1.将爬虫大作业产生的csv文件上传到HDFS
此处选取的是AllSinger.csv文件,共计35084条数据
创建文件夹

启动hadoop
在hdfs上创建文件
将文件上存到hdfs
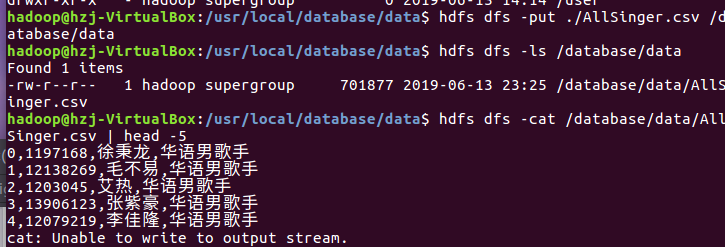
2.对CSV文件进行预处理生成无标题文本文件
编辑pre_deal.sh文件进行数据的取舍处理
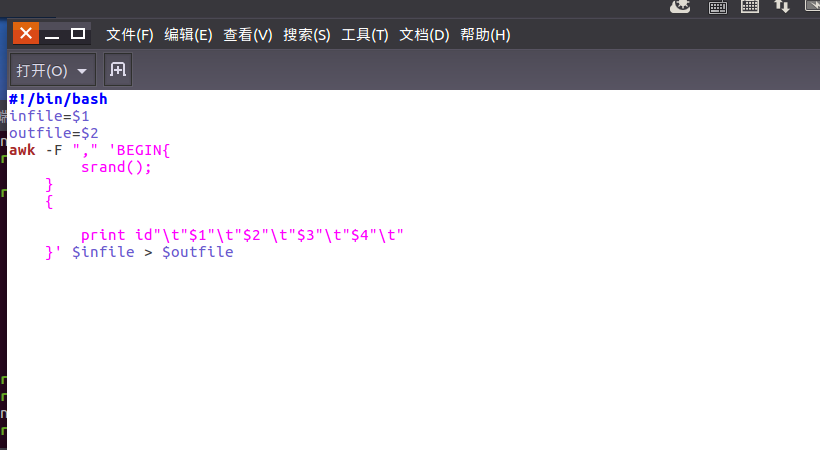
使得pre_deal.sh中的内容生效。
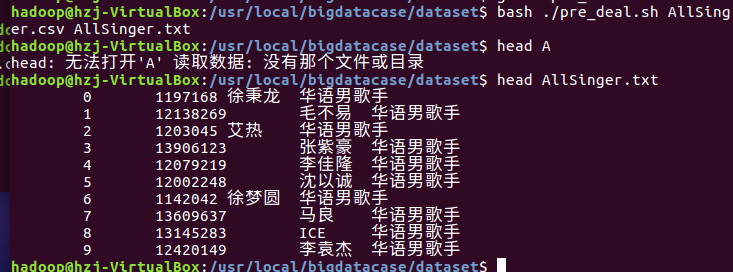
3.把hdfs中的文本文件最终导入到数据仓库Hive中
创建数据库dblab

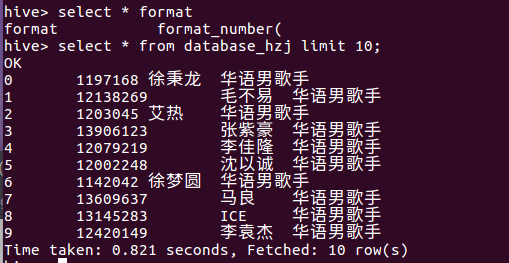
创建表database_hzj并把hdfs中/database/data/目录下的数据加载到表中

4.在Hive中查看并分析数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
1.网易云音乐里歌手姓李的人数


2..歌手信息里面华语歌手个数


3.歌手信息里面华语男歌手个数


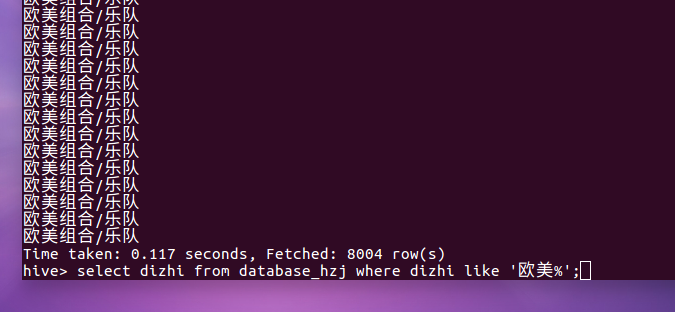
4.歌手信息里面欧美歌手个数
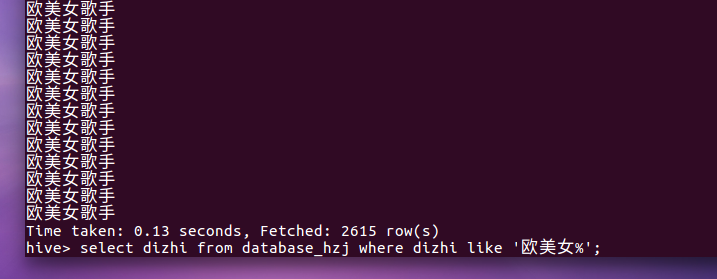
5.歌手信息里面欧美女歌手个数
6.查找有没有陈奕迅

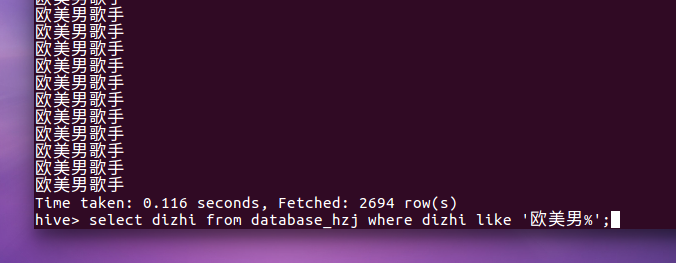
7.歌手信息里面欧美男歌手个数
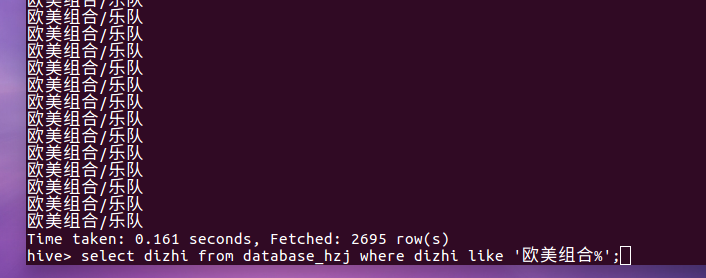
8.歌手信息里面欧美组合个数
9.歌手信息里面华语女歌手个数
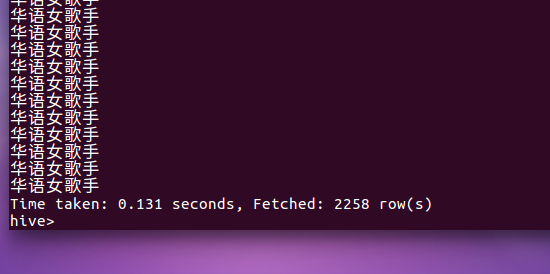
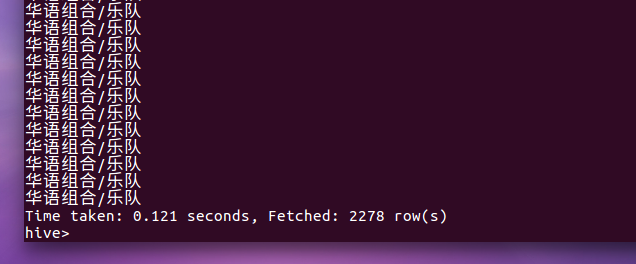
10.歌手信息里面华语组合个数