根:分支的范围,范围块的地址
----- begin tree dump
branch: 0x1000c93 16780435 (0: nrow: 5, level: 1)
leaf: 0x1000c94 16780436 (-1: nrow: 485 rrow: 485)
leaf: 0x1000c95 16780437 (0: nrow: 479 rrow: 479)
leaf: 0x1000c96 16780438 (1: nrow: 479 rrow: 479)
leaf: 0x1000c97 16780439 (2: nrow: 479 rrow: 479)
leaf: 0x1000c98 16780440 (3: nrow: 78 rrow: 78)
----- end tree dump
SQL> select dbms_utility.data_block_address_file('16780435') FILE_ID,
dbms_utility.data_block_address_block('16780435') BLOCK_ID
from dual; 2 3
FILE_ID BLOCK_ID
---------- ----------
4 3219
Btree 索引的 root block总是segment header+1,所以我查询该索引的段头
SQL> select header_file,header_block from dba_segments where segment_name='IDX_TEST';
HEADER_FILE HEADER_BLOCK
----------- ------------
4 3218
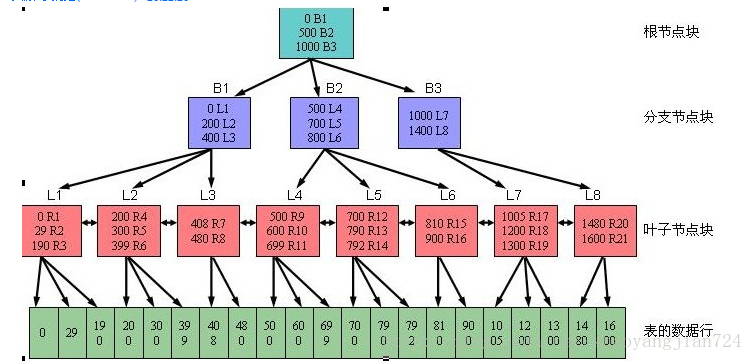
0x1000c93 16进制表示的DBA(data block address),
DBA 之后表示在同一层次的相对位置(root 从0开始,branch 以及leaf从 -1开始)
nrow 表示块中包含了多少条目(包括delete的条目)
rrow 表示块中包含的实际条目(不包括delete的条目)
level 表示从该block到leaf的深度(leaf没有 level)
分支块之间没有联系
索引当中leaf 永远只有1层
为什么 叶子块 是双向链表?
索引默认升序排序
索引当中数据最小放最左边,最大放最右边
对于主键的索引,只增长的都是右边热。
索引的 range scan 究竟是 咋个扫描的???
范围扫描将会从根数据块开始到第一个包含符合特定条件的条目所在的叶子块来遍历索引结构。
再从那一点开始,从索引条目中取出一个行编号然后取出相应的表数据块(通过索引行编号访问数据表)
在第一行被取出来之后,之前的叶子索引块将再一次被访问并读取下一个索引条目来获取下一个行编号。
这种索引叶子块之间的反复来回将会不断持续直到所有匹配的索引都被读出。
因此,所需访问数据块的次数将包含索引中的分支块数(可以通过索引的blevel统计信息得出)
加上符合条件的索引条目数乘以2.
必须乘以2是因为每取出表中返回5行数据并且blevel为3,则总的需要访问的数据块次数将是 (5行 * 2) + 3=13
索引的 range scan 究竟是 咋个扫描的???
首先找到索引的root块
oracle 为啥能找到 索引的root??
因为root块总是segment header+1
找到root就会找到分支,找到分支就会找到叶子节点。