LZ开发的一个公司内部应用供查询HIVE数据使用。部署上线后总是会出现CPU偏高的情况,而且本地测试很难重现。之前出现几次都是通过直接重启后继续使用,因为是内部使用,重启一下也没有很大影响(当然,每次重启都是顺带改改BUG,添加一些监控,或者修改了一些参数)。
今天再次发生占用CPU偏高的情况(机器是16核的),跑了几天后出现占用到200-300CPU的情况,之后快速升高,占用到700-1000。随机对应用状态状态尽兴了检查。
首先看了GC情况,看是否在进行FGC。

(在CPU刚开始飙高的时候FGC的次数是0,上图9次定位完问题才截的图,之前的没有保留)
发现应用并没有在进行FGC,而是进行频繁的YGC。
YGC也存在异常,S1和S0区域都是从0直接跳到99%
观察堆大小装太发现Young区内存都是不断的从0到99,而Old区在慢慢递增,还未达到FGC的状态。但预计后续会不停的上涨,导致FGC频道,应用无法提供服务。
在发现YGC频繁之后大约3个小时,终于开始了频繁的FGC,Old区满。
以下是堆大小和FGC的情况:

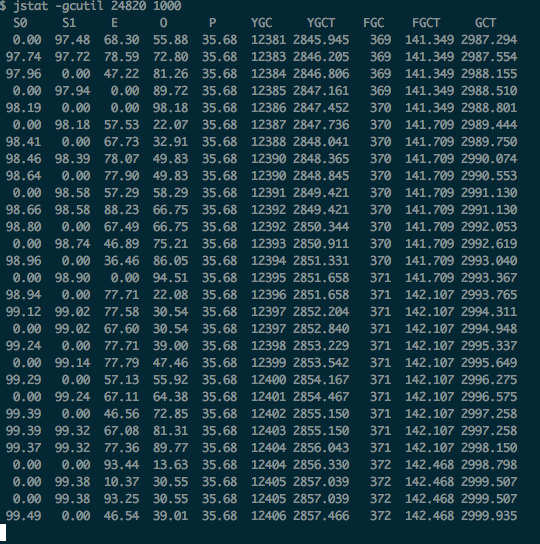
可以看到差不多10秒钟Old区就用满了导致一次FGC,而且Old区大小是10G(多么恐怖,10个G十来秒就用完了)
从内存和GC的角度只能看到YGC频繁导致了FGC频道(10秒一次)。但这样的情况应用还是能提供服务,只是占了较高的CPU(如果FGC在频繁一些应用应该是不能访问的)。
查完内存的状态确认并不是old区太小,被用满了导致了不停的FGC,因为old明显是够大的,如果10G不够,那应用肯定是有问题的。
之后去查了哪些线程占用了很高CPU(本应当在发现没有频繁FGC之后就入手查线程状态,经验不够)
查看进程的线程CPU使用情况:

拿到CPU占用较高的几个线程,转成16进制
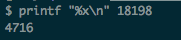
使用jstack看进程内的线程堆栈信息(jstack 24820 > abc.log)
vim编辑abc.log,查找上面获取到的线程的16进制数
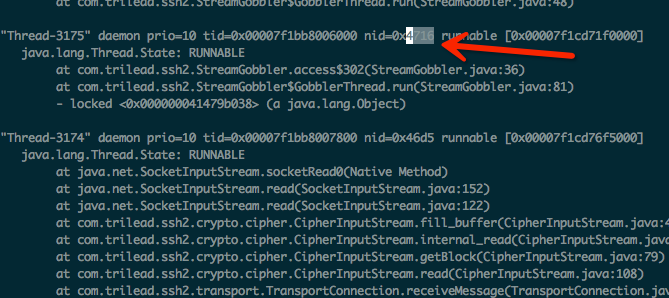
发现是使用了com.trilead.ssh2.StreamGobbler类的线程。这是一个ssh的第三方包。
后续查了其他CPU占用高的线程,除了GC占用,大部分都是SSH占用。
应用场景是每次使用HIVEQL进行查询的时候都会起一个线程,SSH到远程服务器,执行查询内容,返回结果。
如果有多个用户同时进行多个查询(一个用户也可以进行多次查询),就会出现多个线程多次SSH的情况。
后续处理的两个方案:
方案一,替换现有的第三方SSH工具,看有没有更好的
方案二,修改代码。考虑SSH后保持SESSION(查SSH SESSION的时效时间),统一账号,所有用户后台使用统一账号登录远程服务器执行查询。只使用一个SESSION,发现SESSION失效后进行一次重连。而不是每次查询都建一个登录一次获取session,用完后关闭,相信能减少SSH的引起的问题。
(PS:因为手头上还在进行其他项目,所以还是重启了应用先顶一阵,后面做完hive的权限控制,后台统一用户执行后优化SSH的处理)
OOM、CPU占用问题,JVM工具使用这些都是从菜鸟程序员不断提高要经历的,希望自己变的更好。
附JVM常用工具说明:http://my.oschina.net/feichexia/blog/196575