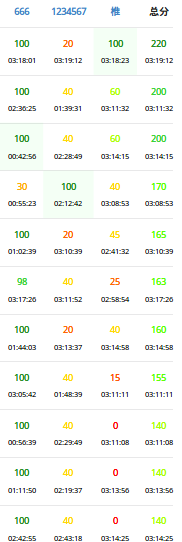

稍垃圾。因为T1没A。
赶巧前一段时间学了杜教筛,结果因为教练放错题。
然后考场上疯狂yy,最后水到了一个AC。
其实的确挺不公平的,不少人也没学呢。
如果只算T1和T3的分数的话,那70分就是个垃圾。
还有。。。。

又一次盖掉自己70分。。。
想剪枝结果打错了。
在没有用堆跑Dijk时因为队列里的元素无序所以一个点可能被扩展多次,而有时候后扩展的状态更优,所以不能打标记continue。
其余其实还好,发挥的凑和吧。其实能yy出T2还是挺不容易的。
但是当然在正经考试里不会出现你学过别人没学过的知识点,所以不必窃喜。。。
T1:666
最优决策的形式一定是复制并连粘几遍,再删除几次,循环。
也就是用n的费用×n,用1的费用-1。
跑最短路,因为边权不大所以没必要开堆。
打表发现,乘的形式只有2357是有效的,所以只有5种转移。


1 #include<cstdio> 2 #include<cstring> 3 #include<iostream> 4 using namespace std; 5 int dp[1000001],q[10000005]; 6 #define maxn 1000000 7 int main(){ 8 memset(dp,30,sizeof dp); 9 dp[1]=0;q[1]=1; 10 for(int h=1,t=1;h<=t;++h){ 11 int a=q[h]; 12 if(a*2<=maxn&&dp[a*2]>dp[a]+2)dp[a*2]=dp[a]+2,q[++t]=a*2; 13 if(a*3<=maxn&&dp[a*3]>dp[a]+3)dp[a*3]=dp[a]+3,q[++t]=a*3; 14 if(a*5<=maxn&&dp[a*5]>dp[a]+5)dp[a*5]=dp[a]+5,q[++t]=a*5; 15 if(a*7<=maxn&&dp[a*7]>dp[a]+7)dp[a*7]=dp[a]+7,q[++t]=a*7; 16 if(a&&dp[a-1]>dp[a]+1)dp[a-1]=dp[a]+1,q[++t]=a-1; 17 } 18 int n;scanf("%d",&n);printf("%d ",dp[n]); 19 }
T2:123567
讲过无数遍的式子
$sumlimits_{i=1}^{sqrt{n}} mu(i) frac{n}{i^2}$
然后后面那个东西,一个是莫比乌斯函数可以用杜教筛弄前缀和,另一个看着像除法分块
只要设$d=i^2$就和普通的整除分块没有区别了
杜教筛筛莫比乌斯函数的式子是:
设$S_n=sumlimits_{i=1}^{n} mu(i)$
则$S_n= 1-sumlimits_{i=2}^{n} S_{frac{n}{i}}$
套一个整除分块就可以递归求解了。
线筛预处理3e7以内的$S_n$,然后剩下的继续杜教。
复杂度并不会证,总之可以接受。
做出了《奇怪的道路》的感觉。。。很久很久很久没有这种全场只有我自己A的题了,虽说不公平但是还是较开心,毕竟我越来越菜了
1 #include<cstdio> 2 #include<unordered_map> 3 #include<cmath> 4 using namespace std; 5 #define C 33333333 6 unordered_map<int,int>M; 7 int p[20000005],pc,miu[C+5];bool np[C+5]; 8 int sum_miu(int n){ 9 if(n<=C)return miu[n]; 10 if(M.find(n)!=M.end())return M[n]; 11 int ans=1; 12 for(int l=2,r;l<=n;l=r+1)r=n/(n/l),ans-=sum_miu(n/l)*(r-l+1ll); 13 return M[n]=ans; 14 } 15 int main(){miu[1]=1;//freopen("data","r",stdin); 16 for(int i=2;i<=C;++i){ 17 if(!np[i])p[++pc]=i,miu[i]=-1; 18 for(int j=1;j<=pc&&i*p[j]<=C;++j) 19 if(i%p[j])np[i*p[j]]=1,miu[i*p[j]]=-miu[i]; 20 else{np[i*p[j]]=1;break;} 21 } 22 for(int i=1;i<=C;++i)miu[i]+=miu[i-1]; 23 long long n,ans=0;scanf("%lld",&n); 24 for(long long l=1,r;l*l<=n;l=r+1)r=sqrt(n/(n/l/l)),ans+=(sum_miu(r)-sum_miu(l-1))*(n/l/l); 25 printf("%lld ",ans); 26 }
T3:椎
%%%mikufun %%%Dybala
mikufun:板子题
Dybala:这不很简单吗?
的确是板子,线段树维护区间单调栈之前就不是很理解。
但是就算做过了一边依然不感觉“很简单”啊。。。反正%%%就是了
有空最好再写一遍
其实差不多是照着板子抄下来的。。。但是这次确实理解了,就差再写一遍了
对于这道题,我们把它按照key拍到序列上。
然后每个点在树上的深度,就是从1到i不断加入w维护单调递减栈,再从max到i不断加入w维护另一个单调递减栈,两个单调栈的最终size和就是深度。
而求lca就是求序列上两个点之间w最大的那个点。
因为满足堆性质,所以w大的是祖先,w最大的就是lca啦(因为也满足二叉搜索树性质,所以在序列两点之间就代表两个点分别在左右子树里)
至于为什么是单调栈的size和,其实就是如果它在树里往上走有一条向左上的边那么右侧单调栈就会多一个元素,左侧同理。
具体含义的话画个图理解一下,对着样例%一%就出来了。
所以现在的问题就大概是,从1到i的单调栈有几个元素,支持插入,删除。
其实不必单独写删除操作,直接把那个点的w值设为0就完事了。
首先我们要查询最大值,因为要求lca。
但是线段树太大的话很麻烦。。。所以需要离线离散化,在离散化之后就可以用数组实现key和w之间的映射了,而不用map什么的。。。
这样的话我们本来要查询w最大值对应的key值,在线段树上需要返回pair还要维护一大堆东西。。。
离散化之后,因为题目保证key和w同一时刻均不重复,所以就可以通过最大值直接得到位置了。
%%%mikufun
但是重头戏显然不是区间查询最大值的啦。。。
怎么用线段树维护单调栈?
正向单调栈和逆向单调栈是完全一样的,下面只以正向为例。
函数askl(p,l,r,x)表示当前节点是p,(l,r)区间内的元素形成的单调栈在加入x元素进行弹栈之后单调栈里剩余的元素个数。
我们需要的就是ask(1,1,i,0),因为加入0什么影响都没有(0是最小的当然不会弹栈)
这个如何递归求解?
如果是叶节点,当然好说,只要叶节点的元素大于x就可以被留下。
否则的话,如果查询的区间完全包含了当前节点的区间:
如果右儿子的最大值小于x,那么在弹栈的时候右儿子的所有点都会被弹掉,没有贡献,答案就是左儿子的贡献,ask(p<<1,l,r,x),递归求解不用管
如果右儿子的最大值大于x,那么右儿子的最大值会被加入栈,它被加入的时候可能会弹掉左儿子的一部分,就是ask(p<<1,l,r,mx[p<<1|1])+ask(p<<1|1,l,r,x)--1
(不考虑等于的问题,因为本题保证不相同)
而我们可以发现,查询的第一项ask(p<<1,l,r,mx[p<<1|1])与询问的参数x完全无关,所以可以预处理出来存在数组里面。
再不然就只剩下一种情况了,那就是询问区间并没有包含当前节点的整个区间,那么就要像普通线段树一样递归求解了。
但是有一个地方类似于剪枝。就是说我们每次在查询完整的右儿子区间时(就是上面红色的--1标记那里),都保证了它的最大值mx[p<<1|1]被加入了栈里。
那么它就会把所有靠左的区间的小于mx[p<<1|1]的元素都弹掉。
这样的话我们在递归求解时就需要先查询右儿子来保证它把左边的该弹的都弹掉了。
所以我们维护一个全局变量mxr,每次查询完整右儿子及叶节点时(即--1处再加上叶节点的特判)都用区间最大值更新一下mxr。
然后你在询问完所有右儿子之后才会问到某一个左儿子,即保证了查询每一个区间之前,它右边的所有节点都已经考虑到了。
这样的话就能保证弹栈是正确的了。
那么询问区间不包含当前节点区间的情况下,答案就是(qr>mid?askl(rc,ql,qr,P,mid+1,cr):0)+(ql<=mid?askl(lc,ql,qr,mxr,cl,mid):0);
(粘的代码内语句,ql,qr表示询问区间,cl,cr表示节点控制区间,lc,rc是左右儿子,P就是上文中的x)
现在的问题就是所说的预处理了,其实不是预处理,而是在每次修改时线段树的update函数怎么写?
也就是在上面的定义一样,如果你预处理的那个数组叫做upl的话,那么只要这么更新:
upl[p]=askl(lc,cl,mid,mx[rc],cl,mid);
完事了。
然后维护 右边单调栈的话有些左右儿子关系需要翻转,不再赘述。
一个很棒的做法是,开两个线段树,把序列翻转,直接用相同的函数再跑一遍,这样写的会简单一些。(但我没这么写)%%LNC
然后就是码了。
细节较多,稍注意一下。
1 #include<cstdio> 2 #include<algorithm> 3 using namespace std; 4 #define S 6666666 5 #define mid (cl+cr>>1) 6 #define lc p<<1 7 #define rc p<<1|1 8 int mx[S],upl[S],upr[S],mxr,r[S],k[S],v[S],o[S],tp,MX,rw[S],rf[S]; 9 int askl(int p,int ql,int qr,int P=0,int cl=1,int cr=MX){ 10 if(p==1)P=mxr=rw[qr+1]; 11 if(cl==cr)return mxr=max(mxr,mx[p]),mx[p]>P; 12 if(ql<=cl&&cr<=qr) 13 if(mx[rc]<P)return askl(lc,ql,qr,P,cl,mid); 14 else { 15 int x=askl(rc,ql,qr,P,mid+1,cr)+upl[p]; 16 mxr=max(mxr,mx[p]);return x; 17 } 18 return (qr>mid?askl(rc,ql,qr,P,mid+1,cr):0)+(ql<=mid?askl(lc,ql,qr,mxr,cl,mid):0); 19 } 20 int askr(int p,int ql,int qr,int P=0,int cl=1,int cr=MX){ 21 if(p==1)P=mxr=rw[ql-1]; 22 if(cl==cr)return mxr=max(mxr,mx[p]),mx[p]>P; 23 if(ql<=cl&&cr<=qr) 24 if(mx[lc]<P)return askr(rc,ql,qr,P,mid+1,cr); 25 else { 26 int x=askr(lc,ql,qr,P,cl,mid)+upr[p]; 27 mxr=max(mxr,mx[p]);return x; 28 } 29 return (ql<=mid?askr(lc,ql,qr,P,cl,mid):0)+(qr>mid?askr(rc,ql,qr,mxr,mid+1,cr):0); 30 } 31 int askmx(int p,int ql,int qr,int cl=1,int cr=MX){ 32 if(ql<=cl&&cr<=qr)return mx[p]; 33 return max(ql<=mid?askmx(lc,ql,qr,cl,mid):0,qr>mid?askmx(rc,ql,qr,mid+1,cr):0); 34 } 35 void insert(int p,int pos,int w,int cl=1,int cr=MX){ 36 if(cl==cr)return mx[p]=w,(void)0; 37 if(pos<=mid)insert(lc,pos,w,cl,mid); 38 else insert(rc,pos,w,mid+1,cr); 39 mx[p]=max(mx[lc],mx[rc]); 40 upl[p]=askl(lc,cl,mid,mx[rc],cl,mid); 41 upr[p]=askr(rc,mid+1,cr,mx[lc],mid+1,cr); 42 } 43 int query(int l,int r){ 44 if(l>r)l^=r^=l^=r; 45 int lca=rf[askmx(1,l,r)]; 46 return askl(1,1,l-1)+askr(1,l+1,MX)+askl(1,1,r-1)+askr(1,r+1,MX)-2*(askl(1,1,lca-1)+askr(1,lca+1,MX)); 47 } 48 int main(){ 49 int n;scanf("%d",&n); 50 for(int i=1;i<=n;++i){ 51 scanf("%d",&o[i]); 52 if(o[i]==0)scanf("%d%d",&k[i],&v[i]),r[++tp]=k[i],r[++tp]=v[i]; 53 if(o[i]==1)scanf("%d",&k[i]); 54 if(o[i]==2)scanf("%d%d",&k[i],&v[i]); 55 } 56 sort(r+1,r+1+tp);MX=unique(r+1,r+1+tp)-r-1; 57 for(int i=1;i<=n;++i){ 58 k[i]=lower_bound(r+1,r+1+MX,k[i])-r; 59 v[i]=lower_bound(r+1,r+1+MX,v[i])-r; 60 if(o[i]==0)rw[k[i]]=v[i],rf[v[i]]=k[i],insert(1,k[i],v[i]); 61 if(o[i]==1)insert(1,k[i],0); 62 if(o[i]==2)printf("%d ",query(k[i],v[i])); 63 } 64 }