最近组内正在编写memcache的运维手册,围绕memcache运维在研读整理资料时发现有一块不可跳跃,那就是facebook几年前对于memcache的运维总结。
相关一手资料如下:
1 FaceBook工程师分享的视频 https://www.youtube.com/watch?v=6phA3IAcEJ8 [请FQ]
2 facebook PPT https://www.usenix.org/sites/default/files/conference/protected-files/nishtala_nsdi13_slides.pdf
3 facebook论文《Scaling Memcache At Facebook》 https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
下面围绕这些资料视频和论文做一下小结,正好为不习惯看英文的同学做摘要了。
为什么facebook有大规模scaling memcache的需要
facebook这种SNS的互联网产品特征:
1. Near real-time communication 实时沟通 (发布、回复、私信)
2. Aggregate content on-the-fly from multiple sources 聚合多个数据源的内容(头像,状态,图片等待)
3. Be able to access and update very popular shared content (热点明星的内容)
4. Scale to process millions of user requests per second (用户基数大 访问量高)
由此特征带来的技术需求是:
Support a very heavy read load (读请求远大于写请求---缓存)
• Over 1 billion reads / second
• Insulate backend services from high read rates
Geographically Distributed (地理分割)
Support a constantly evolving product (持续集成和发布)
• System must be flexible enough to support a variety of use cases
• Support rapid deployment of new features
Persistence handled outside the system (一致性要求)
• Support mechanisms to refill after updates
基于以上facebook的产品特性和技术要求,facebook选择了memcache并且有了Scaling Memcache的需求
白下说:其实facebook的缓存需求代表了广大SNS产品缓存特点,相似的产品需求比如UGC较多的微博、云音乐等读场景大于写场景的。
不过提到memcache就不能忽视掉redis 豌豆荚就选择了codis(Proxy based Redis cluster solution supporting pipeline and scaling dynamically)来解决可动态扩展的大规模缓存。
后面会不可缺少的分享redis相关的缓存解决方案,其实谈到缓存,在聚焦于选择memcache还是redis之后,运维或者架构师应该思考这样一个问题;“如何打造维护一个可动态扩展的大规模缓存集群” 本篇文章可以看到facebook在几年前对这个方面的探讨和实践。
memcache 常规的使用姿势:
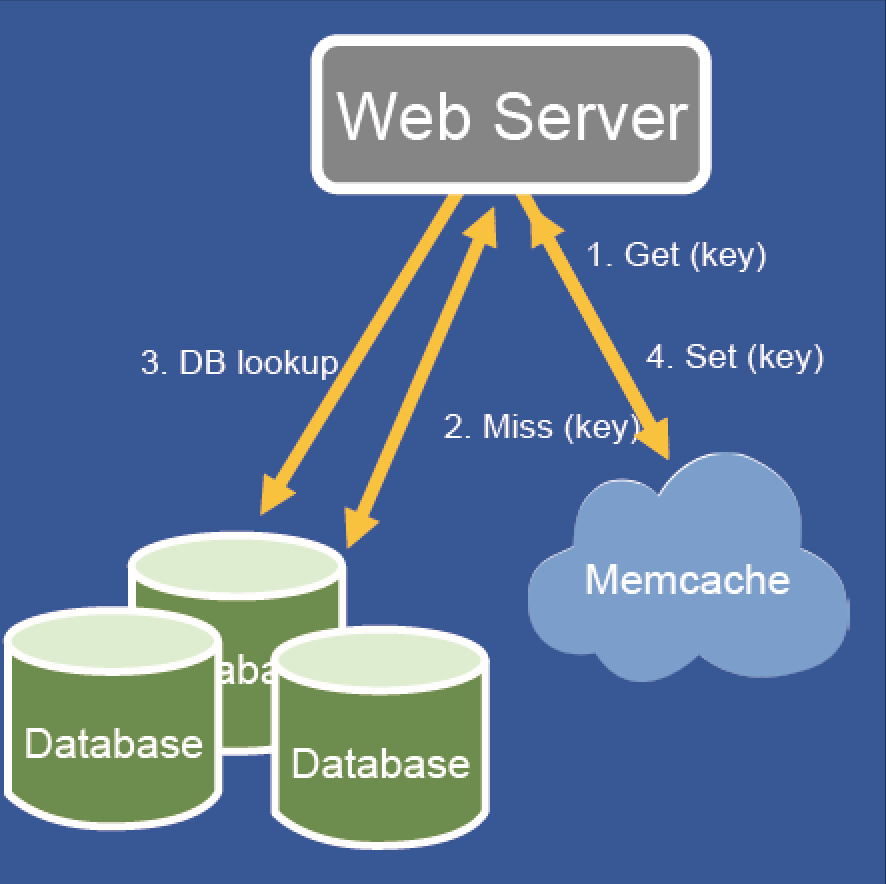
姿势1:读:读取如果miss回源数据库然后set
姿势2:写:更新数据库然后删除缓存
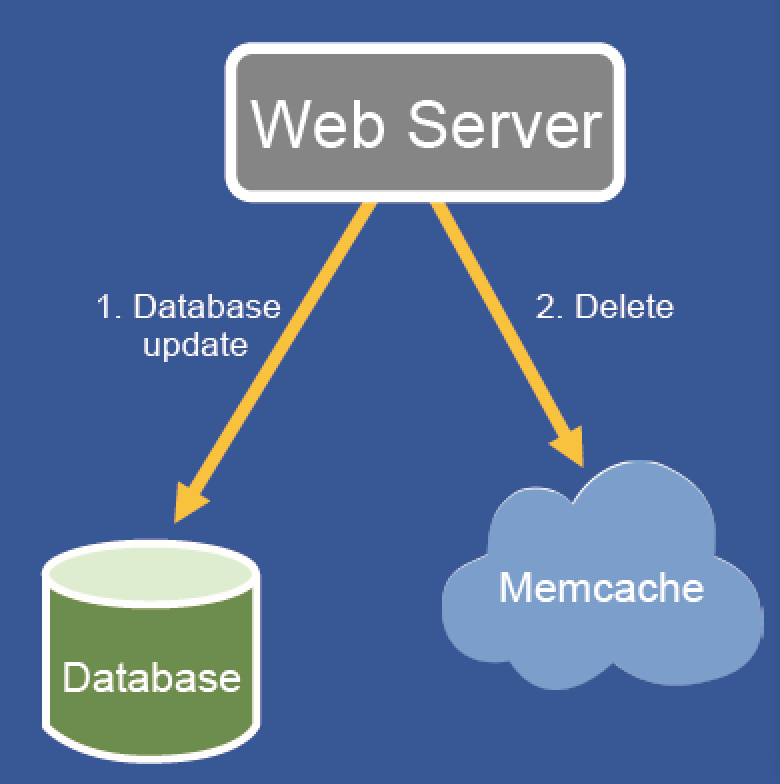
注:为什么用删除而不是set来解决数据更新
考虑到delete比set有更好的幂等性和
问题1:存在stale sets(脏写)的可能

webA webB 是两个前端 同事操作一个缓存对象 MC 缓存对象对应的数据库内容是DB
webA 操作数据库设置为DB_A
webB 操作数据库设置为DB_B
webB 操作缓存设置为MC_B
webA 操作缓存设置为MC_A
这是你会发现,DB的内容是DB_B MC的内容是MC_A 数据库缓存不一致了
这个问题怎么解决,论文里面有写,但是我这边看应该就是开启memcache CAS的功能就解决了。
问题2 存在 Thundering Herds(惊群效应)缓存雪崩
通俗来说就是缓存雪崩,当某个热键失效的时候,所有缓存按照姿势1的策略都会回源,这就造成数据库压力瞬间极大,严重的可能压垮数据库。
facebook给出的策略:
Clients given a choice of using a slightly stale value or waiting 就是要买使用过期的内容,要么等一会儿。
这篇博客也做了一些探讨 [http://www.php.cn/php-weizijiaocheng-89275.html]
白下说:如何避免
1:加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。(用ZK做分布式锁)这是一个限制数据库访问的应用层解决的通用方式。2:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。3:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期(此点为补充)。多级缓存可以存在策略4: 对于热键进行打散处理比如一key_001 key_002来区分等。
问题3:incast congestion
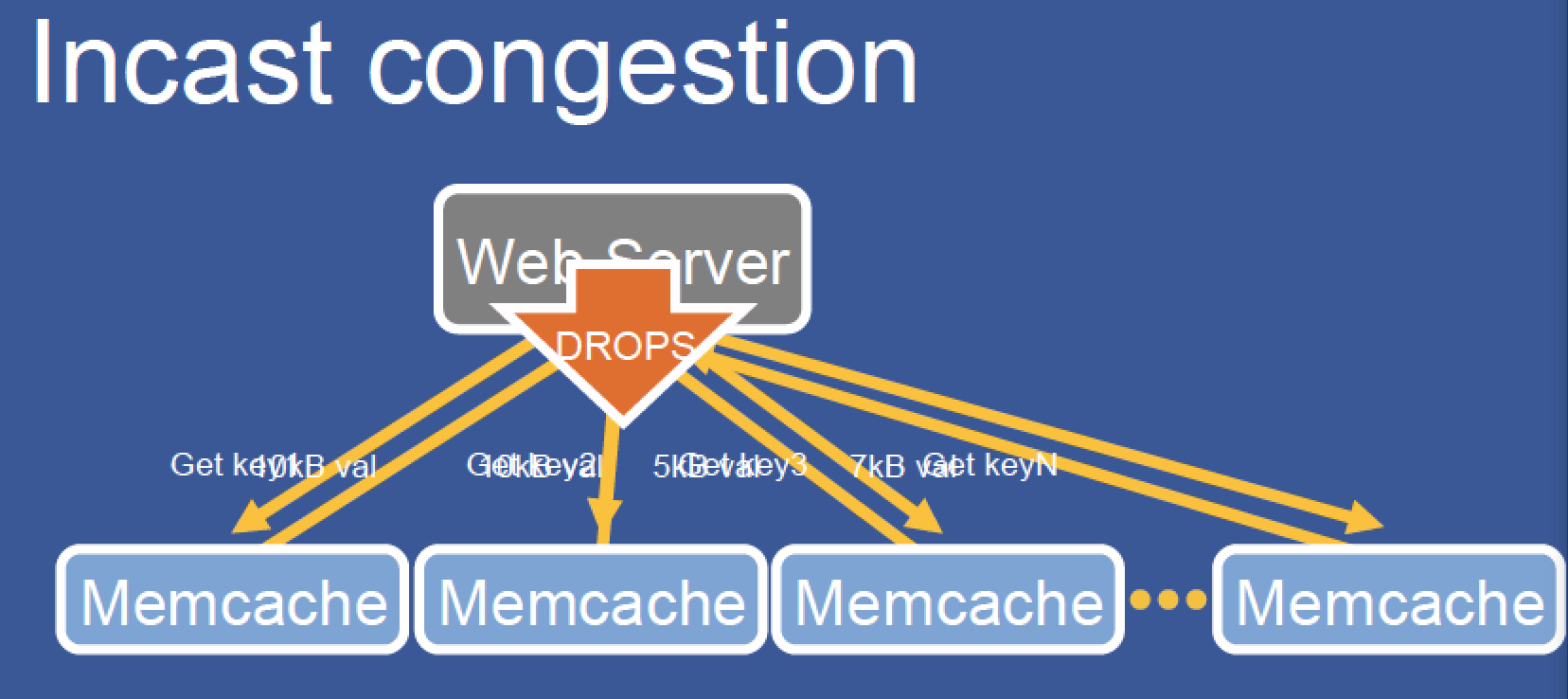
这个问题就是webserver一次性读取很多memcache的内容,同一时间返回把网口撑爆了或者产生丢包了。
解决策略:facebook是引入类似TCP的滑动窗口的机制来解决的。笔者认为一些较好的memcahce的客户端应该有解决方案。
问题4 scaling问题
以上对于小规模的场景没问题,但是如果规模扩大了,比如缓存集群多了,数据库也多了,那么给管理带来了问题,尤其是fb这个规模的缓存
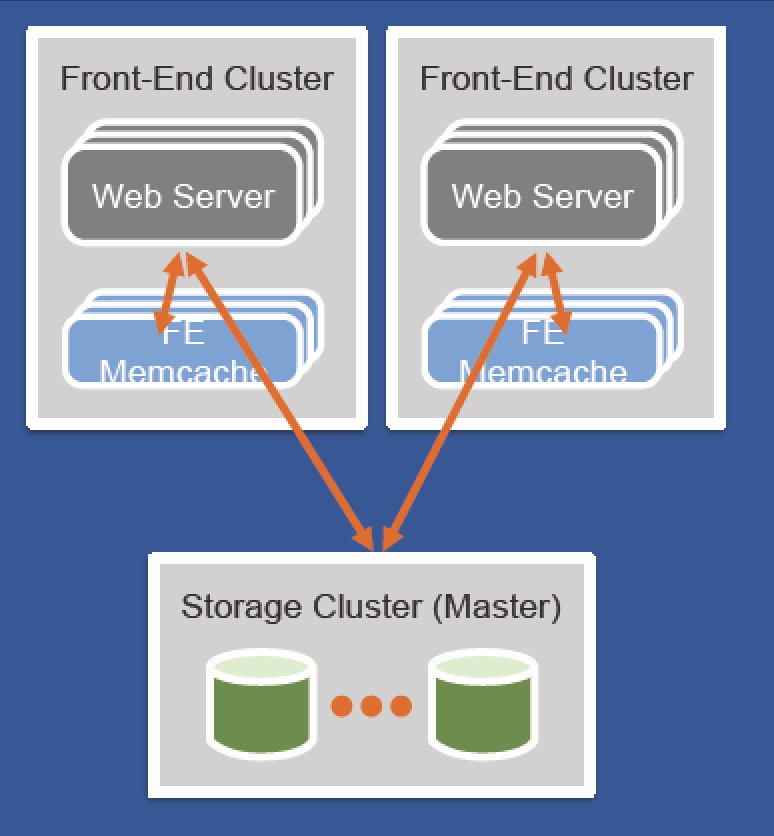
解决方案:
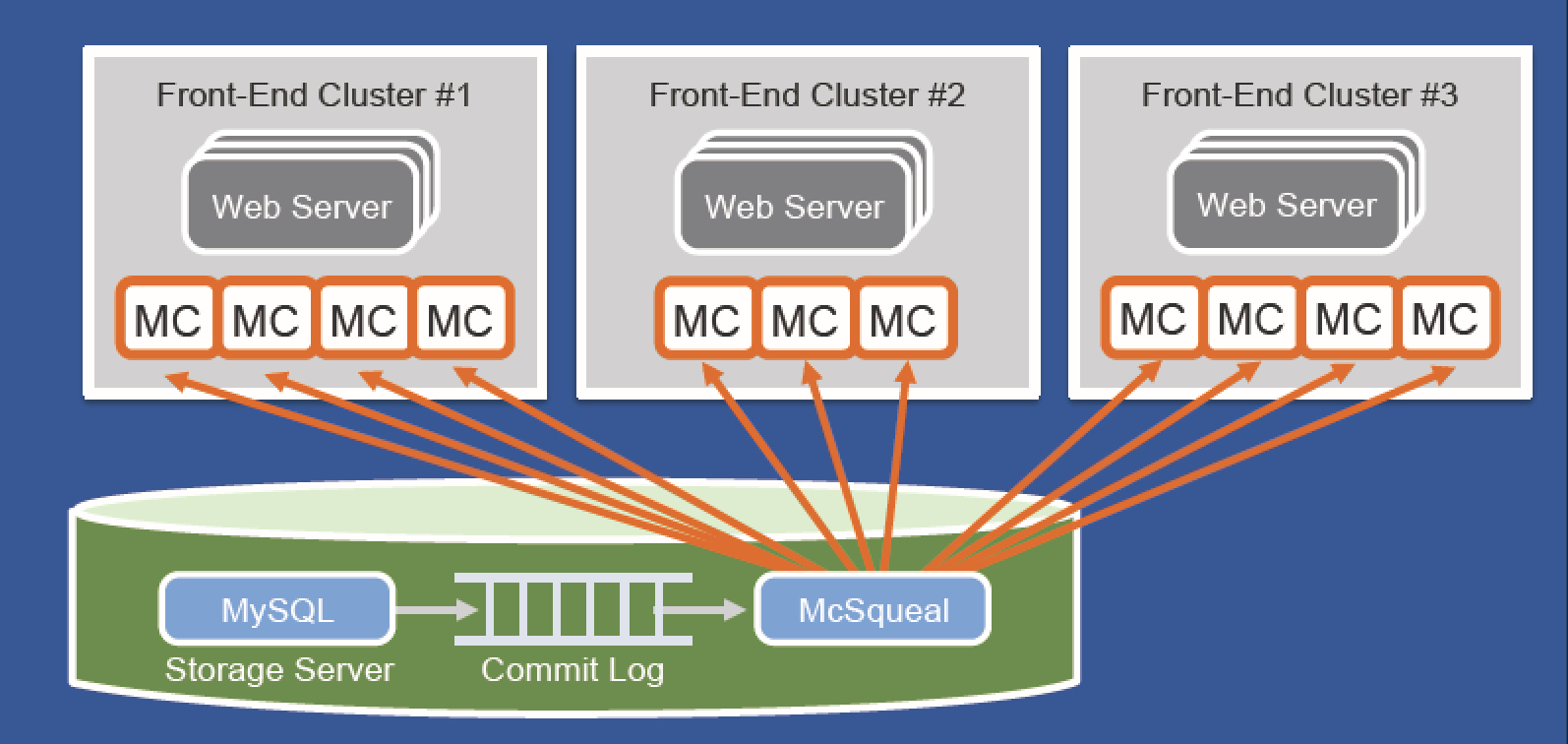
Cached data must be invalidated after database updates
• Solution: Tail the mysql commit log and issue deletes basedon transactions that have been committed
• Allows caches to be resynchronized in the event of a problem
Facebook 内部使用率mcsqueal这个组件用来根据commitlog来失效缓存。
白下说:
在网易也通过类似的方式对缓存进行同步,我们的组件叫做NDC,当然对外不开源了。其实就是订阅commitLog然后投放到kafka 有相关程序消费kafka日志然后同步缓存。
开源的话阿里开源了otter组件,笔者YY可以通过otter的相关commitlog同步来实现相关需求。
跨中心同步
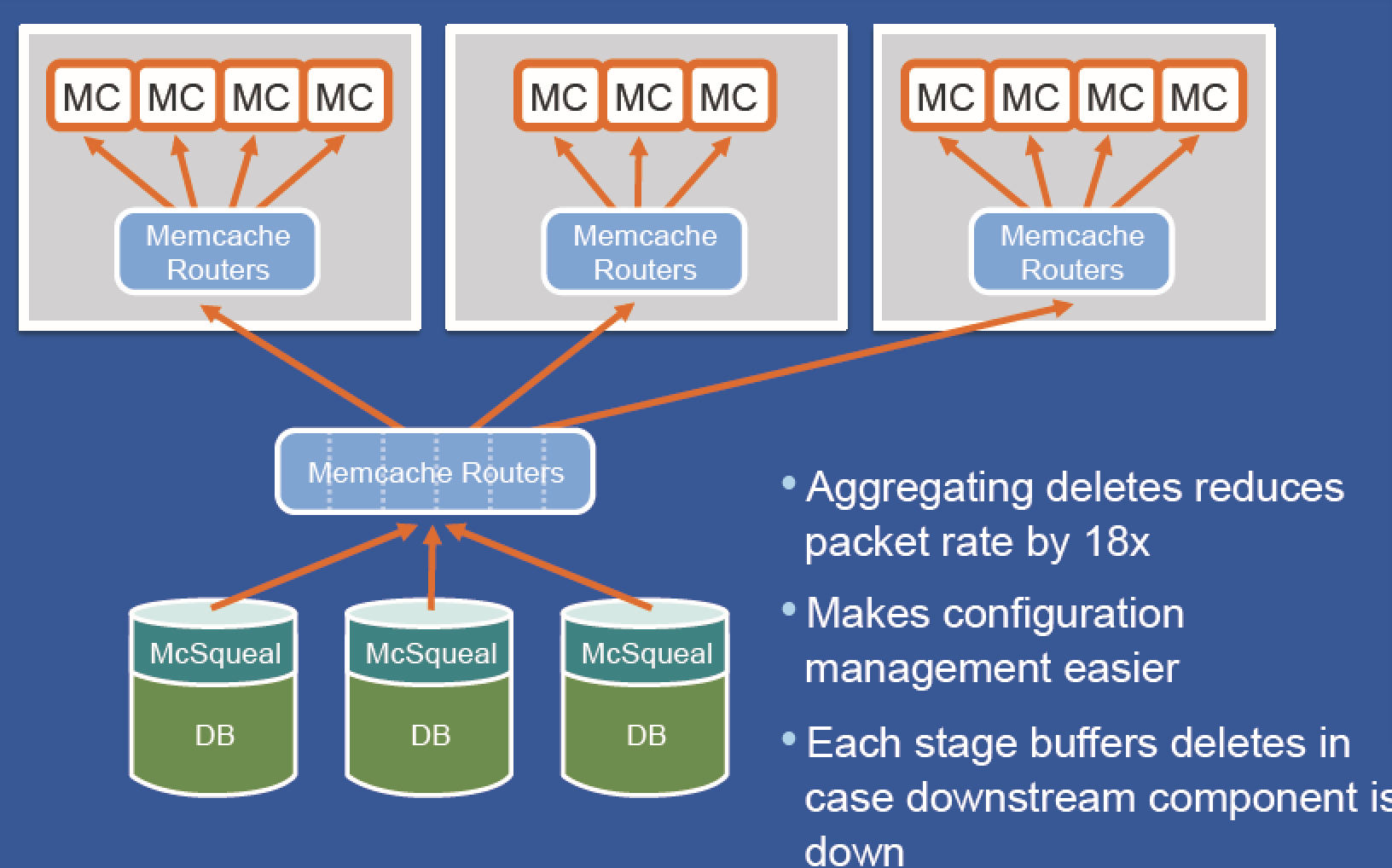
既然有了基于mysql的commitlog的缓存同步,那么跨数据中心的同步也是同理只要设置个从库就行了。
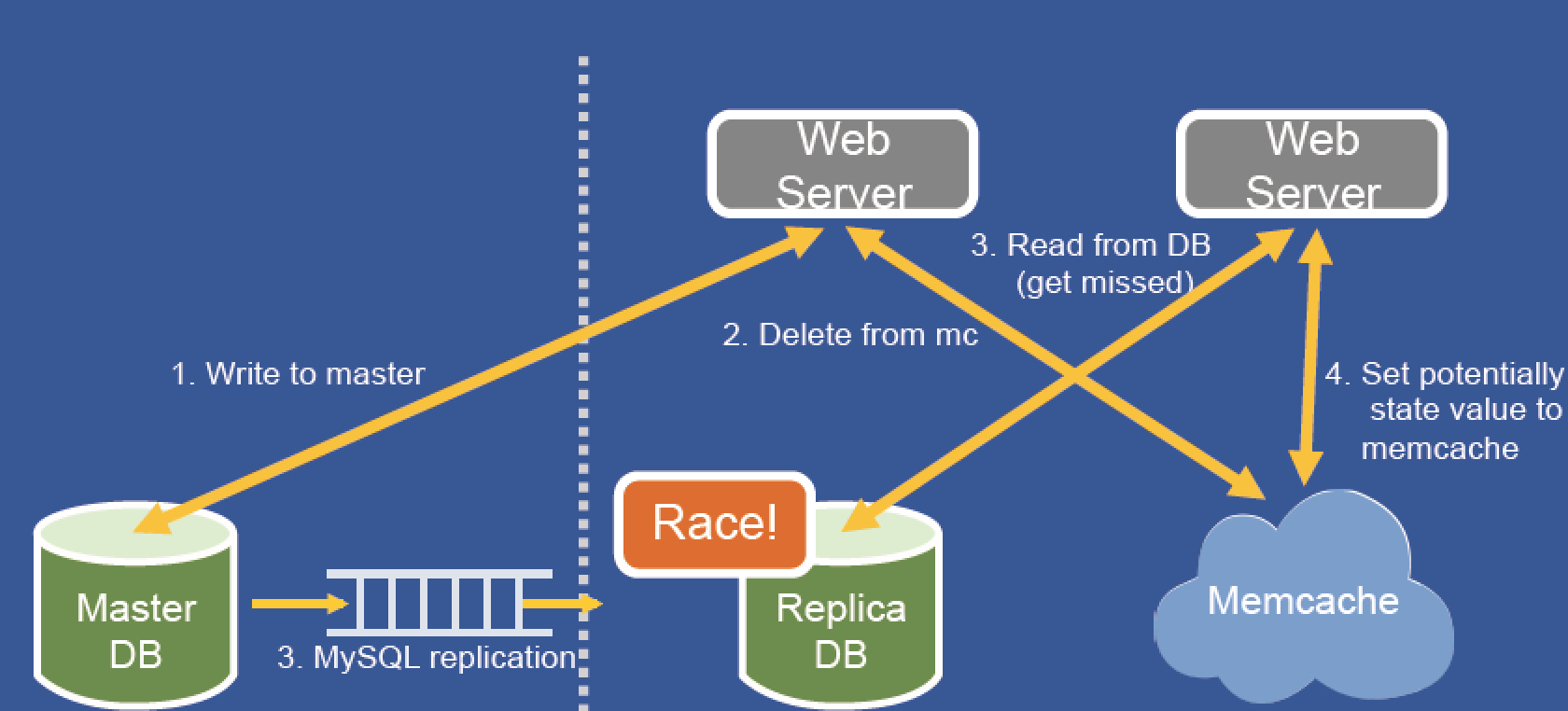
现在的问题是当webserver发生写操作的时候,需要去写master,失效本地Memcache
但是如果此时另外有请求读取缓存,此时发现为空,然后从replicaDB中找到 然后set缓存救护出现问题,因为masterDB 因为时延问题还没有同步完数据
解决方案:
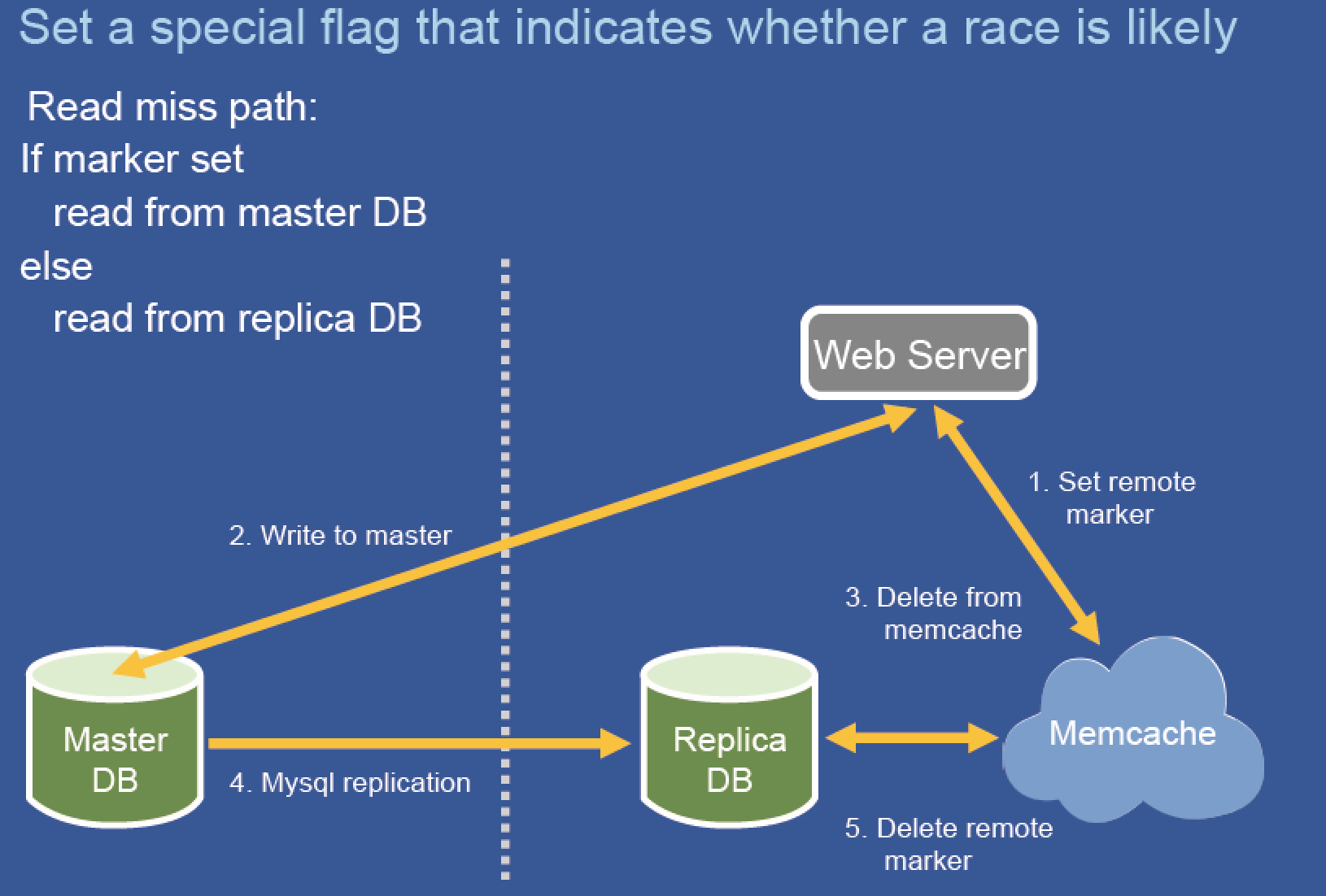
增加一个flag变量 remote-marker 解决问题 如果有设置变量就从masterDB 读取而不是从replicaDB 读取
facebook给出的最佳实践建议:
(1) Separating cache and persistent storage systems allows us to independently scale them. 尽量拆分缓存和存储系统以便幂等的扩容
(2) Features that improve monitoring, debugging and operational efficiency are as important as performance. 不能忽视 监控d ebug 操作便捷性
(3) Managing stateful components is operationally more complex than stateless ones. As a result keeping logic in a stateless client helps iterate on features and minimize disruption. 有状态的很难维护,尽量让客户端无状态
(4) The system must support gradual rollout and rollback of new features even if it leads to temporary heterogeneity of feature sets. 支持回滚
(5) Simplicity is vital. KISS原则 keep it simple and stupid
其实facebook的mcrouter工具非常完美的贯穿了最佳实践的建议,后续我会继续更新博文 介绍一下mcrouter的使用
https://github.com/facebook/mcrouter
剧透一下:
对于memcache的运维 我希望做到
需求1:主从高可用,缓存宕机不会造成穿透
需求2:冷热集群平滑扩容,当人扩容新缓存节点或者替换缓存升级缓存停止缓存的时候
需求3:动态加载配置,无需重启
需求4:多级缓存,可以支持多级比如本地
需求5:灵活的多集群调度,多集群流量调度,前缀调度等
这些需求facebook开源的mcrouter都可以实现
广告时间
网易运维与账号中心正在招聘包含了应用运维、系统运维、数据库运维、运维开发相关岗位:
有兴趣加入的伙伴请简历 hzluyang@corp.netease.com

