我们实现了"异步共识组"模型,可以将一个现有的单链共识算法,横向扩展1000倍以上。这样的扩展将使得吞吐量(TPS)提升1000倍以上,同时也将全网计算能力(CPU)提升2000倍以上,将状态表达的内存空间(RAM)提升2000倍以上。
异步共识组系统的性能提升,丝毫没有牺牲去中心化特性,随着全网的横向扩展提升,每一个全节点的工作压力(带宽、计算、内存、磁盘IO)并没有显著的加大,始终保证一台普通中档价位的电脑可以轻松地作为网络的一个全节点,通过普通家用宽带网络接入主网。
异步共识组系统的性能提升,是在保证安全的基础上的。虽然系统允许全网被划分成上千个独立异步工作的共识组,但是我们的协议使得攻击任何一个单独分片的实际需要的物理算力,和攻击整个网络的物理算力相当。这样使得这个高度分片之后的异步共识组系统具备和单链系统一样的安全性。
异步共识组系统的性能提升,对上层交易结构是中立的。这个技术不引入任何交易结构上的假设(例如假设少数人直接频繁交易之类)。可以完美支持任意场景的大规模支付系统的需求。
这个工作,除了我和汪浩之外,还有张小兵(前pplive技术合伙人)一起参与研究和实现。借这个机会也感谢我老板开复老师和我们的导师沈向洋老师的支持,还有Lidong Zhou老师的指导,以及bob, minghao,sophia,shumo,shuang等同学们的建议和挑战。
NSDI 2019
11月30号那天周五晚上,汪浩突然打电话给我,说看邮件,论文中了。本来官方声称是3号周一才发录用通知的。在论文委员会开会讨论(table discussion)之前,提早发通知,通常是两种情况,论文毫无争议地被录用,或者毫无争议地被拒收。脑补一下,汪浩刚刚收到邮件还没点开之前的心情。要知道之前无数专注公链性能的团队,希望可以在NSDI,OSDI 或者 SOSP 这样的系统领域国际顶会上通过严格的同行评语,发表自己的论文。但是极为不易,上一篇区块链公链论文,是2017年的SOSP,就是著名的AlgoRand项目。

论文被接受的邮件通知,投稿时论文取了一个更为朴素的标题
我们的基础实现和实验验证,在今年夏天的时候完成,9月份的时候投稿了NSDI 2019。12月初完成严格的同行评议,同另外49篇论文一起被该会议接收,将于2019年2月底在波士顿正式公开发表。我们之所以愿意等待,是因为我们觉得考验新技术必须来自于国际主流学术同行的认可,尤其是那些和我们在同一个研究方向上竞争的学者们。而不是自说自话地发个白皮书或者丢一个没有评审过的arXiv的文章。通常技术白皮书是帮助使用者更好地理解一项已经产品化的成熟技术,而不是用来提出尚未验证的新技术。论文需要非常清楚地定义问题,说明新设计的动机和取舍,探讨新技术的边界和局限性,而不是像白皮书那样仅仅说明这个新技术提供了什么。在工科的论文中,推导过程比结论重要,思路比解法重要,失败案例比成功案例重要,实验的设计和规范比实验结果重要,从而启发后继的研究工作,推进相关领域的发展。
之前区块链相关工作很多发表在密码学会议或者网络安全会议,我们为什么投NSDI呢? 因为我们的工作核心突破在于大幅提升区块链系统的伸缩性,而不是提出了另一个的共识算法。NSDI全称是Networked Systems Design and Implementation,是 USENIX (Advanced Computing Systems Association)旗下的旗舰会议之一,也是计算机网络系统领域久负盛名的顶级会议。NSDI 侧重于网络系统的设计与实现,注重系统的性能和伸缩性。众所周知的著名大数据系统 Spark 就发表在 2012 年的 NSDI 大会上。最懂网络系统伸缩性的学者,在这个领域。
在今年接受的49篇文章中,有超一半来自美国顶尖高校(MIT, UC Berkeley, Stanford, CMU, Princeton, Cornell, UW, Harvard, Yale等等等),另外近一半来自微软,Google,Intel等美国知名云计算相关企业。其中国内高校仅有清华大学有3篇文章被录用,分别是关于网络系统建模、超算系统监控以及RFID无线技术。另外值得一提的是,今日头条(Bytedance)有5篇文章被接收,全部是和微软合作发表。果然是不少人从微软跳去了头条 (微笑 。 在今年录取的论文中, 仅有我们这一篇论文是和区块链相关,很荣幸被安排在会议的第一天,分布式系统专场,进行演讲,同一个场次的还有两篇分别来自Stanford和MIT的论文。区块链相关技术在整个学术界还是非常新兴的研究课题,希望能有更多同学来这个领域。
异步共识组 (Asynchronous Consensus Zones)
这篇文章的标题为: Monoxide: Scale Out Blockchain with Asynchronous Consensus Zones。其关键设计就是这个Asynchronous Consensus Zones,异步共识组。这里的核心是Consensus Zone,而不是Asynchronous 。异步是一个重要的特性,但其核心是共识组这个模型。然后Monoxide是这个项目的code name。
我们回顾一下这个共识组的概念:
共识组由多个同质的、功能上完全一致、地位上也完全平等,并逻辑上尽量隔离的独立共识系统的实例所构成,他们并行工作,分摊全网的吞吐、计算、存储的压力,分摊全网状态的维护工作。
0. 具备独立的相对稳定的节点集合,逻辑上不要求一个节点参与到多个共识组
1. 具备独立的账簿,承载全网的一部分用户(组内用户)。各个共识组的组内用户没有交集
2. 具备独立的Chain of Blocks,仅记录已经确认的和组内用户相关的交易
3. 具备独立的非阻塞的出块过程,各个组之间没有任何同步的需要 (如需要互斥锁定特定资源)
4. 具备独立的未确认交易集合,仅有和组内用户相关的未确认交易会被暂存
5. 具备独立的出块候选或竞争机制,矿工仅限于组内竞争,和其他组的矿工无直接竞争关系
6. 具备独立的Gossip网络,完成区块和未确认交易的广播,不波及其他共识组的节点
我们就是设计了这样的一个系统以及协议,保证其上的跨分片交易可以正确、高效地完成,保证攻击单个共识组的代价同攻击整个网络代价相当,保证单个运行中的全节点需要承担的系统压力不会随着全网性能的提升而变大。具体在单个共识组内部采用的共识算法,可以是PoW,也可以是类BFT或者VRF算法。我们的基础实现,基于最朴素的PoW算法。
伸缩性
同通过新的共识算法来实现性能提升的设计不同,对于异步共识组这样的分片系统来说,系统的性能不是一个定值,是一个和系统资源配置相关的,可以被调整的值。就好像一个多个稳定转速的发动机,不同的油耗就有不同的推力。在异步共识组中,这个油耗就是全网有多少全节点,有多少矿工节点。不过,相信大家总是希望看到一个数字,我这里也得列一下。

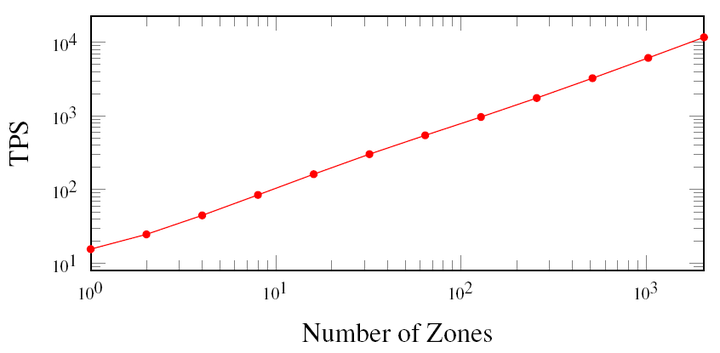
这个是最高48000个节点的测试网络中的实测吞吐量,横轴是这些节点被划分成了多少个共识组,纵轴是平均每秒处理的交易量。在我们的测试中,最大的共识组数量为2048,此时吞吐量为11694 TPS。这个数字已经远超现今所有公开发表的运行于互联网上的公链项目,当然那些只在机房里面跑,单节点采用怪兽般服务器的项目除外。
但是我这里想说的是,这个绝对数字不是重点。这个图核心要展示的是这个方案的线性伸缩性,也就是随着共识组数量的增加,全网的吞吐量将获得线性地提升。同时,全网的的状态内存空间、交易处理的计算力、归档交易的存储空间也将同时得到线性的提升。这才是所谓的伸缩性。下面我进一步展开介绍这个实验的细节。
1. 单节点压力 这个实验在1200台主机(8核CPU,32G内存)上,最多运行了48000个全节点实例,每个节点限定最高带宽30Mbps。从几十个共识组,到几千个共识组,单节点的压力始终不大,可以轻松运行在这样配置的主机上。最极端的情况,一个主机运行了40个实例。
2. 测试工作集 在这个实验中,我们展现的是处理一对一支付交易的性能。每一个交易还有支付源和宿的地址,以及和源地址对应的签名,还有支付金额,总共百来个字节。为了使得测试更为真实,尤其是跨片的发生概率的真实情况,我们的测试工作集使用以太坊上所有ERC20代币支付的历史记录(截止高度5867279),而不是自行随机生成交易。其中包含1.6千万个地址,和7.6千万条交易记录。我们将这个工作集在全网重放(忽略原始时间),以获得测试结果。
3. 物理网络 我们将1200台主机,平均分布在全球15个不同国家的城市,从而使得测试网络接近真实的互联网延迟。我们实测的平均延迟为102毫秒。
4. 共识算法 我们在单个共识组中,采用了类GHOST的POW算法,目标出块间隔15秒,单个共识组的吞吐量为15.6 TPS。这是一个非常保守的设定,可以简单地通过扩大块尺寸获得额外几十倍的提升。当然,通过这种方式获得的提升,并不能体现我们自身的技术价值。
5. 交易延迟 在异步共识组中,非跨片交易交易确认时间和单链系统无异。跨片交易的确认时间将会最大延长到原来的2倍,平均1.5倍,即22.5秒左右。
6. 跨片开销 处理跨片交易是会有额外的开销的,但是好在我们的算法使得这个开销是个常数,和共识组的数量无关。细心的同学可能已经发现,15.6 TPS × 2048 = 31948.8 TPS 远大于 我们实测的 11694.9 TPS。事实上,每一次共识组数量翻倍,其性能提升并不是2倍,而是一个稍低的数字。这个在图中的第一段更为明显,那一段是提升是1.6倍,第二段是1.8倍,之后逐渐收敛到1.9倍。这部分的额外开销,同跨片交易比例增高有关,也和需要协同更多的共识组有关。
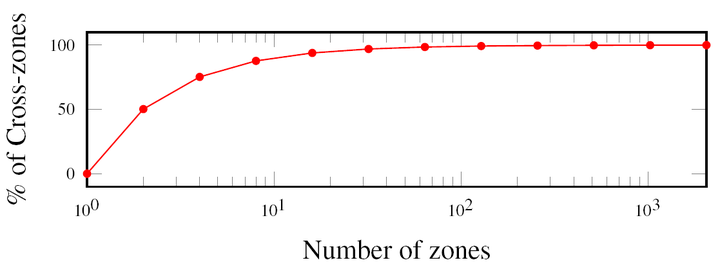
下图展示了在基于以太坊历史交易记录的测试集中,跨共识组交易的比例。很显然分片越多,用户会被切得更细,就会有更大的概率使得交易双方处于不同分片。图中可以看到,在分片到128个共识组的时候,跨共识组交易的比例就几乎已经是100%了。我们的算法并不回避这个状况,而是给出了高效的跨片处理方案,从而使得全网的伸缩性继续保持线性提升,而不受跨片交易的制约。

算法和协议上的挑战
为了让这样的一个系统设计可以正确,安全地工作。有一系列的技术挑战。也是论文在学术层面所作出的贡献。
1. 高效处理跨片交易 我们在论文中采用了无须状态锁定的异步执行方式,最终原子性(Eventual Atomicity),最大限度地保证了各个共识组可以高效吞吐,不会互相阻塞。而这里的安全性是通过源共识组的共识证明来完成。这一点在思路上有些类似一些跨链的工作,但是有一个本质的不同。在共识组中,各个组是互相配合,互相信任的,他们互相承认对方的共识证明,所以我们可以找到不引入任何中心化节点的方式来保证安全。而通常的跨链算法中,至少有一条链是不配合的,不承认甚至根本就读不到对方链的状态。
2. 跨分片交易逻辑 如果只是支付,跨分片交易逻辑可以拆分成 "扣款" 和 "存款" 两个交易步骤,然后分别在不同分片中完成。那么为什么这么拆开了就可以顺利地完成跨分片交易,更为复杂的交易逻辑该如何处理呢? 我们在论文中提出了Oxidation编程模型,用来定义分片系统中的智能合约。编程模型不是说我们用Javascript、C++、PHP,还是用Web Assembly,亦或是Solidity。这里的区别是类似面向对象编程和面向过程编程的区别,具体语法,语义,格式等方面的差异并不重要。Oxidation编程模型其核心逻辑基于函数编程(Functional Programming),这么做的原因是交易逻辑的代码能够比较容易在编译器层面被切分,继而方便在各个共识组中接力运行。而上层开发者则比较容易用函数编程的方式来表达对分片系统比较友好的交易逻辑。至于其他计算表达,状态定义,流程控制等编程特性分片系统不需要语言层面的特殊支持,与普通系统无异。
3. 保证单共识组的安全 在单链系统中,系统的安全性依赖多数诚实矿工或验证者来保障安全,例如PoW系统需要51%,类BFT系统通常需要2/3等。当全网被N个分片隔离,每个分片独立出块的时候,简单的思路会导致单个分片内部最低只有1/N的诚实算力(或验证垫资)来抵御攻击。在我们提出的异步共识组中,我们拓展了PoW的挖矿机制,运行一个矿工同时参与多个共识组内部的挖矿竞争,可以收获到多个共识组里面的出块奖励。至关重要的是,对于一个参与K个共识组挖矿的矿工,其实际有效算力会被放大为其物理算力的K倍,并且其放大后的算力必须平均分配到这K个共识组。从而使得单个共识组的实际有效算力,将等同于全网的物理算力,那么攻击单个共识组将变得和攻击全网一样的难。我们将这个机制称为连弩挖矿(Chu-ko-nu Mining),这个机制保证了将诚实矿工(平均贡献算力到多个共识组)的有效算力放大了N倍,而对于攻击者(针对特定共识组)来说,这里的算力放大则无效。注意,这里的诚实矿工的有效算力放大倍数,和全网的分片个数相同,从而保障了全网在高度分片之后仍旧具备同单链系统一样的安全性。
局限性
估计大家很少看到介绍自己工作的文章,会有这个章节。但其实我觉得应该有,让大家知道特定的技术边界,总好过事后牛皮吹破,系统实现不出来。首先这个技术算是突破了区块链所谓的不可能三角吗? 我认为是,虽然还不算彻底,但是可以说撕开了一个巨大的口子。这个工作并不能实现无限的伸缩性,基于当前互联网带宽,系统的伸缩性大致会止步于百万TPS和几十万个共识组的规模。这是因为,为了使得跨片交易得以正确安全地完成,共识组之间需要传递成链的块头信息,这部分信息在共识组数量达到一定规模之后,会占据相当的带宽消耗。
具体来说,每个单节点的需要观察所有共识组中的构造链的过程以及他们可能出现的分叉。这个代价是 每个共识组每块大致256个字节。那么在我们现在的实验中,达到11694.9 TPS的时候,这个部分的消耗是279.6kbps,与之相关的存储和计算代价可以忽略不计。按照前面实验中单节点带宽限定,这个部分占据了近1%。也就是说在30Mbps的单节点带宽约束之下,共识组的数量的天花板在20万左右,当然这时全网吞吐量将可以高达百万TPS,全网状态内存容量将超过1PB (1,000,000 GB)。
值得一提的是,这个代价是和出块尺寸无关,需要传播的仅为块头,和单位时间出块个数有关。那么,我们可以扩大出块尺寸,同时等比提高出块间隔,来降低这个部分的开销,并且保持吞吐量不变,单节点压力也不增加。只是这样做会使得交易确认时间变长。
限制共识组数量的另一个因素是社区的规模,全网矿工节点和全节点的总和。对于单个共识组来说,参与其中的节点不能太少(至少要过百吧),否则会容易暴露出块节点(矿工)的物理IP地址,也会增大全节点被隔离欺骗(与全节点连接的其他对等节点全部是恶意节点)的概率。虽然这两点都不会直接导致共识算法失效,但是有可能降低攻击壁垒。在异步共识组中,我们鼓励一个全节点参与多个共识组,而矿工节点参与多个共识组更是有利可图,这在一定程度上缓解了这个问题。
所以,对于分片系统来说,吞吐量和容量从来都不是一个单一的数字,而是一个根据具体应用场景,安全约束,延迟敏感程度,社区发展阶段,交易活跃度等多方面考虑的权衡设计,是一个可以调整的东西。当然,无论具体应用场景是什么,异步共识组的1000倍提升这个底线总是可以轻松获得的。
论文演讲视频地址:
Monoxide: Scale out Blockchains with Asynchronous Consensus Zones
油管地址(官方,墙外): https://youtu.be/SVvJ5qbs2a0
优酷地址(搬运,墙内): http://t.cn/E63tMXP