作者:刘通
链接:https://www.zhihu.com/question/23345991/answer/53996060
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
大数据时代的数据分析任务比传统的数据分析任务要复杂,因为往往涉及的数据量巨大,比如要分析汇总某个大型零售商在全国的销售数据,查看某个搜索引擎的特定词条的访问日志… … 通常来讲,我们的笔记本电脑可以同时干很多事儿,比如听音乐,编辑Word文档,下载电影,这些都可以同时进行,为什么呢?因为这些程序任务所处理的数据量规模小。而对于大规模的数据处理任务来说,就不是一台电脑同时做许多任务了,而是许多电脑同时做一件任务的逻辑关系。假如你写了一个程序,然后让你的电脑来跑一个比较大的数据量(例如把百度百科上所有的词条分析一遍…),那么你的电脑需要很长很长的时间来做这件事…大多数情况下,数据还没跑完,你的电脑就被累死了(死机…)。那么怎么办?就有人考虑到了用许多台电脑来同时完成这个任务。这就引入了并行计算的概念。
许多电脑同时做一件复杂的任务,涉及很多问题:比如,这个任务首先要分解成许多子任务,然后这些小任务要在这些电脑上面去分配,然后这些电脑完成了任务之后反馈的结果还要汇总,同时还要考虑如果这些电脑的故障异常等问题怎么去解决…MapReduce就是这样的一个编程模型,一个复杂的任务按照这个抽象的模型去实现,就可以有效进行并行计算。
这个编程模型究竟是怎样的呢?他实际上说了这样一个事儿:已知手头上有许许多多(几万也许,甚至几十万…)PC机,每一个可能很挫,但是如果这些PC机团结协作起来,可以PK一个大型的工作站。现在有个复杂的任务,需要处理海量的数据。数据在哪里?数据实际上是随机地存储于这些个PC机器上的。我们不需要统一地把数据一起存到一个超大的硬盘上,数据可以直接散布在这些个PC上,这些PC自身不仅是许许多多个处理器,也是许许多多个小硬盘。
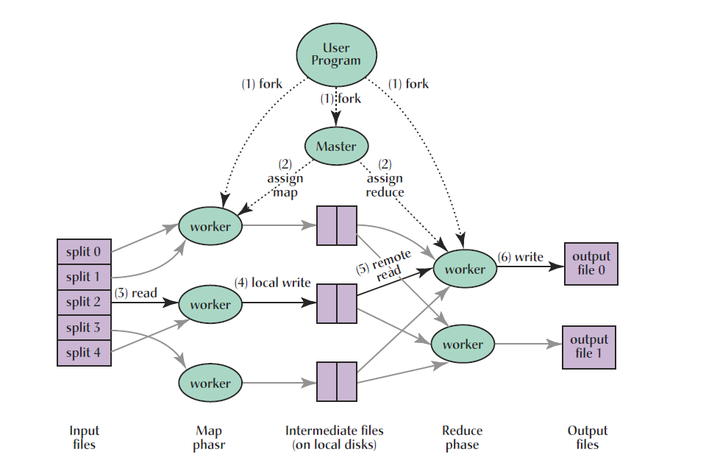
这些PC机器分为三类,第一类称为Master,Master是负责调度的,相当于工地的工头。第二类叫Worker,相当于干活儿的工人。Woker进一步分为两种,一种Worker叫Mapper,另一种叫Reducer。假设我们有一个巨大的数据集,里面有海量规模的元素,元素的个数为M,每个元素都需要进行同一个函数处理。于是Master将M分成许多小份,然后每一份分给一个Mapper来做,Mapper干完活儿(执行完函数),将自己那一份儿活儿的结果传给Reducer。Reducer之后统计汇总各个Mapper传过来的结果,得到最后的任务的答案。当然,这是最简单的表述,因为实际上Master的任务分配过程是很复杂的,会考虑任务时间?任务是否出错?网络通讯负担等等等等许多问题,这里不作赘述。
假设原始任务的Input个数为M,output个数为N。Mapper的个数为P,Reducer的个数为R。则有关系,M〉P〉N〉R。也就是说,一个Mapper要做M/P个input的处理任务,一个Reducer要做N/R个output的汇总工作。每个output有一个编号,假设为o1,o2,o3…oN。当一个Mapper处理完自己那一份儿input之后,每个input i被处理后转化为一个中间结果m。这个m很自然地会若干output (如:m1对应o1,o3,o5) 会有贡献。每个Reducer负责一个或多个o的汇总处理。假如某个Reducer负责o1,o2,o3,那么凡是对应到o1,o2,o3的被处理过的m都会传给这个Reducer做汇总处理。
举例来说,统计一系列文档中的词频。文档数量规模很大,有1000万个文档,英文单词的总数可能只有3000(常用的)。那么input M=10000000,output N=3000。于是,我们搞了10000个PC做Mapper,100个PC做Reducer。每个Mapper做1000个文档的词频统计,统计之后把凡是和同一个word相关的统计中间结果传给同一个Reducer做汇总。比如某个Reducer负责词表中前30个词的词频统计,遍历10000个PC,这10000个Mapper PC把各自处理后和词表中前30个词汇相关的中间结果都传给这个Reducer做最终的处理分析。至此MapReduce最核心的流程已经说明白了。
其实MapReduce讲的就是分而治之的程序处理理念,把一个复杂的任务划分为若干个简单的任务分别来做。另外,就是程序的调度问题,哪些任务给哪些Mapper来处理是一个着重考虑的问题。MapReduce的根本原则是信息处理的本地化,哪台PC持有相应要处理的数据,哪台PC就负责处理该部分的数据,这样做的意义在于可以减少网络通讯负担。最后补上一副经典的图来做最后的补充,毕竟,图表往往比文字更有说服力。