• 确定是否需要执行恢复
• 访问不同的界面(如Enterprise Manager 和命令行)
• 描述并使用可用的方案,如Recovery Manager (RMAN) 和数据恢复指导
• 对以下文件执行恢复:
– 控制文件
– 重做日志文件
– 数据文件
- 打开数据库
要打开数据库,必须满足以下条件:
• 所有控制文件都必须存在且已同步
• 所有联机数据文件都必须存在且已同步
• 每个重做日志组必须至少有一个成员存在

打开数据库
当数据库从关闭阶段转为完全打开阶段时,数据库会对以下阶段执行内部一致性检查:
• NOMOUNT:实例要达到NOMOUNT(又称STARTED)状态,就必须读取初始化参数文件。实例进入NOMOUNT状态时,不会检查任何数据库文件。
• MOUNT:实例进入MOUNT状态时,会检查初始化参数文件中列出的所有控制文件是否都存在且已同步。即使有一个控制文件缺失或损坏,实例也会向管理员返回错误
(指明控制文件缺失)并保持NOMOUNT状态。
• OPEN:实例从MOUNT状态转为OPEN状态时,它会执行以下操作:
- 检查控制文件已知的所有重做日志组是否至少有一个成员存在。任何缺失的成员会记录在预警日志中。
- 验证控制文件已知的所有数据文件是否存在,但不验证脱机文件。
在管理员尝试使脱机的文件联机之前,不会检查这些文件。如果数据文件不属于SYSTEM或UNDO表空间,管理员就可使数据文件脱机并打开实例。如果缺失了任何文
件,则向管理员返回一个错误,指出第一个缺失的文件,此时实例保持MOUNT状态。当实例发现缺失文件时,错误消息中只显示导致问题的第一个文件。要查找需要恢复的所有文件,管理员可通过检查v$recover_file动态性能视图来获取需要注意的文件的完整列表:
SQL> startup
ORACLE instance started.
Total System Global Area 171966464 bytes
Fixed Size 775608 bytes
Variable Size 145762888 bytes
Database Buffers 25165824 bytes
Redo Buffers 262144 bytes
Database mounted.
ORA-01157: cannot identify/lock data file 4 - see DBWR trace file
ORA-01110: data file 4: '/oracle/oradata/orcl/users01.dbf'
SQL> SELECT name, error FROM v$datafile JOIN v$recover_file USING (file#);
NAME ERROR
----------------------------------- ------------------
/oracle/oradata/orcl/users01.dbf FILE NOT FOUND
/oracle/oradata/orcl/example01.dbf FILE NOT FOUND
- 验证所有未脱机数据文件或只读数据文件是否与控制文件同步。必要时,实例会自动执行恢复。但是,如果某个文件不同步,导致无法通过使用联机重做日
志组进行恢复,管理员必须执行介质恢复。如果任何文件需要进行介质恢复,则向管理员返回一条错误消息,指出第一个需要恢复的文件,此时实例保持MOUNT状态:
ORA-01113: file 4 needs media recovery
ORA-01110: data file 4: '/oracle/oradata/orcl/users01.dbf'
此外,v$recover_file会提供需要注意的文件的完整列表。其中列出了存在的且需要进行介质恢复的文件,但不显示错误消息。
- 使数据库保持在打开状态
打开数据库后,如果有以下项丢失,数据库会失败:
• 任何控制文件
• 属于系统表空间或还原表空间的数据文件
• 整个重做日志组(只要组中至少有一个成员可用,实例就会保持打开状态。)
使数据库保持在打开状态
打开数据库后,以下介质故障可能会导致实例失败:丢失了控制文件,丢失了整个重做日志组,或者丢失了属于SYSTEM或UNDO表空间的数据文件。即使是丢失了一个非活动的重做日志组,数据库也会因为日志切换而最终失败。
在许多情况下,失败的实例并没有完全关闭,但是不能继续工作。必须在关闭了数据库的情况下从这些类型的介质故障进行恢复。因此,管理员必须先执行SHUTDOWN ABORT命令,然后才能开始恢复工作。
丢失了属于其它表空间的数据文件不会导致实例失败,并且可以在数据库处于打开状态时恢复数据库,此时其它表空间中的工作可以继续进行。
通过检查预警日志文件或使用数据恢复指导,可检测到这些错误。
- Data Recovery Advisor(数据恢复指导)
• 快速检测、分析和修复故障
• 停机和运行时的故障
• 将对用户的干扰降到最低
• 用户界面:
– Enterprise ManagerGUI(多个路径)
– RMAN 命令行
• 支持的数据库配置:
– 单实例
– 非RAC
– 支持故障转移到备用数据库,但不支持分析和修复备用数据库
Data Recovery Advisor(数据恢复指导)
在发生错误时,数据恢复指导可自动收集数据故障信息。此外,它还可以主动检查故障。在这种模式下,它有可能在数据库进程发现损坏并指出错误之前就检测和分析数据故障。(请注意,修复始终在人为控制之下)。
数据故障可能会很严重。例如,如果当前日志文件丢失,则不能打开数据库。有些数据故障(如数据文件中的块损坏)并不是灾难性的,因为它们不会导致数据库崩溃或Oracle 数据库无法打开。
数据恢复指导可处理以下两种情况:一种是因必需的数据库文件缺失、不一致或损坏而无法启动数据库,另一种是在运行时发现文件损坏。
解决严重数据故障的首选方法如下所示:
1. 如果处于Data Guard 配置中,则故障转移到备用数据库。这使用户可以尽快地恢复联机。
2. 纠正数据故障的主要原因(幸运的是,这不会对用户造成影响)。
用户界面
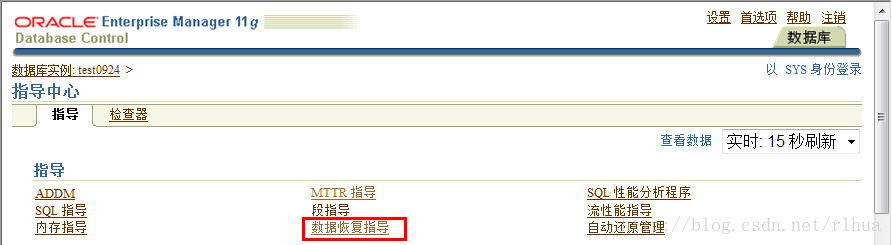
可从Enterprise Manager (EM) Database Control 和Grid Control 使用数据恢复指导。出现故障时,可使用多种方法访问数据恢复指导。以下示例都是从“Database Instance(数据库实例)”主页开始的:
• “Availability(可用性)”选项卡页> Perform Recover(执行恢复)> Advise and Recover(建议和恢复)
• 单击“Active Incidents(活动意外事件)”链接访问“Support Workbench(支持工作台)”上的“Problems(问题)”页:“Checker Findings(检查器查找结果)”选项
卡页> Launch Recovery Advisor(启动恢复指导)
• 定位到“Database Instance Health(数据库实例健康状况)”,然后单击“Incidents(意外事件)”部分中的特定链接(如ORA 1578),访问“Support Workbench
(支持工作台)”的“Problems Detail(问题详细资料)”页,然后单击“Data Recovery Advisor(数据恢复指导)”
• Database Instance Health(数据库实例健康状况)>“Related Links(相关链接)”部分:Support Workbench(支持工作台)>“Checker Findings(检查器查找结果)”选项卡页:Launch Recovery Advisor(启动恢复指导)
• Related Link(相关链接):Advisor Central(指导中心)>“Advisors(指导)”选项卡页:Data Recovery Advisor(数据恢复指导)
• Related Link(相关链接):Advisor Central(指导中心)>“Checkers(检查器)”选项卡页:Details(详细资料)>“Run Detail(运行详细资料)”选项卡页:Launch Recovery Advisor(启动恢复指导)
也可以通过RMAN 命令行使用数据恢复指导:
rman target /
rman> list failure all;
支持的数据库配置
在当前版本中,数据恢复指导支持单实例数据库,不支持Oracle Real Application Cluster
数据库。
数据恢复指导不能使用从备用数据库传送而来的块或文件修复主数据库中的故障。此外,
数据恢复指导也不能用来诊断和修复备用数据库中的故障。但是,数据恢复指导确实支持
故障转移到备用数据库(作为修复方案,如上所述)。
- 丢失了控制文件
丢失控制文件测试恢复参考:http://blog.csdn.net/rlhua/article/details/12625067
如果控制文件丢失或损坏,则实例通常会中止。
• 如果控制文件存储在ASM 磁盘组中,则恢复方案如下:
– 使用Enterprise Manager 执行指导式恢复。
– 将数据库置于NOMOUNT模式,然后使用RMAN 命令从现有控制文件恢复控制文件。
• 如果控制文件存储为常规文件系统文件,则:
– 关闭数据库。
– 复制现有的控制文件来替代丢失的控制文件。
成功恢复控制文件后,打开数据库。
RMAN> restore controlfile from '+DATA/orcl/controlfile/current.260.695209463';
丢失了控制文件
丢失了控制文件后,可选的恢复方案取决于控制文件的存储配置以及是至少还有一个控制文件还是丢失了所有文件。
如果使用ASM 存储,并且至少还有一个控制文件副本,可以使用Enterprise Manager 执行指导式恢复,或者使用RMAN 执行手动恢复,如下所示:
1. 将数据库置于NOMOUNT模式。
2. 连接到RMAN 并发出restore controlfile命令来从现有的控制文件恢复控制文件,例如:restore controlfile from '+DATA/orcl/controlfile/current.260.695209463';
3. 成功恢复控制文件后,打开数据库。
如果控制文件存储为常规文件系统文件并且至少还有一个控制文件副本,这样,在数据库处于关闭状态时,只需将剩余的控制文件中的一个复制到丢失文件的位置。如果介质故障是由于磁盘驱动器或控制器缺失而造成的,则将剩余的控制文件中的一个复制到其它某个位置,然后通过更新实例的参数文件来指向新位置。或者,可从初始化参数文件中删除对丢失的控制文件的引用。请注意:Oracle 建议始终至少保留两个控制文件。
- 丢失了重做日志文件
如果丢失了重做日志文件组中的某个成员,并且组中至少还有一个成员,注意其后果如下:
• 不会影响实例的正常操作。
• 预警日志中会收到一条消息,通知无法找到某个成员。
• 可以通过删除丢失的重做日志成员并添加新成员来恢复丢失的日志文件。
• 如果包含丢失日志文件的组已归档,可以清除日志组来重新创建丢失的文件。
丢失了重做日志文件
如果丢失了单个重做日志组成员,则在进行恢复时不会影响正在运行的实例。
要执行这种恢复,请执行以下操作:
1. 通过检查预警日志,确定是否有缺失的日志文件。
2. 恢复丢失的文件时,首先删除丢失的重做日志成员:
SQL> ALTER DATABASE DROP LOGFILE MEMBER '+DATA/orcl/onlinelog/group_1.261.691672257';
然后添加新成员来替代丢失的红色日志成员:
SQL> ALTER DATABASE ADD LOGFILE MEMBER '+DATA'TO GROUP 2;
也可使用Enterprise Manager 来删除和重新创建日志文件成员。
注:如果重做日志文件使用了OMF,并且使用上面的语法将新的重做日志成员添加到现有组中,则新的重做日志成员文件不会是OMF 文件。如果想确保新的重做日
志成员文件是OMF 文件,最容易的恢复方案是创建一个新的重做日志组,然后删除包含丢失的重做日志成员的重做日志组。
3. 如果介质故障是由于磁盘驱动器或控制器缺失而造成的,请重命名缺失文件。
4. 如果重做日志组已归档,或者处于NOARCHIVELOG模式下,则可选择在清除日志组后重新创建缺失文件来解决问题。选择相应的组,然后选择“Clear Logfile(清除日
志文件)”操作。还可以使用以下命令手动清除受影响的组:
SQL> ALTER DATABASE CLEAR LOGFILE GROUP #;
注:Database Control 不允许清除尚未归档的日志组。这样做会破坏重做信息链。如果必须清除未归档的日志组,则应立即对整个数据库执行完全备份。否则,在发生其它故障的情况下,会导致数据丢失。要清除未归档的日志组,请使用以下命令:
SQL> ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP #;
- 在NOARCHIVELOG模式下丢失了数据文件
数据库处于NOARCHIVELOG模式时,如果丢失了任何数据文件,请执行以下任务:
1. 如果实例尚未关闭,请关闭实例。
2. 从备份还原整个数据库,包括所有数据文件和控制文件。
3. 打开数据库。
4. 让用户重新输入自上次备份以来所做的所有更改。
在NOARCHIVELOG模式下丢失了数据文件
如果在NOARCHIVELOG模式下丢失了数据库中的任何数据文件,则需要完全还原数据库,包括控制文件和所有数据文件。
当数据库处于NOARCHIVELOG模式时,只能恢复到上一次备份时的状态。因此,用户必须重新输入自上一次备份以来所做的所有更改。
要执行这种类型的恢复,请执行以下操作:
1. 如果实例尚未关闭,请关闭实例。
2. 在“Maintenance(维护)”属性页上单击“Perform Recovery(执行恢复)”。
3. 选择“Whole Database(整个数据库)”作为恢复类型。
如果处于NOARCHIVELOG模式的数据库具有增量备份策略,则RMAN 会先还原最近的0 级备份,然后RMAN 恢复进程再应用增量备份。
- 在ARCHIVELOG模式下丢失了非关键数据文件
如果某个数据文件丢失或损坏,且该文件不属于SYSTEM或UNDO表空间,则只还原并恢复缺失的数据文件。

在ARCHIVELOG模式下丢失了非关键数据文件
数据库处于ARCHIVELOG模式时,如果丢失了任何不属于SYSTEM或UNDO表空间的数据文件,则只会影响缺失文件中的对象。用户仍可使用数据库的其余部分继续工作。要还原并恢复缺失的数据文件,请执行以下操作:
1. 在“Maintenance(维护)”属性页上单击“Perform Recovery(执行恢复)”。
2. 选择“Datafiles(数据文件)”作为恢复类型,然后选择“Restore to current time(还原到当前时间)”。
3. 添加所有需要恢复的数据文件。
4. 确定是将文件还原至默认位置还是新位置(如果磁盘或控制器缺失)。
5. 提交RMAN 作业,还原并恢复缺失的文件。
由于数据库处于ARCHIVELOG模式,因此可恢复到最近提交的时间,并且用户不需要重新输入任何数据。
使用脚本:
contents of repair script:
# restore and recover datafile
sql 'alter database datafile 10 offline';
restore datafile 10;
recover datafile 10;
sql 'alter database datafile 10 online';
# restore and recover datafile
sql 'alter database datafile 10 offline';
restore datafile 10;
recover datafile 10;
sql 'alter database datafile 10 online';
- 在ARCHIVELOG模式下丢失了系统关键数据文件
如果某个数据文件丢失或损坏,且该文件属于SYSTEM或UNDO表空间,请执行以下任务:
1. 实例可能会也可能不会自动关闭。如果未自动关闭,请使用SHUTDOWN ABORT关闭实例。
2. 装载数据库。
3. 还原并恢复缺失的数据文件。
4. 打开数据库。
在ARCHIVELOG模式下丢失了系统关键数据文件
属于SYSTEM表空间或包含UNDO数据的数据文件被认为是系统关键数据文件。如果丢失了其中一个文件,就需要从MOUNT状态还原数据库(不同于在数据库处于打开状态时还原其它数据文件)。
要执行这种恢复,请执行以下操作:
1. 如果实例尚未关闭,请关闭实例。
2. 装载数据库。
3. 在“Maintenance(维护)”属性页上单击“Perform Recovery(执行恢复)”。
4. 选择“Datafiles(数据文件)”作为恢复类型,然后选择“Restore to current time(还原到当前时间)”。
5. 添加所有需要恢复的数据文件。
6. 确定是将文件还原至默认位置还是新位置(如果磁盘或控制器缺失)。
7. 提交RMAN 作业,还原并恢复缺失的文件。
8. 打开数据库。因为会恢复到上一次提交时,所以用户不用重新输入数据。
- 数据故障:示例
• 组件无法访问:缺少操作系统级别的数据文件、访问权限不正确、表空间脱机
• 物理损坏:块校验和错误、块头字段值无效
• 逻辑损坏:目录不一致;行片段、索引条目或事务处理损坏
• 不一致:控制文件早于或晚于数据文件和联机重做日志
• I/O 故障:超出打开文件数限制、通道无法访问、网络或I/O 错误
数据恢复指导可以分析故障,并针对不断增长的问题列表提供修复方案建议。
- 数据恢复指导

Oracle Database 11g中的自动诊断工作流可为你执行工作流步骤。利用数据恢复指导,只需启动建议和修复即可。
1. 健康状况监视器自动执行检查并以“调查结果”的形式将故障及其症状记录到自动诊断资料档案库(ADR) 中。
2. 数据恢复指导将调查结果与故障合并在一起,并按故障严重程度(严重或高)列出以前执行的评估结果。
3. 请求提供有关故障的修复建议时,数据恢复指导会将故障对应到自动和手动修复方案,检查基本可行性,然后提供修复建议。
4. 可以手动执行修复,也可请求数据恢复指导执行修复。
5. 除了健康状况监视器的自动检查(基本是“被动式”检查)以及数据恢复指导之外,Oracle 还建议使用VALIDATE命令执行“预先”检查。
- 评估数据故障
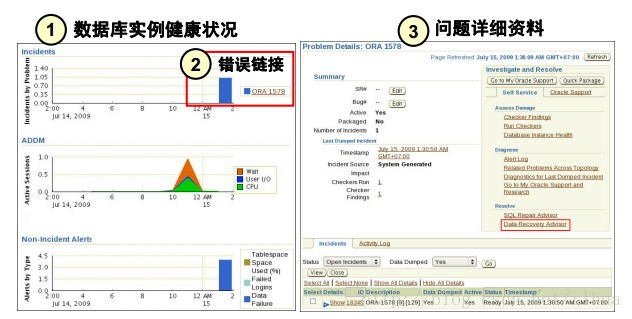
示例显示了多种可能方式中的一种,可用来了解与健康状况监视器和数据恢复指导的交互情况。
- 数据故障
可通过检查来检测数据故障,检查是评估数据库或其组件健康状况的诊断过程。每个检查都可诊断一个或多个故障,然后将其映射到修复。
检查可以是被动检查,也可以是预先检查。数据库中发生错误时,系统会自动执行被动式检查。此外,也可以启动预先检查(例如,执行VALIDATE DATABASE命令)。
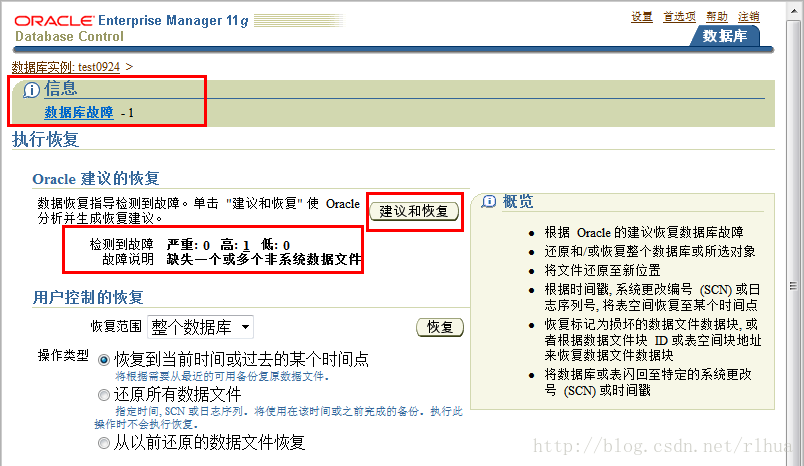
在Enterprise Manager 中,选择“Availability > Perform Recovery(可用性> 执行恢复)”,或者在数据库处于“关闭”或“已装载”状态时单击“Perform Recovery(执行恢复)”按钮。单击“Advise and Recover(建议和恢复)”让Enterprise Manager 分析和生成恢复建议。
- 列出数据故障
此“View and Manage Failures(查看和管理故障)”页是数据恢复指导的主页。屏幕快照中的示例显示了数据恢复指导如何列出数据故障和详细资料。可在其中启动的活动包括:提出建议、设置优先级以及关闭故障。
RMAN 基础命令LIST FAILURE也可以显示数据故障和详细资料。此处不启动故障评估将在ADR 中执行和存储这一评估。
故障按以下优先级降序顺序列出:CRITICAL、HIGH、LOW。优先级相同的故障将按时间戳的升序列出。
- 提供修复建议

在“View and Manage Failures(查看和管理故障)”页上单击“Advise(建议)”按钮后,数据恢复指导会生成一个手动核对清单。可显示两种类型的故障。
• 需要人工干预的故障:例如,未插入磁盘电缆的连接故障。
• 可通过撤消以前的错误操作快速修复的故障:例如,如果错误地重命名了数据文件,则与从备份启动RMAN 还原相比,将该文件重命名回以前的名称可以更快地进行修复。

可启动以下操作:
• 在执行手动修复后,单击“Re-assess Failures(重新评估故障)”。已解决的故障将隐式关闭;“View and Manage Failures(查看和管理故障)”页上会显示所有剩余故障。
• 单击“Continue with Advise(继续使用建议)”启动自动修复。数据恢复指导生成自动修复方案时,会生成一个脚本,其中显示RMAN 计划修复该故障的方法。如果
要执行自动修复,则单击“Continue(继续)”。如果不希望数据恢复指导自动修复故障,则可以从此脚本开始进行手动修复。
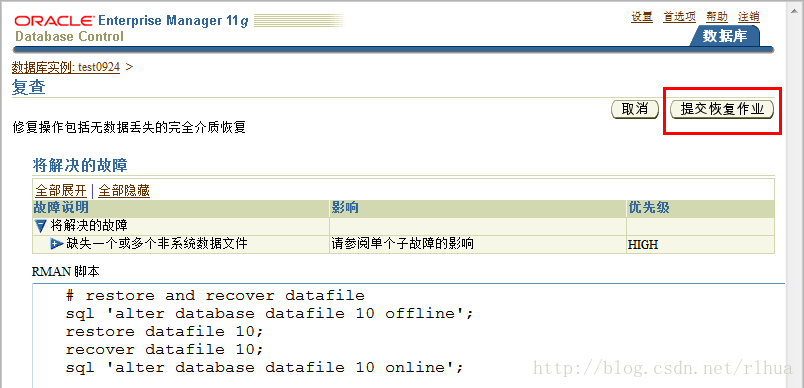
- 执行修复
上页点击继续完成建议后生产rman脚本

# restore and recover datafile
sql 'alter database datafile 10 offline';
restore datafile 10;
recover datafile 10;
sql 'alter database datafile 10 online';
提交恢复作业,让其自动执行。
查看运行的作业
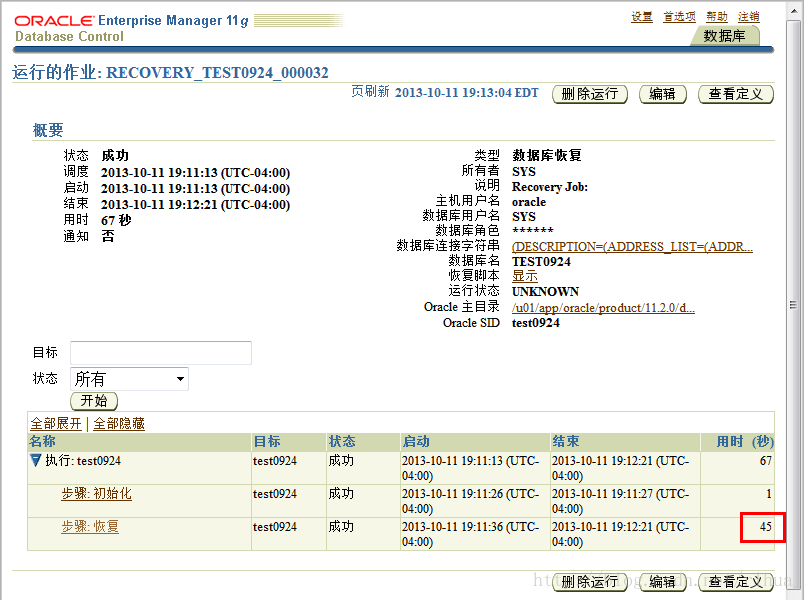
数据恢复指导会显示这些页面。在该示例中,45秒就成功地完成了修复。
- 数据恢复指导视图
查询动态数据字典视图
• V$IR_FAILURE:列出所有故障,其中包括已关闭的故障(LIST FAILURE命令的结果)
• V$IR_MANUAL_CHECKLIST:列出手动建议(ADVISE FAILURE命令的结果)
• V$IR_REPAIR:列出修复(ADVISE FAILURE命令的结果)
• V$IR_FAILURE_SET:交叉引用故障和建议标识符
用法示例
假设需要显示在2007 年6 月21 日检测到的所有故障。
SELECT * FROM v$ir_failure WHERE trunc (time_detected) = '21-JUN-2007';