165.View the Exhibit exhibit1.

In the CUSTOMERS_OBE table, when the value of CUST_STATE_PROVINCE is "CA", the value of COUNTRY_ID is "US."
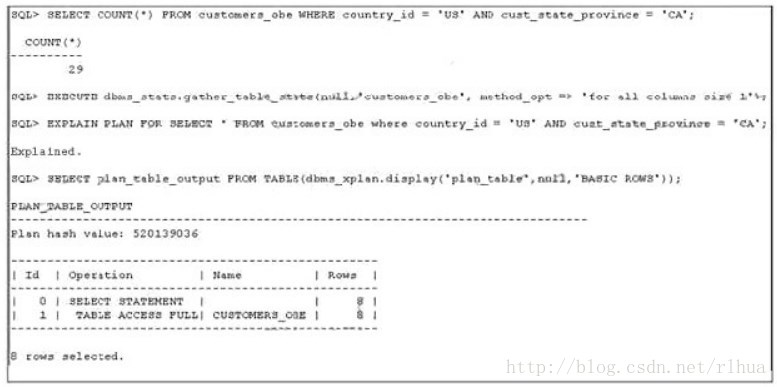
View the Exhibit exhibit2 to examine the commands and query plans. The optimizer can sense 8 rows
instead of 29 rows, which is the actual number of rows in the table. What can you do to make the
optimizer detect the actual selectivity?
A. Change the STALE_PERCENT value for the CUSTOMERS_OBE table.
B. Set the STATISTICS_LEVEL parameter to TYPICAL.
C. Create extended statistics for the CUST_STATE_PROVINCE and CUSTOMERS_OBE columns.
D. Set the OPTIMIZER_USE_PENDING_STATISTICS parameter to FALSE.
Answer: C
答案解析:
参考:http://docs.oracle.com/cd/E11882_01/server.112/e41573/stats.htm#PFGRF94728
Managing Extended Statistics
DBMS_STATS enables you to collect extended statistics, which are statistics that can improve cardinality estimates when multiple predicates exist on different columns of a table, or when predicates use expressions.
An extension is either a column group or an expression.
Oracle Database supports the following types of extended statistics:
-
Column group statistics
This type of extended statistics can improve cardinality estimates when multiple columns from the same table occur together in a SQL statement. See"Managing Column Group Statistics".
-
Expression statistics
This type of extended statistics improves optimizer estimates when predicates use expressions, for example, built-in or user-defined functions.
Managing Column Group Statistics
When the WHERE clause of a query specifies multiple columns from a single table (multiple single column predicates), the relationship between the columns can strongly affect the combined selectivity for the column
group.
For example, consider the customers table in the sh schema. The columns cust_state_province and country_id are related, with cust_state_provincedetermining the country_id for
each customer. Suppose you query the customers table where the cust_state_province is California:
The preceding query returns the following value:
Adding an extra predicate on the country_id column does not change the result when the country_id is 52790 (United States of America). Assume that you run the following query:
The preceding query returns the same value as the previous query:
Assume that the country_id has a different value, such as 52775 (Brazil), as in the following query:
In this case the returned value is as follows:
With individual column statistics, the optimizer has no way of knowing that the cust_state_province and the country_id columns are related. By gathering statistics on these columns as a group (column
group), the optimizer has a more accurate selectivity value for the group, instead of having to generate the value based on the individual column statistics.
You can create column groups manually by using the DBMS_STATS package. You can use this package to create a column group, get the name of a
column group, or delete a column group from a table.