证券行业是中国计算机应用高度密集的行业之一,如何利用好各项数据是券商摆脱低层次的同质化竞争,走向差异化服务优势的重要途径。那么以数据为基础,通过数据分析指导服务和决策就显得尤为重要。
在东北证券的数据平台建设完毕之后,结构化数据初步实现了统一归集,数据报表和图表可视化均可以通过Cognos工具实现。但是,由于Cognos使用繁琐、开发复杂,东北证券的数据小组一直无法接手该工具。
同时,东北证券的新需求不断出现,亟需通过系统保存工作中产生的结构化数据,取代excel记录和上报数据的模式。所以,东北证券自助开发了“数据助手”这一B/S架构的系统,较为完善的解决了当前数据填报的需求。

但是,因为多种原因,两个系统并未采用统一数据库,报表数据查询基于Oracle数据库,数据填报则基于SQL server数据库。数据同步通过ETL工具,每天晚上定时将数据助手库数据抽取至数据平台库。总之,两个不同的系统和两个不同的数据库,让业务人员在使用上费时费力,让IT人员在后台管理上劳心劳力。
东北证券有着近百家营业网点,分布于全国各地,公司总部对各营业网点的任务数据下达需求越发强烈。此外,在大数据和商业智能报表系统技术的迅速发展下,东北证券信息技术部认为,公司需要一套全新的智能报表系统,解决上述全部痛点,同时能够迎上大数据可视化的浪潮,帮助公司不断向前。
周期/节奏
2015年11月,东北证券信息技术部完成了公司大数据分析挖掘平台可行性分析报告,其中智能报表系统将作为其平台上层应用系统之一。报告分析比较了开源版大数据平台和商用版大数据平台的优缺点,以及智能报表系统在大数据平台之上能够为公司提供哪些应用场景。
2016年1月至2月,东北证券信息技术部完成了国内几家大数据平台、智能报表系统等产品的POC测试,完成POC测试报告的编制。
2016年7月,在智能报表系统方面,东北证券选择了帆软报表系统。
2016年8月,完成报表开发的总体需求分析工作,确定了统一的报表式样。
2016年9月,完成了各项需求的开发和测试工作。
2016年10月,东北证券智能报表系统上线试运行。
2016年11月,东北证券智能报表系统正式上线运行。
2016年11月至今,东北证券信息技术部已经能够独立承担公司各项报表开发工作,对公司各业务部在报表数据支持方面,做到了报表需求及时响应,快速落地。
开发工具——帆软报表 FineReport
客户分类/所属分类——东北证券股份有限公司/大数据技术服务
任务/目标
1、智能报表系统能够对接Hadoop大数据平台,通过此系统能够完成BI拖拽和分析功能;
2、实现东北证券各营业网点有权限的查询统计自家资产、交易量和客户数等数据;
3、实现东北证券各营业网点有权限的查询公司总部下达的任务及最新任务完成情况;
4、解决数据填报的问题,在一套系统中实现数据查询和数据填报等功能,拥有附件上传等功能;
5、实现东北证券经纪业务管理部、零售客户部、网络金融部的考核任务填报、绩效考核数据填报;
6、实现东北证券经纪业务管理部对公司各营业网点的基本信息、人员信息、经纪业务数据等多项数据的上报、审核和管理;
7、实现智能报表系统同电子签字板对接,实现无纸化签字办公,实现办公签字统一管理。
挑战
项目实施过程中,主要的挑战来自以下几个方面:
1、传统关系型数据仓库对于大数据量数据的统计、计算效率上的挑战。
2、公司各项经营指标计算方式的了解、掌握、梳理工作。公司数据平台采集汇总多个系统数据,每个系统有各自的供应厂商负责,所以如何了解、掌握各系统数据库表结构,梳理出一系列准确的指标项数据是我们首要面对的挑战之一。
3、由于东北证券的营业网点数量近百家,并且每家营业网点均有3人使用此系统进行数据填表和查询等工作,这样在营业网点方面用户数量有3百人,用户数量较大。
同时,地域分布广,所以在系统上线初期,如何让如此数量的公司员工学会使用该系统,让其学会通过此系统完成数据填报和Excel数据导入等,是比较大的挑战。
4、东北证券总部处于东北长春,相比其他地方,在IT技术、IT人员方面均有不小差距,在大数据技术方面更是如此。所以公司如何能够招入更多大数据技术人才,组建大数据团队,真正将公司大数据平台运作起来,是一项不小的挑战。
实施过程/解决方案
1、平台架构
公司数据平台基于Oralce数据库实现,在大数据量数据的统计、计算效率上性能低下,导致某些报表查询时间超长,操作不友好。
在公司尚不具备hadoop大数据平台的背景下,先通过编写存储过程的方式,优先计算出结果数据,并保存在一张结果表中,从而大幅缩短查询时长。但是仍存在一个问题,就是查询数据仅能实现T+1式查询。
与此同时信息技术部正在筹建Hadoop大数据平台,从而彻底解决此问题。
2、数据采集
在数据采集方面,由于东北证券拥有数据平台,能够实现结构化数据的归集。每个工作日,在柜台交易系统数据初始化完成后,开始进行柜台数据、CRM数据、自营、资管等十多个应用系统数据的采集工作。在数据采集方面不存在困难。
3、数据清洗
较为复杂的工作就是数据清洗。由于ODS层数据包括了柜台数据、CRM数据、自营、资管等十多个应用系统数据,并且每个系统供应厂商并不相同,所以在数据清洗环境耗时耗力较大。
各系统供应商中,有的不同意提供系统表结构文档,有的同意提供系统表结构文档但是文档质量不高,或是文档更新缓慢。
对于不同意提供系统表结构文档的系统供应商,采用同其项目经理沟通指标需求的方式,由其反馈基于ODS层数据的SQL语句。
对于同意提供系统表结构文档的系统供应商,采用先查看表结构文档,根据文档内容同其项目经理沟通指标需求,自主编写SQL语句。此方式较上一种而言,效率更高效,并且可以使我们快速了解表含义和结构关系。
数据清洗结果产出多项数据指标,用于支持智能报表查询统计。
4、数据填报报表开发
数据填报报表分为总部业务部门填报报表和营业网点填报报表。
(1)总部业务部门
总部业务部门填报报表主要用于编制营业网点当年任务、预算,往年绩效数据。
如公司网络金融部根据各营业网点去年开户数量、导流数量,再乘以一定比例,即定义出各营业网点今年需推广安装融e通App的任务数据。此时,数据仍存储在Excel文件中,通过系统的Excel导入功能,导入此数据。
营业网点通过系统可以查询到自家各项任务数据,同时也可以查看到前一工作日任务完成情况数据。例如,本年度任务数量为1万户,截至到上一工作日完成数量3千户,剩余7千户,完成比例30%。
由于总部下达的各项任务数据的计算公式每年都会有变动,所以采用通过数据填报的方式导入数据,而不是在数据平台中通过sql语言编写。优点主要为,计算过程和计算思路均由业务部门完成,技术部门仅需根据需求提前做出填报报表即可。
(2)营业网点
营业网点通过填报报表主要进行数据上报等工作。
公司在没有这种B/S架构系统之前,每个月月初,营业部数据上报需要通过填写Excel后,邮件发送至总部,再由总部逐一核查存档。这种工作方式,对于拥有上百家营业部的公司而言,简直是噩梦。
而如今,通过此系统,公司营业网点在每月月初填报数据即可。现已经做成的填报报表有营业部基本信息报表、营业部人员信息报表、营业部许可证扫描件、营业部经纪数据上报报表等6张填报报表。
(3) 实施过程
- 在数据平台中创建符合该需求的数据库表,建立表字段及索引,建立ID主键。
- 通过智能报表系统的可视化报表开发工具,完成填报报表与数据平台相应表的关联,保证在系统前端,新增、修改、删除数据的同时,对后台物理表进行相同操作。
- 定制开发Excel增量导入插件,通过java编程方式,开发Excel增量导入插件,实现大批量数据,以Excel增量导入的方式,将数据存储后台数据库。
- 将开发好的数据填报报表挂至系统,在授权后,公司业务部门人员可以访问此报表。
5、考核数据、经营数据查询
除数据填报报表外,另一大类别报表就是考核、经营数据查询报表。
公司总部,如经纪业务管理部、零售客户部、机构业务部、网络金融部等等,查询公司经营数据为全体营业网点数据。公司各营业网点则只能查询自家经营数据。
经营数据包括了,新开客户数据、客户资产数据、客户交易量数据、理财产品持仓数据等,包括了公司所有业务部门,所有业务的经营数据。
实施过程:
-
各项经营指标的编写梳理工作,通过编写sql的方式,根据指标基本含义,完成某统计报表脚本编写工作。
-
通过智能报表系统的可视化报表开发工具,完成sql脚本同报表样式的绑定工作。
-
将开发好的统计报表挂至系统,在授权后,公司业务部门人员可以访问此报表。
6、编制使用手册
使用手册主要用于让公司各业务网点的数据填报人员尽快了解掌握数据填报功能。
结果/效果总结
案例项目上线后,该系统得到了东北证券各业务部门、营业网点的肯定。系统指标项规模达到1千左右,系统月查询次数突破1.8万次/月,环比增加100%以上。
东北证券的营业网点在数据查询、统计、上报方面更加游刃有余,实时高效,让其有更多的时间做客户服务工作。
未来的规划
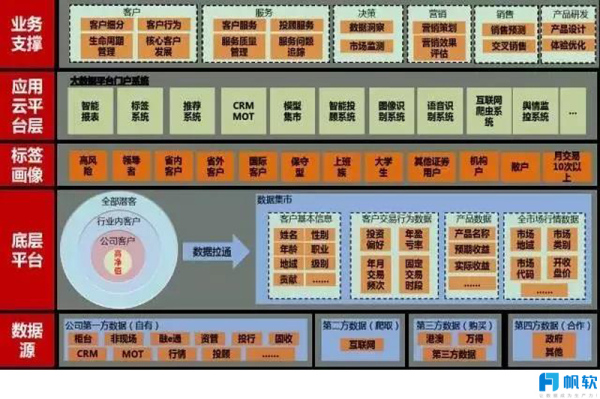
东北证券的数据量约有30TB,在传统数仓下,查询统计数据时效性均无法令人满意,在做数据挖掘时,传统数仓中的数据模型工具缺少已成为阻碍挖掘的绊脚石。当前,东北证券已经立项并考察测试了国内多家大数据平台,同时结合帆软报表进行POC测试,测试结果令人满意。
东北证券打算在大数据平台上线后,结合现有帆软报表的BI功能,实现以下项目目标。
一期项目建设目标(2017年7月至2017年12月)
(1)搭建分布式大数据平台,作为公司唯一的分布式架构平台,作为公司唯一的结构化数据和非结构化数据存储分析计算平台;
(2)用好公司现有数据,将数据指标化、标准化;
(3)完成与帆软智能报表系统对接,让业务部门可以自主出具报表;
(4)上线大数据平台门户系统,作为公司大数据平台门户系统,管理大数据平台上层各项应用系统。
二期项目建设目标(2018年1月至2018年6月)
(1)补充外包数据,打通公司客户的内外数据;
(2)建造客户服务、产品营销新模式,创建客户/产品标签系统,上线资讯/产品推荐系统,创建客户、产品分析模型;
(3)加强与线上用户的联系和互动,提升客户体验;
(4)建立多项风险分析模型,做到风险控制、预警。
三期项目建设目标(2018年7月至2018年12月)
(1)将固定的流程化业务工作,交由机器算法完成,减少人工工作量,例如非现场开户业务、电话服务录音分析;
(2)加强公司舆情信息监控,及时避免负面消息的蔓延;
(3)监控金融证券舆情信息,分析并得出其对市场的影响力度,即可服务公司,也可服务客户。
本文首发CSDN:http://blog.csdn.net/u014514254/article/details/73201232