,都是依赖于指针的位置,我们从指针的位置开始读,也从指针的位置开始写。我们还是写入之前的内容,在中间打印一下tell的结果。执行代码后结果如下:
1.tell: 96 2.tell: 188
接下来再看一下seek的使用:
1 obj1 = open('E:PythonL\11-8\filetest.txt','r')
2 print "next:",obj1.next(),'tell1:',obj1.tell(),'
'
3 obj1.seek(50)
4 print "read:",obj1.read(),'tell2:',obj1.tell(),'
'
seek use从显示的执行结果来看这个问题,我们在使用next读取文件的时候,使用了tell方法,这个时候返回的是188,指针已经指向了tell的结尾(具体原因在下面解释),那么我们执行read方法,就读不到内容了,这个时候我们使用seek方法将指针指向50这个位置,再使用中read方法,就可以把剩下的内容读取出来。
在看一个关于truncate的例子:
1 obj1 = open('filetest.txt','r+')
2
3 obj1.write('this is a truncate test,***')
4 obj1.seek(0)
5 print 'first read:
',obj1.read()
6
7 obj1.seek(0)
8 obj1.write('this is a truncate test')
9 obj1.truncate()
10 obj1.seek(0)
11 print '
second read:
',obj1.read()
truncate result有上面的打印结果我们可以知道,在文件进行写操作的时候,会根据指针的位置直接覆盖相应的内容,但是很多时候我们修改完文件之后,后面的东西就不想保留了,这个时候我们使用truncate方法,文件就仅保存当前指针位置之前的内容。我们同样可以使用truncate(n)来保存n之前的内容,n表示指针位置。
with操作文件
为了避免打开文件后忘记关闭,可以通过管理上下文,即:with open('文件路径','操作方式') as 文件句柄:
1 #使用whith打开可以不用close
2 with open('E:PythonL\filetest.txt','r') as file_obj:
3 file_obj.write('')
4
5 #在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,下例为同时打开两个文件
6 #with open('E:PythonL\filetest1.txt','r') as file_obj1,open('E:PythonL\filetest2.txt','w') as file_obj2:'''
容易犯的错误:
ValueError: Mixing iteration and read methods would lose data
我在操作文件的过程中遇到过这样一个问题,从字面上来看是说指针错误,那么这种问题是怎么产生的呢?我发现在使用next或者xreadlines方法之后再使用read或readlines方法就会出现这种错误,原因是next或者xreadlines包括我们平时常用的for循环读取文件的方式,程序都是在自己内部维护了一个指针(这也解释了我们使用这些方法的时候再用tell方法拿到的指针都是指向了的文件末尾,而不是当前独到的位置),所以如果我们要先使用上述的next或者xreadlines方法读取一行,然后再用read或readlines方法将剩余的内容读到就会报错。
解决方案:
这个时候有两种解决方案:
第一种,在读取一行后,用seek指定指针的位置,就可以继续使用其他方法了
第二种,使用readline方法,这个方法没有内部维护的指针,它就是辣么单纯的一行一行傻傻的读,指针也就傻傻的一行一行往下移动。这个时候你也可以使用tell方法追踪到指针的正确位置,也可以使用seek方法定位到想定位的地方,配合truncate,wirte等方法,简直不能更好用一些。